 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwift4D:Adaptive divide-and-conquer Gaussian Splatting for compact and efficient reconstruction of dynamic scene
Mar 16, 2025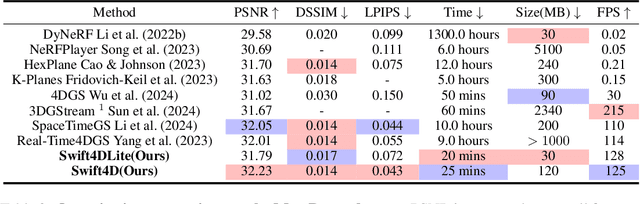
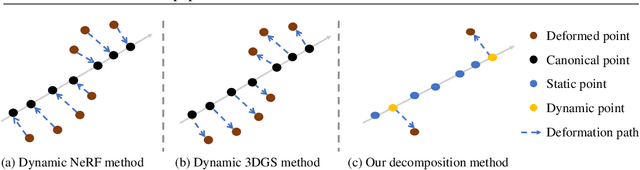
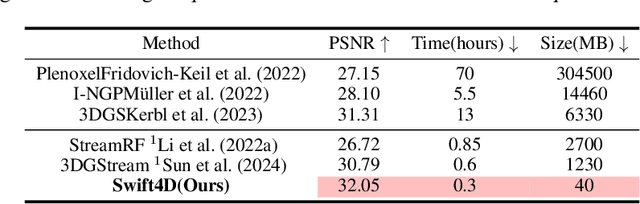
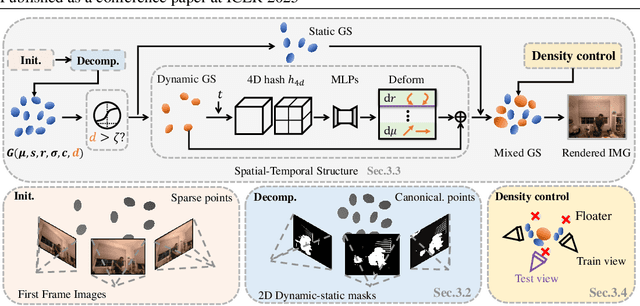
Novel view synthesis has long been a practical but challenging task, although the introduction of numerous methods to solve this problem, even combining advanced representations like 3D Gaussian Splatting, they still struggle to recover high-quality results and often consume too much storage memory and training time. In this paper we propose Swift4D, a divide-and-conquer 3D Gaussian Splatting method that can handle static and dynamic primitives separately, achieving a good trade-off between rendering quality and efficiency, motivated by the fact that most of the scene is the static primitive and does not require additional dynamic properties. Concretely, we focus on modeling dynamic transformations only for the dynamic primitives which benefits both efficiency and quality. We first employ a learnable decomposition strategy to separate the primitives, which relies on an additional parameter to classify primitives as static or dynamic. For the dynamic primitives, we employ a compact multi-resolution 4D Hash mapper to transform these primitives from canonical space into deformation space at each timestamp, and then mix the static and dynamic primitives to produce the final output. This divide-and-conquer method facilitates efficient training and reduces storage redundancy. Our method not only achieves state-of-the-art rendering quality while being 20X faster in training than previous SOTA methods with a minimum storage requirement of only 30MB on real-world datasets. Code is available at https://github.com/WuJH2001/swift4d.
A Deep Semantic Segmentation Network with Semantic and Contextual Refinements
Dec 11, 2024



Semantic segmentation is a fundamental task in multimedia processing, which can be used for analyzing, understanding, editing contents of images and videos, among others. To accelerate the analysis of multimedia data, existing segmentation researches tend to extract semantic information by progressively reducing the spatial resolutions of feature maps. However, this approach introduces a misalignment problem when restoring the resolution of high-level feature maps. In this paper, we design a Semantic Refinement Module (SRM) to address this issue within the segmentation network. Specifically, SRM is designed to learn a transformation offset for each pixel in the upsampled feature maps, guided by high-resolution feature maps and neighboring offsets. By applying these offsets to the upsampled feature maps, SRM enhances the semantic representation of the segmentation network, particularly for pixels around object boundaries. Furthermore, a Contextual Refinement Module (CRM) is presented to capture global context information across both spatial and channel dimensions. To balance dimensions between channel and space, we aggregate the semantic maps from all four stages of the backbone to enrich channel context information. The efficacy of these proposed modules is validated on three widely used datasets-Cityscapes, Bdd100K, and ADE20K-demonstrating superior performance compared to state-of-the-art methods. Additionally, this paper extends these modules to a lightweight segmentation network, achieving an mIoU of 82.5% on the Cityscapes validation set with only 137.9 GFLOPs.
