 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocalDyGS: Multi-view Global Dynamic Scene Modeling via Adaptive Local Implicit Feature Decoupling
Jul 03, 2025Due to the complex and highly dynamic motions in the real world, synthesizing dynamic videos from multi-view inputs for arbitrary viewpoints is challenging. Previous works based on neural radiance field or 3D Gaussian splatting are limited to modeling fine-scale motion, greatly restricting their application. In this paper, we introduce LocalDyGS, which consists of two parts to adapt our method to both large-scale and fine-scale motion scenes: 1) We decompose a complex dynamic scene into streamlined local spaces defined by seeds, enabling global modeling by capturing motion within each local space. 2) We decouple static and dynamic features for local space motion modeling. A static feature shared across time steps captures static information, while a dynamic residual field provides time-specific features. These are combined and decoded to generate Temporal Gaussians, modeling motion within each local space. As a result, we propose a novel dynamic scene reconstruction framework to model highly dynamic real-world scenes more realistically. Our method not only demonstrates competitive performance on various fine-scale datasets compared to state-of-the-art (SOTA) methods, but also represents the first attempt to model larger and more complex highly dynamic scenes. Project page: https://wujh2001.github.io/LocalDyGS/.
Swift4D:Adaptive divide-and-conquer Gaussian Splatting for compact and efficient reconstruction of dynamic scene
Mar 16, 2025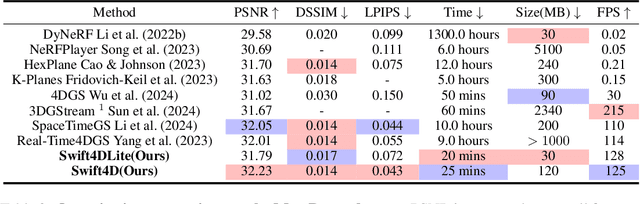
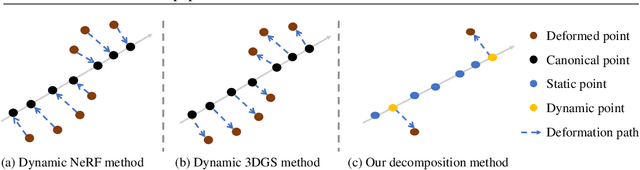
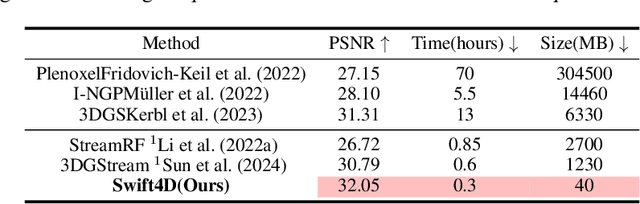
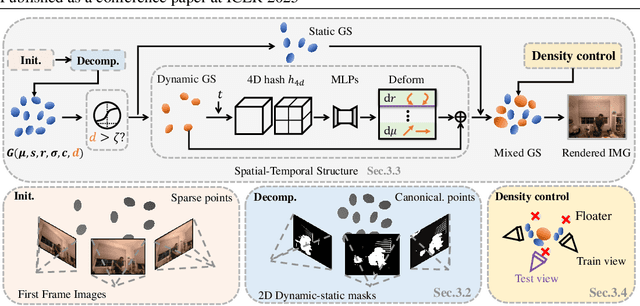
Novel view synthesis has long been a practical but challenging task, although the introduction of numerous methods to solve this problem, even combining advanced representations like 3D Gaussian Splatting, they still struggle to recover high-quality results and often consume too much storage memory and training time. In this paper we propose Swift4D, a divide-and-conquer 3D Gaussian Splatting method that can handle static and dynamic primitives separately, achieving a good trade-off between rendering quality and efficiency, motivated by the fact that most of the scene is the static primitive and does not require additional dynamic properties. Concretely, we focus on modeling dynamic transformations only for the dynamic primitives which benefits both efficiency and quality. We first employ a learnable decomposition strategy to separate the primitives, which relies on an additional parameter to classify primitives as static or dynamic. For the dynamic primitives, we employ a compact multi-resolution 4D Hash mapper to transform these primitives from canonical space into deformation space at each timestamp, and then mix the static and dynamic primitives to produce the final output. This divide-and-conquer method facilitates efficient training and reduces storage redundancy. Our method not only achieves state-of-the-art rendering quality while being 20X faster in training than previous SOTA methods with a minimum storage requirement of only 30MB on real-world datasets. Code is available at https://github.com/WuJH2001/swift4d.
