 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolutionary Profiles for Protein Fitness Prediction
Oct 08, 2025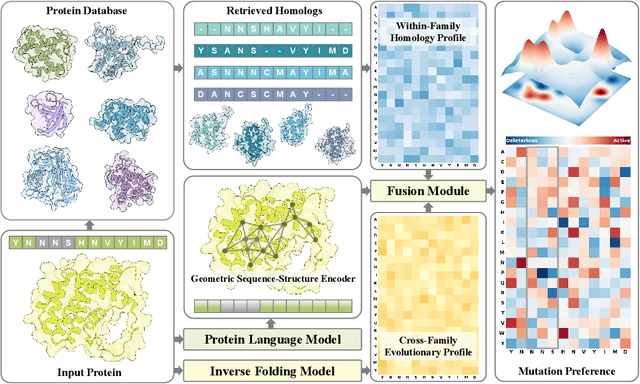
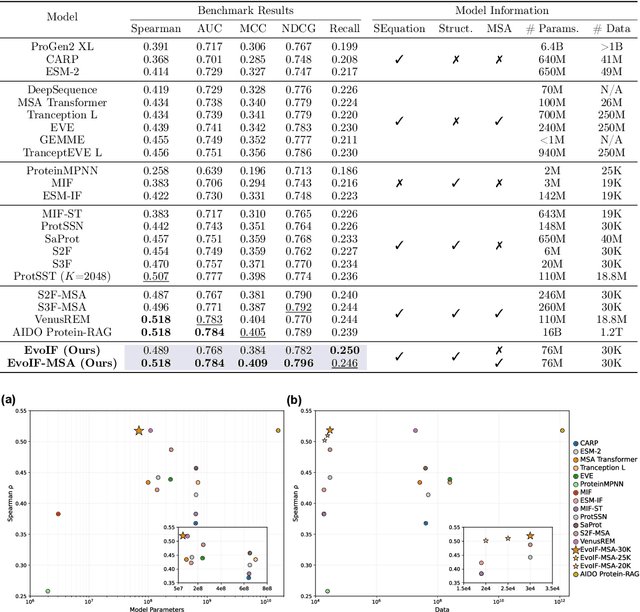
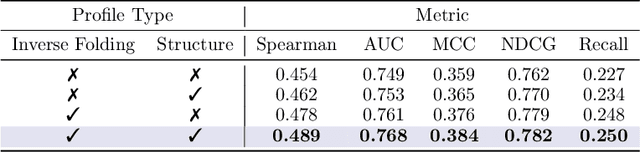
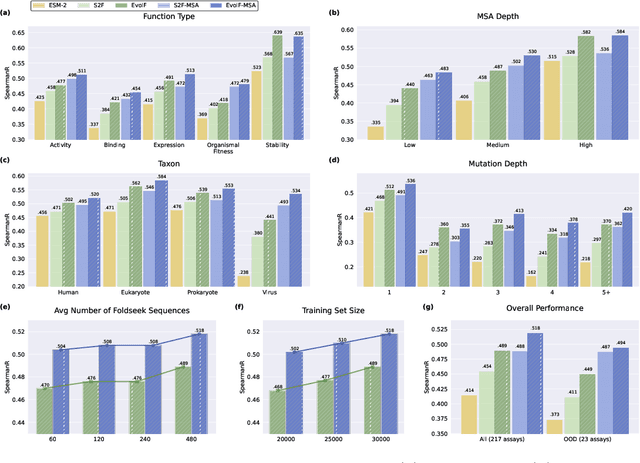
Predicting the fitness impact of mutations is central to protein engineering but constrained by limited assays relative to the size of sequence space. Protein language models (pLMs) trained with masked language modeling (MLM) exhibit strong zero-shot fitness prediction; we provide a unifying view by interpreting natural evolution as implicit reward maximization and MLM as inverse reinforcement learning (IRL), in which extant sequences act as expert demonstrations and pLM log-odds serve as fitness estimates. Building on this perspective, we introduce EvoIF, a lightweight model that integrates two complementary sources of evolutionary signal: (i) within-family profiles from retrieved homologs and (ii) cross-family structural-evolutionary constraints distilled from inverse folding logits. EvoIF fuses sequence-structure representations with these profiles via a compact transition block, yielding calibrated probabilities for log-odds scoring. On ProteinGym (217 mutational assays; >2.5M mutants), EvoIF and its MSA-enabled variant achieve state-of-the-art or competitive performance while using only 0.15% of the training data and fewer parameters than recent large models. Ablations confirm that within-family and cross-family profiles are complementary, improving robustness across function types, MSA depths, taxa, and mutation depths. The codes will be made publicly available at https://github.com/aim-uofa/EvoIF.