A feature refinement module for light-weight semantic segmentation network
Dec 11, 2024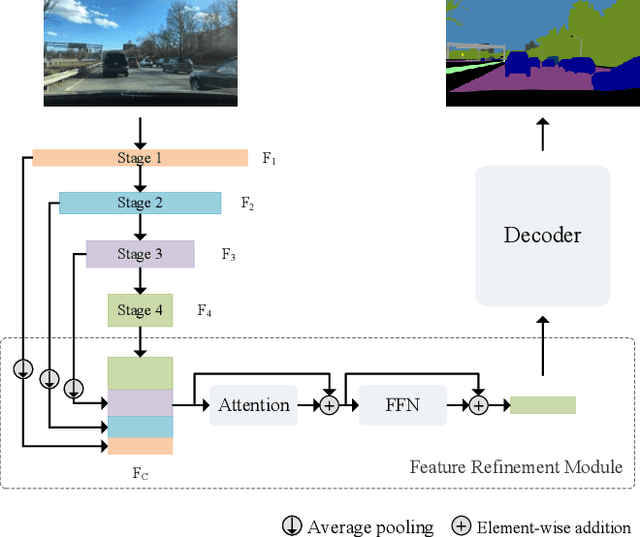
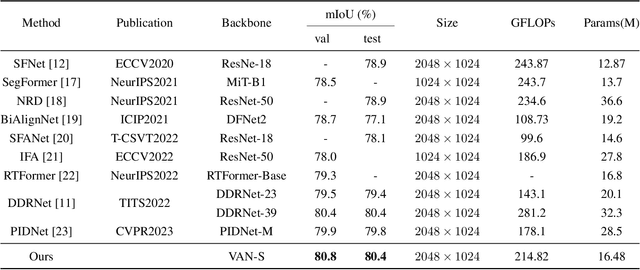
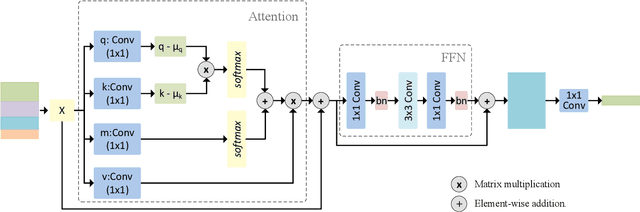
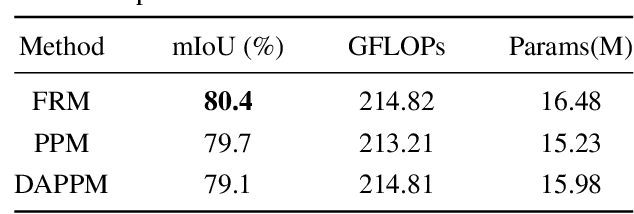
Low computational complexity and high segmentation accuracy are both essential to the real-world semantic segmentation tasks. However, to speed up the model inference, most existing approaches tend to design light-weight networks with a very limited number of parameters, leading to a considerable degradation in accuracy due to the decrease of the representation ability of the networks. To solve the problem, this paper proposes a novel semantic segmentation method to improve the capacity of obtaining semantic information for the light-weight network. Specifically, a feature refinement module (FRM) is proposed to extract semantics from multi-stage feature maps generated by the backbone and capture non-local contextual information by utilizing a transformer block. On Cityscapes and Bdd100K datasets, the experimental results demonstrate that the proposed method achieves a promising trade-off between accuracy and computational cost, especially for Cityscapes test set where 80.4% mIoU is achieved and only 214.82 GFLOPs are required.