MVD-HuGaS: Human Gaussians from a Single Image via 3D Human Multi-view Diffusion Prior
Mar 11, 2025



3D human reconstruction from a single image is a challenging problem and has been exclusively studied in the literature. Recently, some methods have resorted to diffusion models for guidance, optimizing a 3D representation via Score Distillation Sampling(SDS) or generating one back-view image for facilitating reconstruction. However, these methods tend to produce unsatisfactory artifacts (\textit{e.g.} flattened human structure or over-smoothing results caused by inconsistent priors from multiple views) and struggle with real-world generalization in the wild. In this work, we present \emph{MVD-HuGaS}, enabling free-view 3D human rendering from a single image via a multi-view human diffusion model. We first generate multi-view images from the single reference image with an enhanced multi-view diffusion model, which is well fine-tuned on high-quality 3D human datasets to incorporate 3D geometry priors and human structure priors. To infer accurate camera poses from the sparse generated multi-view images for reconstruction, an alignment module is introduced to facilitate joint optimization of 3D Gaussians and camera poses. Furthermore, we propose a depth-based Facial Distortion Mitigation module to refine the generated facial regions, thereby improving the overall fidelity of the reconstruction.Finally, leveraging the refined multi-view images, along with their accurate camera poses, MVD-HuGaS optimizes the 3D Gaussians of the target human for high-fidelity free-view renderings. Extensive experiments on Thuman2.0 and 2K2K datasets show that the proposed MVD-HuGaS achieves state-of-the-art performance on single-view 3D human rendering.
CL-MVSNet: Unsupervised Multi-view Stereo with Dual-level Contrastive Learning
Mar 11, 2025
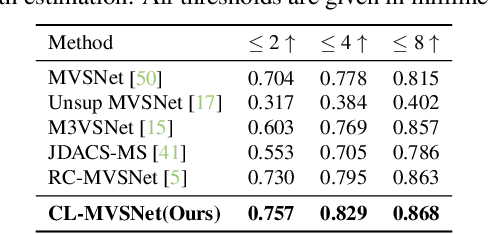
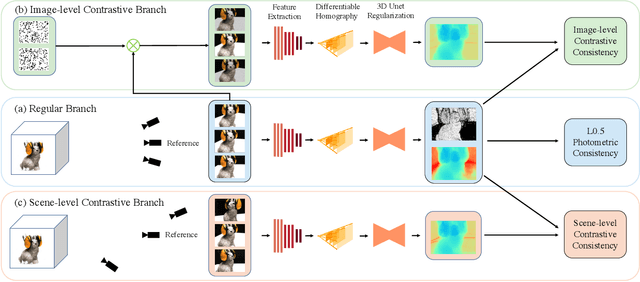
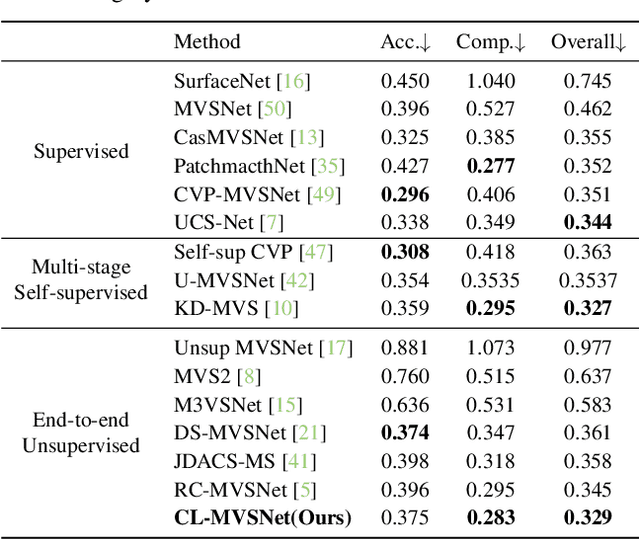
Unsupervised Multi-View Stereo (MVS) methods have achieved promising progress recently. However, previous methods primarily depend on the photometric consistency assumption, which may suffer from two limitations: indistinguishable regions and view-dependent effects, e.g., low-textured areas and reflections. To address these issues, in this paper, we propose a new dual-level contrastive learning approach, named CL-MVSNet. Specifically, our model integrates two contrastive branches into an unsupervised MVS framework to construct additional supervisory signals. On the one hand, we present an image-level contrastive branch to guide the model to acquire more context awareness, thus leading to more complete depth estimation in indistinguishable regions. On the other hand, we exploit a scene-level contrastive branch to boost the representation ability, improving robustness to view-dependent effects. Moreover, to recover more accurate 3D geometry, we introduce an L0.5 photometric consistency loss, which encourages the model to focus more on accurate points while mitigating the gradient penalty of undesirable ones. Extensive experiments on DTU and Tanks&Temples benchmarks demonstrate that our approach achieves state-of-the-art performance among all end-to-end unsupervised MVS frameworks and outperforms its supervised counterpart by a considerable margin without fine-tuning.
