 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Stronger Mixture of Low-Rank Experts for Fine-Tuning Foundation Models
Feb 20, 2025In order to streamline the fine-tuning of foundation models, Low-Rank Adapters (LoRAs) have been substantially adopted across various fields, including instruction tuning and domain adaptation. The underlying concept of LoRA involves decomposing a full-rank matrix into the product of two lower-rank matrices, which reduces storage consumption and accelerates the training process. Furthermore, to address the limited expressive capacity of LoRA, the Mixture-of-Expert (MoE) has been introduced for incorporating multiple LoRA adapters. The integration of LoRA experts leads to a visible improvement across several downstream scenes. However, the mixture of LoRAs (MoE-LoRA) still exhibits its low robustness during tuning and inferring. Inspired by the Riemannian Preconditioners which train LoRA as a sub-space projector, we propose a new training strategy for MoE-LoRA, to stabilize and boost its feature learning procedure by multi-space projections. Examinations on SGD and AdamW optimizers demonstrate the effectiveness of our methodology. Source code is available at https://github.com/THUDM/MoELoRA_Riemannian.
Pruning All-Rounder: Rethinking and Improving Inference Efficiency for Large Vision Language Models
Dec 09, 2024



Although Large Vision-Language Models (LVLMs) have achieved impressive results, their high computational cost poses a significant barrier to wider application. To enhance inference efficiency, most existing approaches depend on parameter-dependent or token-dependent strategies to reduce computational demands. However, these methods typically require complex training processes and struggle to consistently select the most relevant tokens. In this paper, we systematically analyze the above challenges and provide a series of valuable insights for inference acceleration. Based on these findings, we propose a novel framework, the Pruning All-Rounder (PAR). Different from previous works, PAR develops a meta-router to adaptively organize pruning flows across both tokens and layers. With a self-supervised learning manner, our method achieves a superior balance between performance and efficiency. Notably, PAR is highly flexible, offering multiple pruning versions to address a range of pruning scenarios. The code for this work will be made publicly available.
Visual Prompt Selection for In-Context Learning Segmentation
Jul 14, 2024As a fundamental and extensively studied task in computer vision, image segmentation aims to locate and identify different semantic concepts at the pixel level. Recently, inspired by In-Context Learning (ICL), several generalist segmentation frameworks have been proposed, providing a promising paradigm for segmenting specific objects. However, existing works mostly ignore the value of visual prompts or simply apply similarity sorting to select contextual examples. In this paper, we focus on rethinking and improving the example selection strategy. By comprehensive comparisons, we first demonstrate that ICL-based segmentation models are sensitive to different contexts. Furthermore, empirical evidence indicates that the diversity of contextual prompts plays a crucial role in guiding segmentation. Based on the above insights, we propose a new stepwise context search method. Different from previous works, we construct a small yet rich candidate pool and adaptively search the well-matched contexts. More importantly, this method effectively reduces the annotation cost by compacting the search space. Extensive experiments show that our method is an effective strategy for selecting examples and enhancing segmentation performance.
S3C: Semi-Supervised VQA Natural Language Explanation via Self-Critical Learning
Sep 05, 2023VQA Natural Language Explanation (VQA-NLE) task aims to explain the decision-making process of VQA models in natural language. Unlike traditional attention or gradient analysis, free-text rationales can be easier to understand and gain users' trust. Existing methods mostly use post-hoc or self-rationalization models to obtain a plausible explanation. However, these frameworks are bottlenecked by the following challenges: 1) the reasoning process cannot be faithfully responded to and suffer from the problem of logical inconsistency. 2) Human-annotated explanations are expensive and time-consuming to collect. In this paper, we propose a new Semi-Supervised VQA-NLE via Self-Critical Learning (S3C), which evaluates the candidate explanations by answering rewards to improve the logical consistency between answers and rationales. With a semi-supervised learning framework, the S3C can benefit from a tremendous amount of samples without human-annotated explanations. A large number of automatic measures and human evaluations all show the effectiveness of our method. Meanwhile, the framework achieves a new state-of-the-art performance on the two VQA-NLE datasets.