Revisiting Convolution Architecture in the Realm of DNA Foundation Models
Feb 25, 2025In recent years, a variety of methods based on Transformer and state space model (SSM) architectures have been proposed, advancing foundational DNA language models. However, there is a lack of comparison between these recent approaches and the classical architecture convolutional networks (CNNs) on foundation model benchmarks. This raises the question: are CNNs truly being surpassed by these recent approaches based on transformer and SSM architectures? In this paper, we develop a simple but well-designed CNN-based method termed ConvNova. ConvNova identifies and proposes three effective designs: 1) dilated convolutions, 2) gated convolutions, and 3) a dual-branch framework for gating mechanisms. Through extensive empirical experiments, we demonstrate that ConvNova significantly outperforms recent methods on more than half of the tasks across several foundation model benchmarks. For example, in histone-related tasks, ConvNova exceeds the second-best method by an average of 5.8%, while generally utilizing fewer parameters and enabling faster computation. In addition, the experiments observed findings that may be related to biological characteristics. This indicates that CNNs are still a strong competitor compared to Transformers and SSMs. We anticipate that this work will spark renewed interest in CNN-based methods for DNA foundation models.
Boltzmann-Aligned Inverse Folding Model as a Predictor of Mutational Effects on Protein-Protein Interactions
Oct 12, 2024



Predicting the change in binding free energy ($\Delta \Delta G$) is crucial for understanding and modulating protein-protein interactions, which are critical in drug design. Due to the scarcity of experimental $\Delta \Delta G$ data, existing methods focus on pre-training, while neglecting the importance of alignment. In this work, we propose the Boltzmann Alignment technique to transfer knowledge from pre-trained inverse folding models to $\Delta \Delta G$ prediction. We begin by analyzing the thermodynamic definition of $\Delta \Delta G$ and introducing the Boltzmann distribution to connect energy with protein conformational distribution. However, the protein conformational distribution is intractable; therefore, we employ Bayes' theorem to circumvent direct estimation and instead utilize the log-likelihood provided by protein inverse folding models for $\Delta \Delta G$ estimation. Compared to previous inverse folding-based methods, our method explicitly accounts for the unbound state of protein complex in the $\Delta \Delta G$ thermodynamic cycle, introducing a physical inductive bias and achieving both supervised and unsupervised state-of-the-art (SoTA) performance. Experimental results on SKEMPI v2 indicate that our method achieves Spearman coefficients of 0.3201 (unsupervised) and 0.5134 (supervised), significantly surpassing the previously reported SoTA values of 0.2632 and 0.4324, respectively. Futhermore, we demonstrate the capability of our method on binding energy prediction, protein-protein docking and antibody optimization tasks.
Floating Anchor Diffusion Model for Multi-motif Scaffolding
Jun 05, 2024



Motif scaffolding seeks to design scaffold structures for constructing proteins with functions derived from the desired motif, which is crucial for the design of vaccines and enzymes. Previous works approach the problem by inpainting or conditional generation. Both of them can only scaffold motifs with fixed positions, and the conditional generation cannot guarantee the presence of motifs. However, prior knowledge of the relative motif positions in a protein is not readily available, and constructing a protein with multiple functions in one protein is more general and significant because of the synergies between functions. We propose a Floating Anchor Diffusion (FADiff) model. FADiff allows motifs to float rigidly and independently in the process of diffusion, which guarantees the presence of motifs and automates the motif position design. Our experiments demonstrate the efficacy of FADiff with high success rates and designable novel scaffolds. To the best of our knowledge, FADiff is the first work to tackle the challenge of scaffolding multiple motifs without relying on the expertise of relative motif positions in the protein. Code is available at https://github.com/aim-uofa/FADiff.
