 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUXBench: Benchmarking User Experience in AI Assistants
Jun 09, 2026As AI assistants serve millions of users daily, evaluating user experience (UX) beyond general model capability has become increasingly important. We present UXBench, the first user-centric benchmark grounded in real user feedback signals for evaluating preference alignment and dialogue generation. The benchmark consists of three interconnected tasks, UX Judge, UX Eval, and UX Recovery, with 7,400 test instances extracted from over 70K interaction logs of a mainstream Chinese AI assistant. The dataset closely reflects real user distributions, covering 8 scenarios, 83 domains, and diverse failure patterns that pose severe challenges. Extensive experiments on 26 frontier language models provide novel insights into how well models perceive user experience and how improvements in model capability contribute to better dialogue engagement. Through comprehensive analysis of model behavior and performance gaps, we show that user feedback prediction is a learnable capability, where a reward model trained from in-the-wild feedback signals can achieve well-calibrated accuracy. We further document the systematic biases of LLM-as-a-judge evaluation protocols and compare typical response strategies that directly affect user experience. UXBench establishes a new evaluation landscape and calls for greater attention to tailored UX optimization, contributing to a user-centric scaling law that shapes the success of AI assistants.
Edit As You Wish: Video Description Editing with Multi-grained Commands
May 15, 2023Automatically narrating a video with natural language can assist people in grasping and managing massive videos on the Internet. From the perspective of video uploaders, they may have varied preferences for writing the desired video description to attract more potential followers, e.g. catching customers' attention for product videos. The Controllable Video Captioning task is therefore proposed to generate a description conditioned on the user demand and video content. However, existing works suffer from two shortcomings: 1) the control signal is fixed and can only express single-grained control; 2) the video description can not be further edited to meet dynamic user demands. In this paper, we propose a novel Video Description Editing (VDEdit) task to automatically revise an existing video description guided by flexible user requests. Inspired by human writing-revision habits, we design the user command as a {operation, position, attribute} triplet to cover multi-grained use requirements, which can express coarse-grained control (e.g. expand the description) as well as fine-grained control (e.g. add specified details in specified position) in a unified format. To facilitate the VDEdit task, we first automatically construct a large-scale benchmark dataset namely VATEX-EDIT in the open domain describing diverse human activities. Considering the real-life application scenario, we further manually collect an e-commerce benchmark dataset called EMMAD-EDIT. We propose a unified framework to convert the {operation, position, attribute} triplet into a textual control sequence to handle multi-grained editing commands. For VDEdit evaluation, we adopt comprehensive metrics to measure three aspects of model performance, including caption quality, caption-command consistency, and caption-video alignment.
CapOnImage: Context-driven Dense-Captioning on Image
Apr 27, 2022
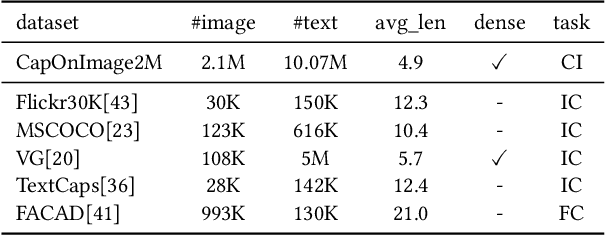
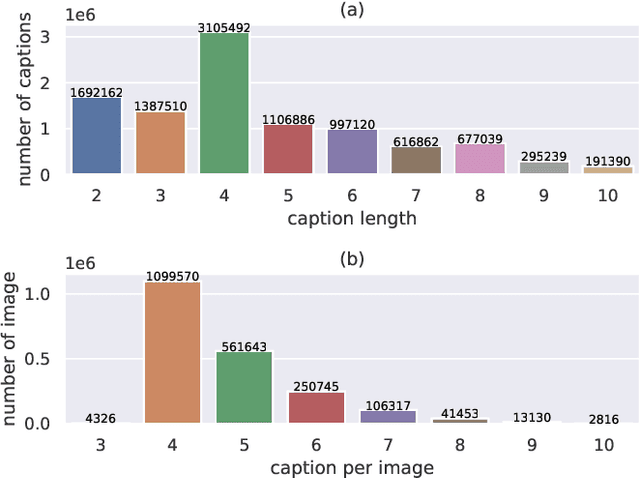
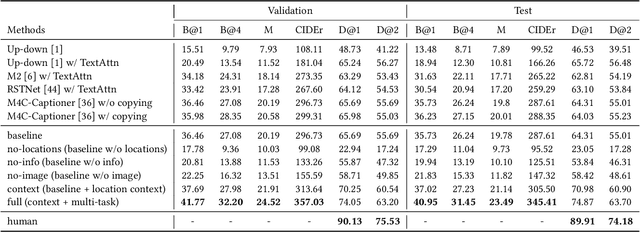
Existing image captioning systems are dedicated to generating narrative captions for images, which are spatially detached from the image in presentation. However, texts can also be used as decorations on the image to highlight the key points and increase the attractiveness of images. In this work, we introduce a new task called captioning on image (CapOnImage), which aims to generate dense captions at different locations of the image based on contextual information. To fully exploit the surrounding visual context to generate the most suitable caption for each location, we propose a multi-modal pre-training model with multi-level pre-training tasks that progressively learn the correspondence between texts and image locations from easy to difficult. Since the model may generate redundant captions for nearby locations, we further enhance the location embedding with neighbor locations as context. For this new task, we also introduce a large-scale benchmark called CapOnImage2M, which contains 2.1 million product images, each with an average of 4.8 spatially localized captions. Compared with other image captioning model variants, our model achieves the best results in both captioning accuracy and diversity aspects. We will make code and datasets public to facilitate future research.