Dual-Level Decoupled Transformer for Video Captioning
May 06, 2022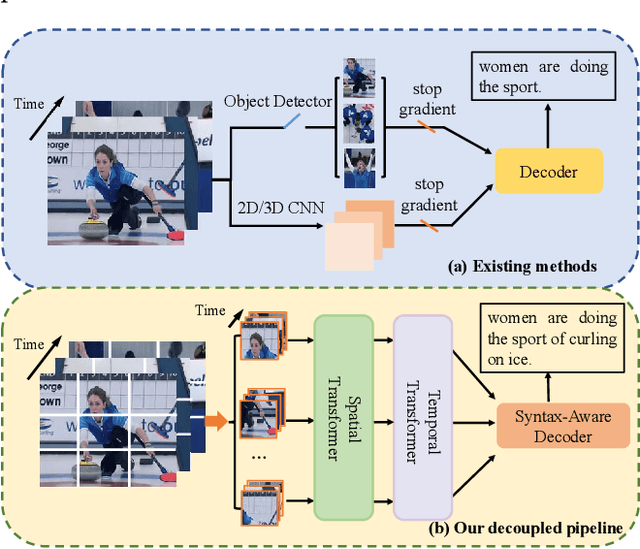
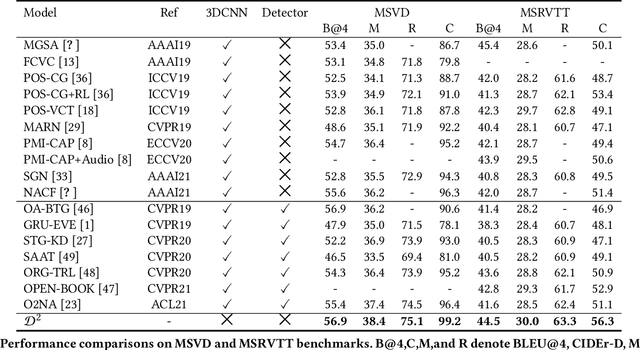
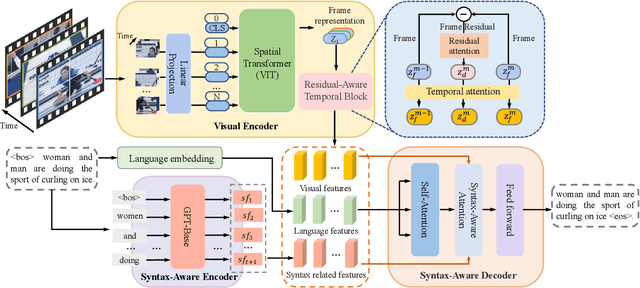
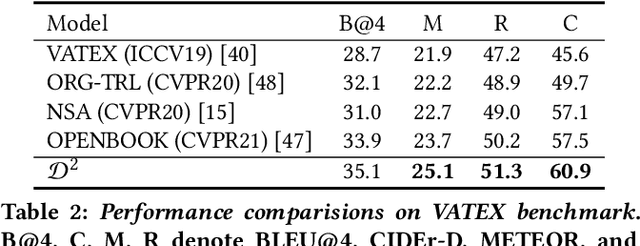
Video captioning aims to understand the spatio-temporal semantic concept of the video and generate descriptive sentences. The de-facto approach to this task dictates a text generator to learn from \textit{offline-extracted} motion or appearance features from \textit{pre-trained} vision models. However, these methods may suffer from the so-called \textbf{\textit{"couple"}} drawbacks on both \textit{video spatio-temporal representation} and \textit{sentence generation}. For the former, \textbf{\textit{"couple"}} means learning spatio-temporal representation in a single model(3DCNN), resulting the problems named \emph{disconnection in task/pre-train domain} and \emph{hard for end-to-end training}. As for the latter, \textbf{\textit{"couple"}} means treating the generation of visual semantic and syntax-related words equally. To this end, we present $\mathcal{D}^{2}$ - a dual-level decoupled transformer pipeline to solve the above drawbacks: \emph{(i)} for video spatio-temporal representation, we decouple the process of it into "first-spatial-then-temporal" paradigm, releasing the potential of using dedicated model(\textit{e.g.} image-text pre-training) to connect the pre-training and downstream tasks, and makes the entire model end-to-end trainable. \emph{(ii)} for sentence generation, we propose \emph{Syntax-Aware Decoder} to dynamically measure the contribution of visual semantic and syntax-related words. Extensive experiments on three widely-used benchmarks (MSVD, MSR-VTT and VATEX) have shown great potential of the proposed $\mathcal{D}^{2}$ and surpassed the previous methods by a large margin in the task of video captioning.
