 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiMoTable: A Multi-scale Spreadsheet Benchmark with Meta Operations for Table Reasoning
Paper and Code
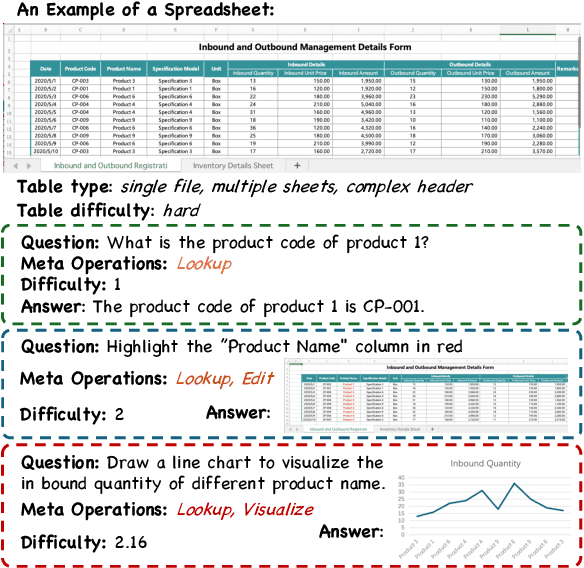
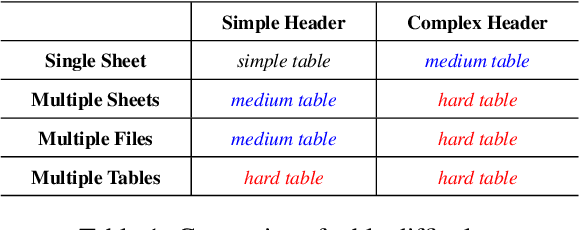

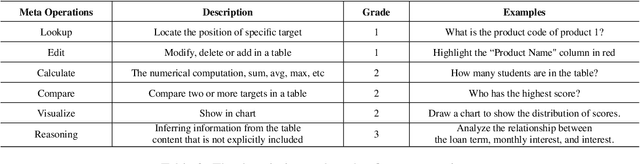
Extensive research has been conducted to explore the capability of Large Language Models (LLMs) for table reasoning and has significantly improved the performance on existing benchmarks. However, tables and user questions in real-world applications are more complex and diverse, presenting an unignorable gap compared to the existing benchmarks. To fill the gap, we propose a \textbf{M}ult\textbf{i}-scale spreadsheet benchmark with \textbf{M}eta \textbf{o}perations for \textbf{Table} reasoning, named as MiMoTable. Specifically, MiMoTable incorporates two key features. First, the tables in MiMoTable are all spreadsheets used in real-world scenarios, which cover seven domains and contain different types. Second, we define a new criterion with six categories of meta operations for measuring the difficulty of each question in MiMoTable, simultaneously as a new perspective for measuring the difficulty of the existing benchmarks. Experimental results show that Claude-3.5-Sonnet achieves the best performance with 77.4\% accuracy, indicating that there is still significant room to improve for LLMs on MiMoTable. Furthermore, we grade the difficulty of existing benchmarks according to our new criteria. Experiments have shown that the performance of LLMs decreases as the difficulty of benchmarks increases, thereby proving the effectiveness of our proposed new criterion.