Generative Active Learning for Long-tailed Instance Segmentation
Jun 04, 2024Recently, large-scale language-image generative models have gained widespread attention and many works have utilized generated data from these models to further enhance the performance of perception tasks. However, not all generated data can positively impact downstream models, and these methods do not thoroughly explore how to better select and utilize generated data. On the other hand, there is still a lack of research oriented towards active learning on generated data. In this paper, we explore how to perform active learning specifically for generated data in the long-tailed instance segmentation task. Subsequently, we propose BSGAL, a new algorithm that online estimates the contribution of the generated data based on gradient cache. BSGAL can handle unlimited generated data and complex downstream segmentation tasks effectively. Experiments show that BSGAL outperforms the baseline approach and effectually improves the performance of long-tailed segmentation. Our code can be found at https://github.com/aim-uofa/DiverGen.
De novo protein design using geometric vector field networks
Oct 18, 2023



Innovations like protein diffusion have enabled significant progress in de novo protein design, which is a vital topic in life science. These methods typically depend on protein structure encoders to model residue backbone frames, where atoms do not exist. Most prior encoders rely on atom-wise features, such as angles and distances between atoms, which are not available in this context. Thus far, only several simple encoders, such as IPA, have been proposed for this scenario, exposing the frame modeling as a bottleneck. In this work, we proffer the Vector Field Network (VFN), which enables network layers to perform learnable vector computations between coordinates of frame-anchored virtual atoms, thus achieving a higher capability for modeling frames. The vector computation operates in a manner similar to a linear layer, with each input channel receiving 3D virtual atom coordinates instead of scalar values. The multiple feature vectors output by the vector computation are then used to update the residue representations and virtual atom coordinates via attention aggregation. Remarkably, VFN also excels in modeling both frames and atoms, as the real atoms can be treated as the virtual atoms for modeling, positioning VFN as a potential universal encoder. In protein diffusion (frame modeling), VFN exhibits an impressive performance advantage over IPA, excelling in terms of both designability (67.04% vs. 53.58%) and diversity (66.54% vs. 51.98%). In inverse folding (frame and atom modeling), VFN outperforms the previous SoTA model, PiFold (54.7% vs. 51.66%), on sequence recovery rate. We also propose a method of equipping VFN with the ESM model, which significantly surpasses the previous ESM-based SoTA (62.67% vs. 55.65%), LM-Design, by a substantial margin.
SegPrompt: Boosting Open-world Segmentation via Category-level Prompt Learning
Aug 12, 2023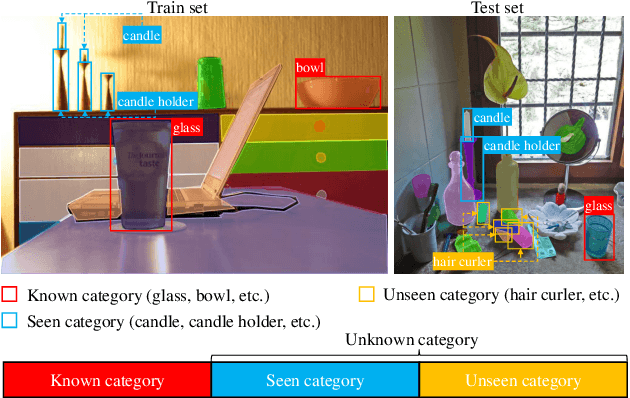



Current closed-set instance segmentation models rely on pre-defined class labels for each mask during training and evaluation, largely limiting their ability to detect novel objects. Open-world instance segmentation (OWIS) models address this challenge by detecting unknown objects in a class-agnostic manner. However, previous OWIS approaches completely erase category information during training to keep the model's ability to generalize to unknown objects. In this work, we propose a novel training mechanism termed SegPrompt that uses category information to improve the model's class-agnostic segmentation ability for both known and unknown categories. In addition, the previous OWIS training setting exposes the unknown classes to the training set and brings information leakage, which is unreasonable in the real world. Therefore, we provide a new open-world benchmark closer to a real-world scenario by dividing the dataset classes into known-seen-unseen parts. For the first time, we focus on the model's ability to discover objects that never appear in the training set images. Experiments show that SegPrompt can improve the overall and unseen detection performance by 5.6% and 6.1% in AR on our new benchmark without affecting the inference efficiency. We further demonstrate the effectiveness of our method on existing cross-dataset transfer and strongly supervised settings, leading to 5.5% and 12.3% relative improvement.