Proposal-free One-stage Referring Expression via Grid-Word Cross-Attention
May 05, 2021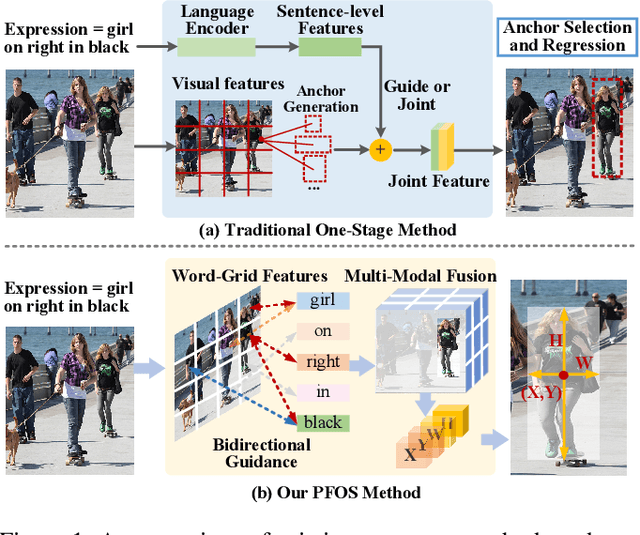
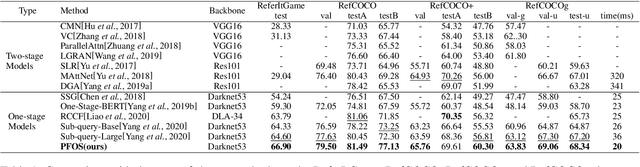
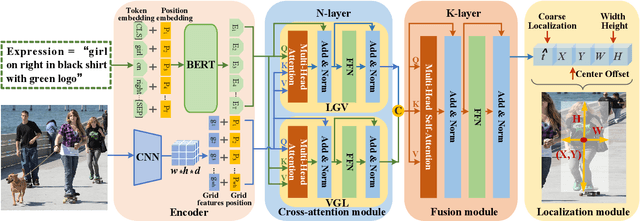
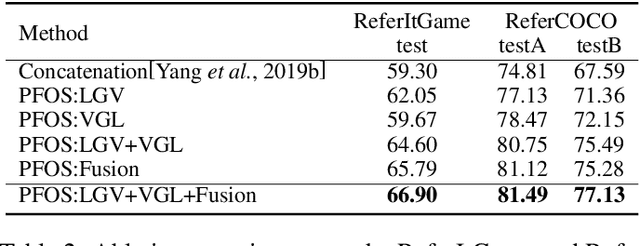
Referring Expression Comprehension (REC) has become one of the most important tasks in visual reasoning, since it is an essential step for many vision-and-language tasks such as visual question answering. However, it has not been widely used in many downstream tasks because it suffers 1) two-stage methods exist heavy computation cost and inevitable error accumulation, and 2) one-stage methods have to depend on lots of hyper-parameters (such as anchors) to generate bounding box. In this paper, we present a proposal-free one-stage (PFOS) model that is able to regress the region-of-interest from the image, based on a textual query, in an end-to-end manner. Instead of using the dominant anchor proposal fashion, we directly take the dense-grid of an image as input for a cross-attention transformer that learns grid-word correspondences. The final bounding box is predicted directly from the image without the time-consuming anchor selection process that previous methods suffer. Our model achieves the state-of-the-art performance on four referring expression datasets with higher efficiency, comparing to previous best one-stage and two-stage methods.