Surface-Centric Modeling for High-Fidelity Generalizable Neural Surface Reconstruction
Sep 05, 2024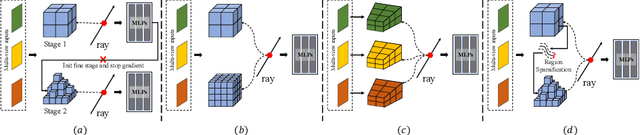
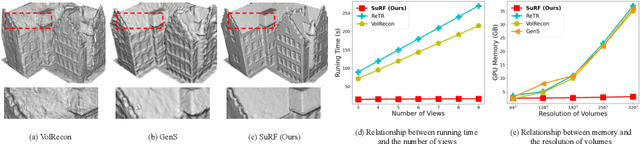
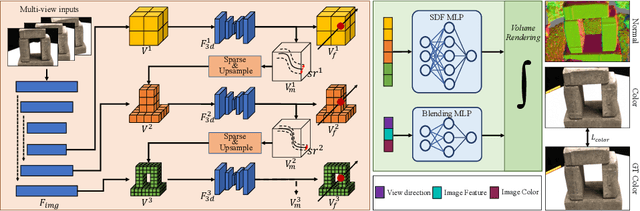
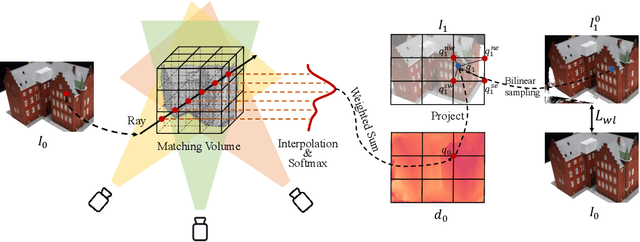
Reconstructing the high-fidelity surface from multi-view images, especially sparse images, is a critical and practical task that has attracted widespread attention in recent years. However, existing methods are impeded by the memory constraint or the requirement of ground-truth depths and cannot recover satisfactory geometric details. To this end, we propose SuRF, a new Surface-centric framework that incorporates a new Region sparsification based on a matching Field, achieving good trade-offs between performance, efficiency and scalability. To our knowledge, this is the first unsupervised method achieving end-to-end sparsification powered by the introduced matching field, which leverages the weight distribution to efficiently locate the boundary regions containing surface. Instead of predicting an SDF value for each voxel, we present a new region sparsification approach to sparse the volume by judging whether the voxel is inside the surface region. In this way, our model can exploit higher frequency features around the surface with less memory and computational consumption. Extensive experiments on multiple benchmarks containing complex large-scale scenes show that our reconstructions exhibit high-quality details and achieve new state-of-the-art performance, i.e., 46% improvements with 80% less memory consumption. Code is available at https://github.com/prstrive/SuRF.
HDRGS: High Dynamic Range Gaussian Splatting
Aug 13, 2024Recent years have witnessed substantial advancements in the field of 3D reconstruction from 2D images, particularly following the introduction of the neural radiance field (NeRF) technique. However, reconstructing a 3D high dynamic range (HDR) radiance field, which aligns more closely with real-world conditions, from 2D multi-exposure low dynamic range (LDR) images continues to pose significant challenges. Approaches to this issue fall into two categories: grid-based and implicit-based. Implicit methods, using multi-layer perceptrons (MLP), face inefficiencies, limited solvability, and overfitting risks. Conversely, grid-based methods require significant memory and struggle with image quality and long training times. In this paper, we introduce Gaussian Splatting-a recent, high-quality, real-time 3D reconstruction technique-into this domain. We further develop the High Dynamic Range Gaussian Splatting (HDR-GS) method, designed to address the aforementioned challenges. This method enhances color dimensionality by including luminance and uses an asymmetric grid for tone-mapping, swiftly and precisely converting pixel irradiance to color. Our approach improves HDR scene recovery accuracy and integrates a novel coarse-to-fine strategy to speed up model convergence, enhancing robustness against sparse viewpoints and exposure extremes, and preventing local optima. Extensive testing confirms that our method surpasses current state-of-the-art techniques in both synthetic and real-world scenarios. Code will be released at \url{https://github.com/WuJH2001/HDRGS}