CTVIS: Consistent Training for Online Video Instance Segmentation
Jul 24, 2023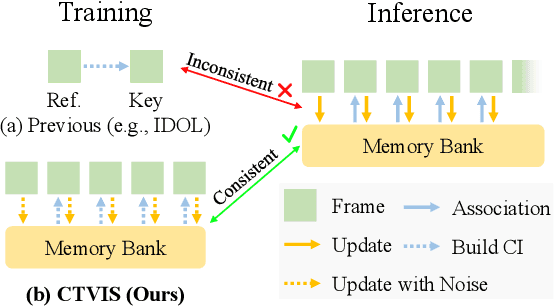
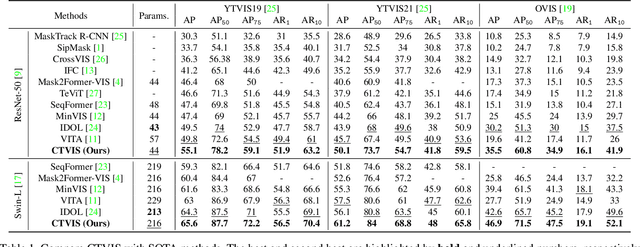
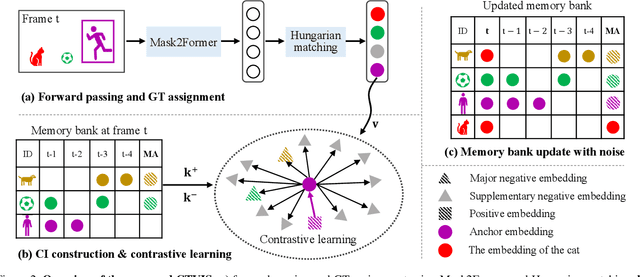
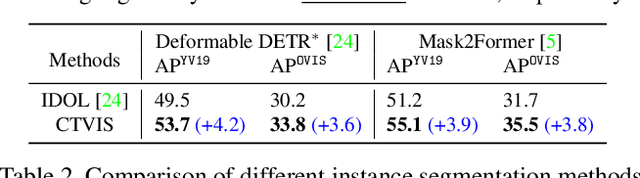
The discrimination of instance embeddings plays a vital role in associating instances across time for online video instance segmentation (VIS). Instance embedding learning is directly supervised by the contrastive loss computed upon the contrastive items (CIs), which are sets of anchor/positive/negative embeddings. Recent online VIS methods leverage CIs sourced from one reference frame only, which we argue is insufficient for learning highly discriminative embeddings. Intuitively, a possible strategy to enhance CIs is replicating the inference phase during training. To this end, we propose a simple yet effective training strategy, called Consistent Training for Online VIS (CTVIS), which devotes to aligning the training and inference pipelines in terms of building CIs. Specifically, CTVIS constructs CIs by referring inference the momentum-averaged embedding and the memory bank storage mechanisms, and adding noise to the relevant embeddings. Such an extension allows a reliable comparison between embeddings of current instances and the stable representations of historical instances, thereby conferring an advantage in modeling VIS challenges such as occlusion, re-identification, and deformation. Empirically, CTVIS outstrips the SOTA VIS models by up to +5.0 points on three VIS benchmarks, including YTVIS19 (55.1% AP), YTVIS21 (50.1% AP) and OVIS (35.5% AP). Furthermore, we find that pseudo-videos transformed from images can train robust models surpassing fully-supervised ones.
