 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapOnImage: Context-driven Dense-Captioning on Image
Paper and Code
Apr 27, 2022
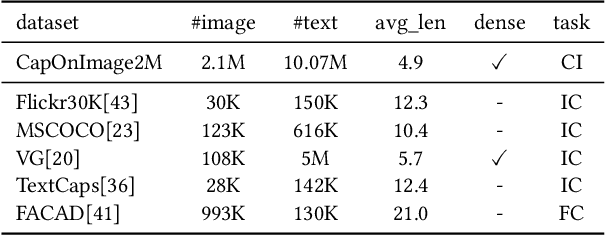
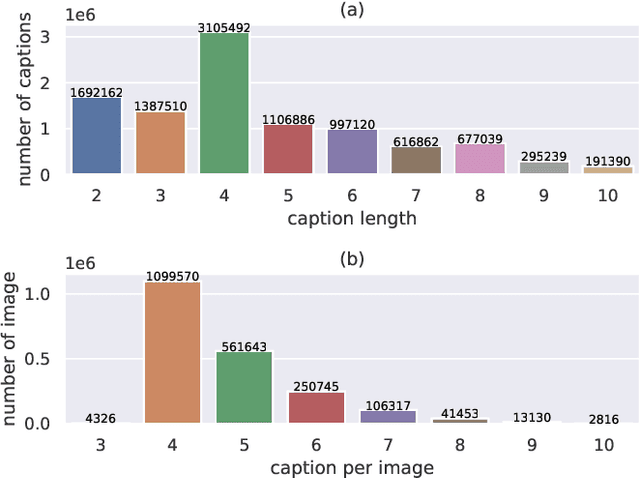
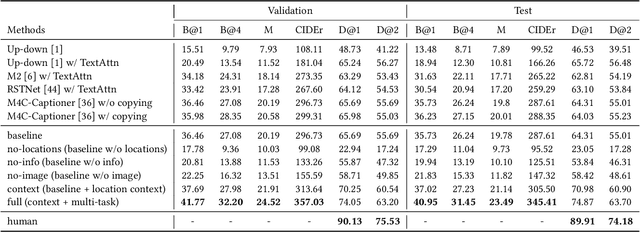
Existing image captioning systems are dedicated to generating narrative captions for images, which are spatially detached from the image in presentation. However, texts can also be used as decorations on the image to highlight the key points and increase the attractiveness of images. In this work, we introduce a new task called captioning on image (CapOnImage), which aims to generate dense captions at different locations of the image based on contextual information. To fully exploit the surrounding visual context to generate the most suitable caption for each location, we propose a multi-modal pre-training model with multi-level pre-training tasks that progressively learn the correspondence between texts and image locations from easy to difficult. Since the model may generate redundant captions for nearby locations, we further enhance the location embedding with neighbor locations as context. For this new task, we also introduce a large-scale benchmark called CapOnImage2M, which contains 2.1 million product images, each with an average of 4.8 spatially localized captions. Compared with other image captioning model variants, our model achieves the best results in both captioning accuracy and diversity aspects. We will make code and datasets public to facilitate future research.