 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Captioning at Will: Describing Images and Videos Guided by a Few Stylized Sentences
Paper and Code
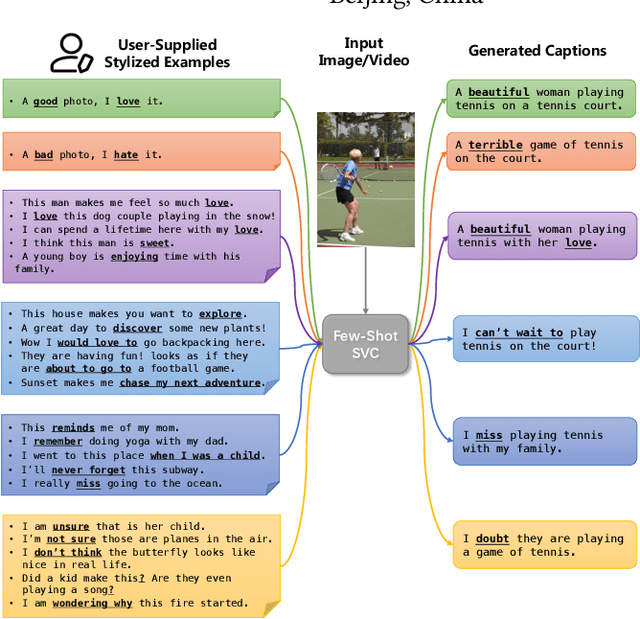
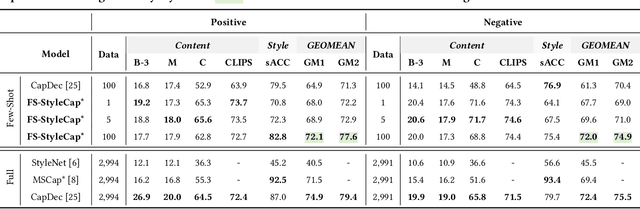
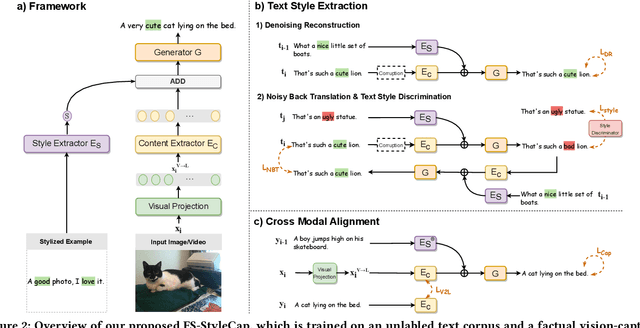
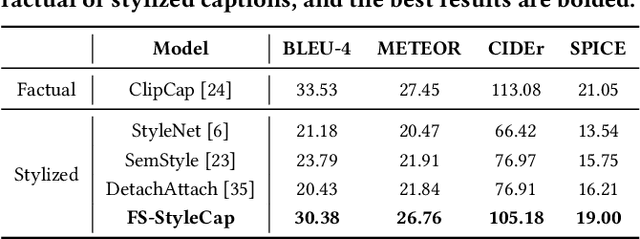
Stylized visual captioning aims to generate image or video descriptions with specific styles, making them more attractive and emotionally appropriate. One major challenge with this task is the lack of paired stylized captions for visual content, so most existing works focus on unsupervised methods that do not rely on parallel datasets. However, these approaches still require training with sufficient examples that have style labels, and the generated captions are limited to predefined styles. To address these limitations, we explore the problem of Few-Shot Stylized Visual Captioning, which aims to generate captions in any desired style, using only a few examples as guidance during inference, without requiring further training. We propose a framework called FS-StyleCap for this task, which utilizes a conditional encoder-decoder language model and a visual projection module. Our two-step training scheme proceeds as follows: first, we train a style extractor to generate style representations on an unlabeled text-only corpus. Then, we freeze the extractor and enable our decoder to generate stylized descriptions based on the extracted style vector and projected visual content vectors. During inference, our model can generate desired stylized captions by deriving the style representation from user-supplied examples. Our automatic evaluation results for few-shot sentimental visual captioning outperform state-of-the-art approaches and are comparable to models that are fully trained on labeled style corpora. Human evaluations further confirm our model s ability to handle multiple styles.