Poseur: Direct Human Pose Regression with Transformers
Jan 19, 2022



We propose a direct, regression-based approach to 2D human pose estimation from single images. We formulate the problem as a sequence prediction task, which we solve using a Transformer network. This network directly learns a regression mapping from images to the keypoint coordinates, without resorting to intermediate representations such as heatmaps. This approach avoids much of the complexity associated with heatmap-based approaches. To overcome the feature misalignment issues of previous regression-based methods, we propose an attention mechanism that adaptively attends to the features that are most relevant to the target keypoints, considerably improving the accuracy. Importantly, our framework is end-to-end differentiable, and naturally learns to exploit the dependencies between keypoints. Experiments on MS-COCO and MPII, two predominant pose-estimation datasets, demonstrate that our method significantly improves upon the state-of-the-art in regression-based pose estimation. More notably, ours is the first regression-based approach to perform favorably compared to the best heatmap-based pose estimation methods.
FCPose: Fully Convolutional Multi-Person Pose Estimation with Dynamic Instance-Aware Convolutions
May 29, 2021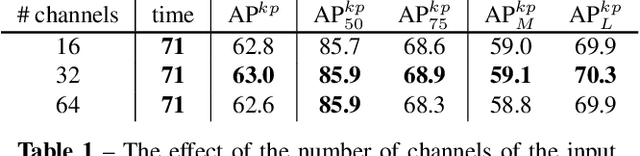

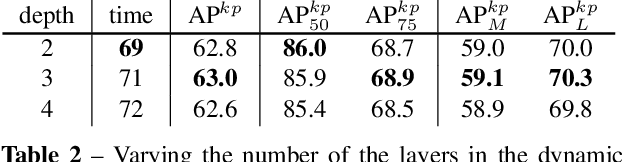
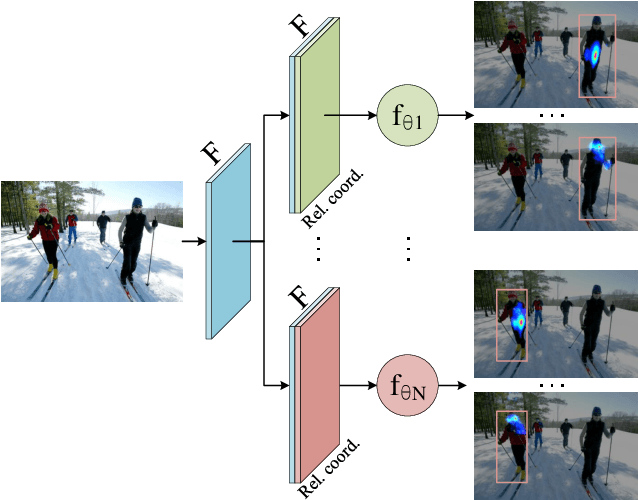
We propose a fully convolutional multi-person pose estimation framework using dynamic instance-aware convolutions, termed FCPose. Different from existing methods, which often require ROI (Region of Interest) operations and/or grouping post-processing, FCPose eliminates the ROIs and grouping post-processing with dynamic instance-aware keypoint estimation heads. The dynamic keypoint heads are conditioned on each instance (person), and can encode the instance concept in the dynamically-generated weights of their filters. Moreover, with the strong representation capacity of dynamic convolutions, the keypoint heads in FCPose are designed to be very compact, resulting in fast inference and making FCPose have almost constant inference time regardless of the number of persons in the image. For example, on the COCO dataset, a real-time version of FCPose using the DLA-34 backbone infers about 4.5x faster than Mask R-CNN (ResNet-101) (41.67 FPS vs. 9.26FPS) while achieving improved performance. FCPose also offers better speed/accuracy trade-off than other state-of-the-art methods. Our experiment results show that FCPose is a simple yet effective multi-person pose estimation framework. Code is available at: https://git.io/AdelaiDet