 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoDTM: Towards 3D-Aware Egocentric Video-Language Pretraining
Mar 19, 2025
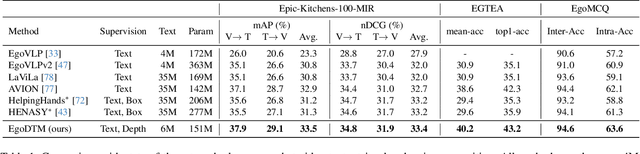
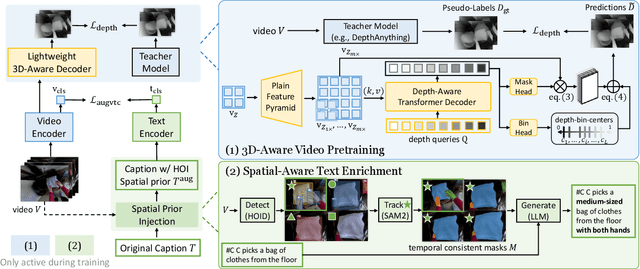

Egocentric video-language pretraining has significantly advanced video representation learning. Humans perceive and interact with a fully 3D world, developing spatial awareness that extends beyond text-based understanding. However, most previous works learn from 1D text or 2D visual cues, such as bounding boxes, which inherently lack 3D understanding. To bridge this gap, we introduce EgoDTM, an Egocentric Depth- and Text-aware Model, jointly trained through large-scale 3D-aware video pretraining and video-text contrastive learning. EgoDTM incorporates a lightweight 3D-aware decoder to efficiently learn 3D-awareness from pseudo depth maps generated by depth estimation models. To further facilitate 3D-aware video pretraining, we enrich the original brief captions with hand-object visual cues by organically combining several foundation models. Extensive experiments demonstrate EgoDTM's superior performance across diverse downstream tasks, highlighting its superior 3D-aware visual understanding. Our code will be released at https://github.com/xuboshen/EgoDTM.
QuadrupedGPT: Towards a Versatile Quadruped Agent in Open-ended Worlds
Jun 24, 2024
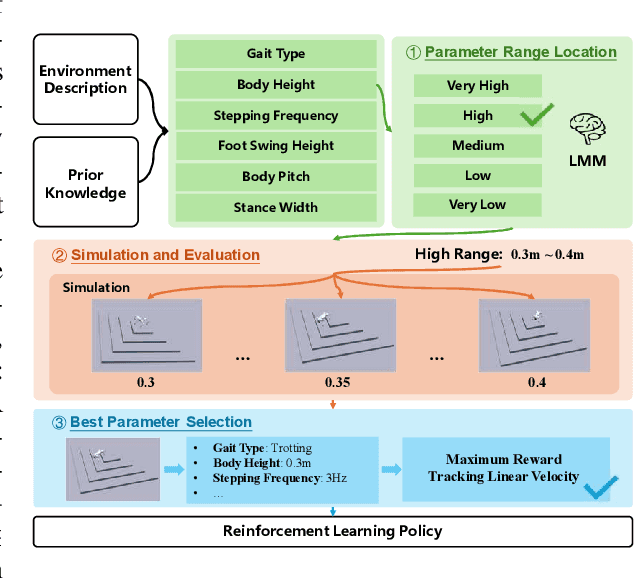


While pets offer companionship, their limited intelligence restricts advanced reasoning and autonomous interaction with humans. Considering this, we propose QuadrupedGPT, a versatile agent designed to master a broad range of complex tasks with agility comparable to that of a pet. To achieve this goal, the primary challenges include: i) effectively leveraging multimodal observations for decision-making; ii) mastering agile control of locomotion and path planning; iii) developing advanced cognition to execute long-term objectives. QuadrupedGPT processes human command and environmental contexts using a large multimodal model (LMM). Empowered by its extensive knowledge base, our agent autonomously assigns appropriate parameters for adaptive locomotion policies and guides the agent in planning a safe but efficient path towards the goal, utilizing semantic-aware terrain analysis. Moreover, QuadrupedGPT is equipped with problem-solving capabilities that enable it to decompose long-term goals into a sequence of executable subgoals through high-level reasoning. Extensive experiments across various benchmarks confirm that QuadrupedGPT can adeptly handle multiple tasks with intricate instructions, demonstrating a significant step towards the versatile quadruped agents in open-ended worlds. Our website and codes can be found at https://quadruped-hub.github.io/Quadruped-GPT/.
UBiSS: A Unified Framework for Bimodal Semantic Summarization of Videos
Jun 24, 2024



With the surge in the amount of video data, video summarization techniques, including visual-modal(VM) and textual-modal(TM) summarization, are attracting more and more attention. However, unimodal summarization inevitably loses the rich semantics of the video. In this paper, we focus on a more comprehensive video summarization task named Bimodal Semantic Summarization of Videos (BiSSV). Specifically, we first construct a large-scale dataset, BIDS, in (video, VM-Summary, TM-Summary) triplet format. Unlike traditional processing methods, our construction procedure contains a VM-Summary extraction algorithm aiming to preserve the most salient content within long videos. Based on BIDS, we propose a Unified framework UBiSS for the BiSSV task, which models the saliency information in the video and generates a TM-summary and VM-summary simultaneously. We further optimize our model with a list-wise ranking-based objective to improve its capacity to capture highlights. Lastly, we propose a metric, $NDCG_{MS}$, to provide a joint evaluation of the bimodal summary. Experiments show that our unified framework achieves better performance than multi-stage summarization pipelines. Code and data are available at https://github.com/MeiYutingg/UBiSS.
* Accepted by ACM International Conference on Multimedia Retrieval (ICMR'24)