MultiHead MultiModal Deep Interest Recommendation Network
Oct 19, 2021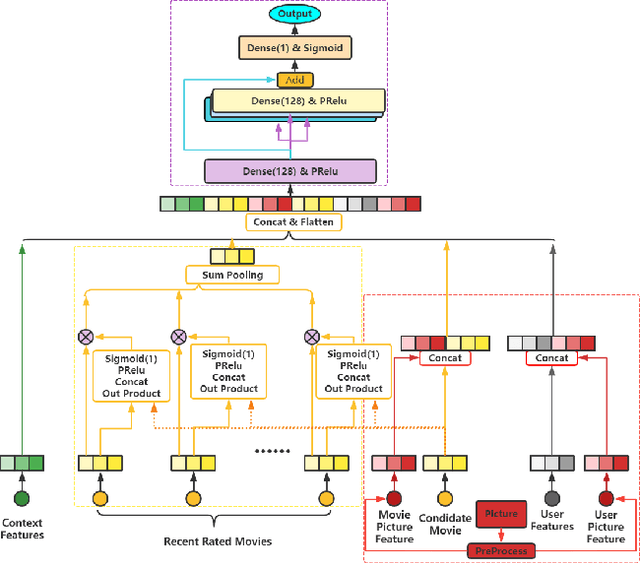
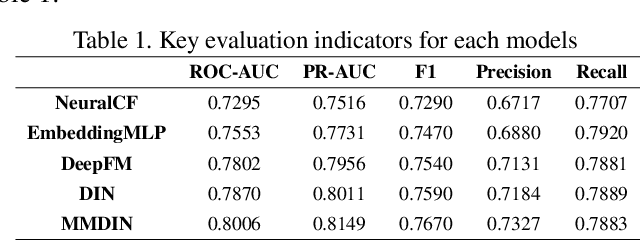
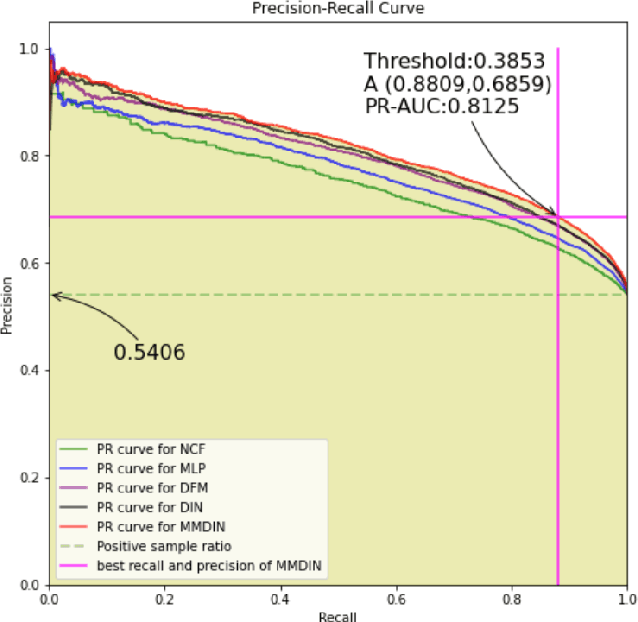
With the development of information technology, human beings are constantly producing a large amount of information at all times. How to obtain the information that users are interested in from the large amount of information has become an issue of great concern to users and even business managers. In order to solve this problem, from traditional machine learning to deep learning recommendation systems, researchers continue to improve optimization models and explore solutions. Because researchers have optimized more on the recommendation model network structure, they have less research on enriching recommendation model features, and there is still room for in-depth recommendation model optimization. Based on the DIN\cite{Authors01} model, this paper adds multi-head and multi-modal modules, which enriches the feature sets that the model can use, and at the same time strengthens the cross-combination and fitting capabilities of the model. Experiments show that the multi-head multi-modal DIN improves the recommendation prediction effect, and outperforms current state-of-the-art methods on various comprehensive indicators.