 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Plug-and-Play Method for Rare Human-Object Interactions Detection by Bridging Domain Gap
Paper and Code
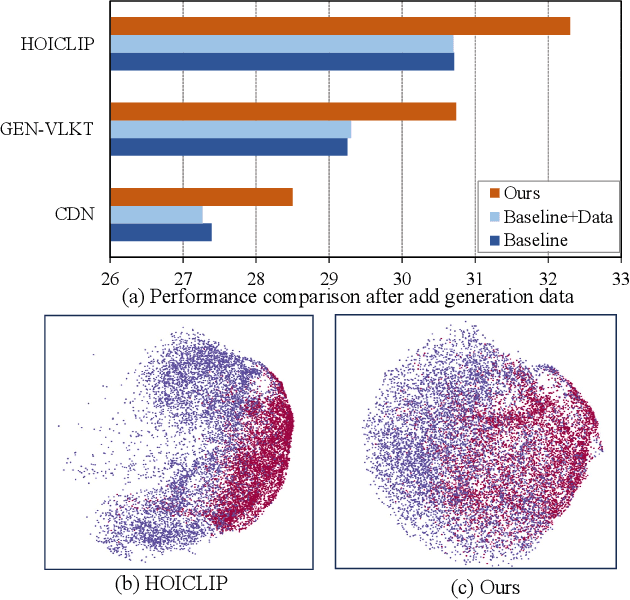
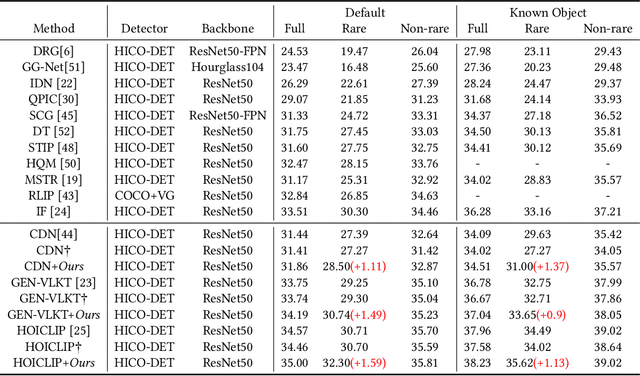
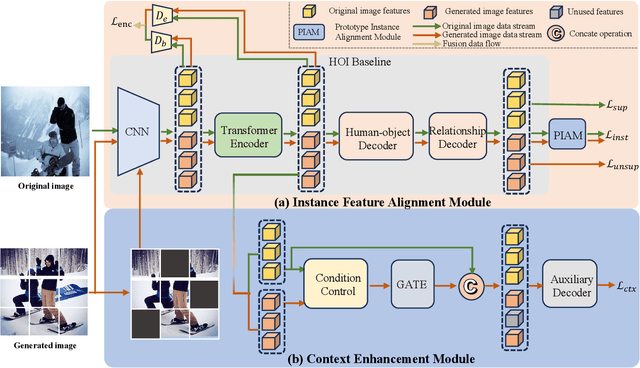
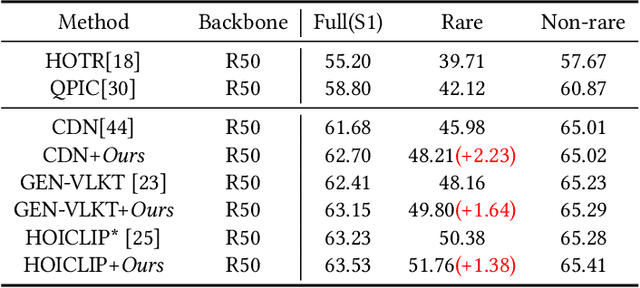
Human-object interactions (HOI) detection aims at capturing human-object pairs in images and corresponding actions. It is an important step toward high-level visual reasoning and scene understanding. However, due to the natural bias from the real world, existing methods mostly struggle with rare human-object pairs and lead to sub-optimal results. Recently, with the development of the generative model, a straightforward approach is to construct a more balanced dataset based on a group of supplementary samples. Unfortunately, there is a significant domain gap between the generated data and the original data, and simply merging the generated images into the original dataset cannot significantly boost the performance. To alleviate the above problem, we present a novel model-agnostic framework called \textbf{C}ontext-\textbf{E}nhanced \textbf{F}eature \textbf{A}lignment (CEFA) module, which can effectively align the generated data with the original data at the feature level and bridge the domain gap. Specifically, CEFA consists of a feature alignment module and a context enhancement module. On one hand, considering the crucial role of human-object pairs information in HOI tasks, the feature alignment module aligns the human-object pairs by aggregating instance information. On the other hand, to mitigate the issue of losing important context information caused by the traditional discriminator-style alignment method, we employ a context-enhanced image reconstruction module to improve the model's learning ability of contextual cues. Extensive experiments have shown that our method can serve as a plug-and-play module to improve the detection performance of HOI models on rare categories\footnote{https://github.com/LijunZhang01/CEFA}.