 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwift4D:Adaptive divide-and-conquer Gaussian Splatting for compact and efficient reconstruction of dynamic scene
Mar 16, 2025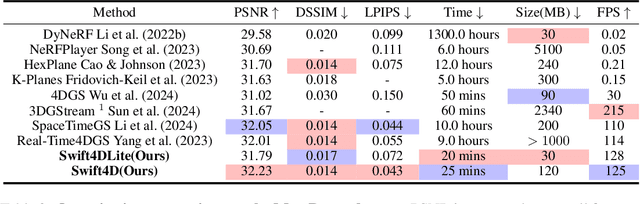
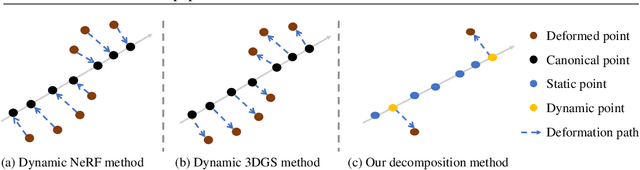
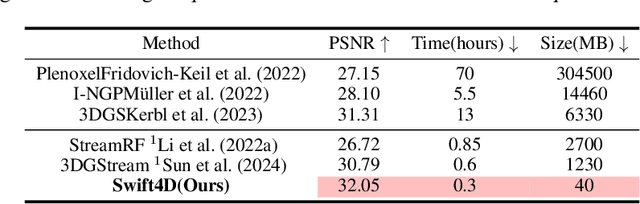
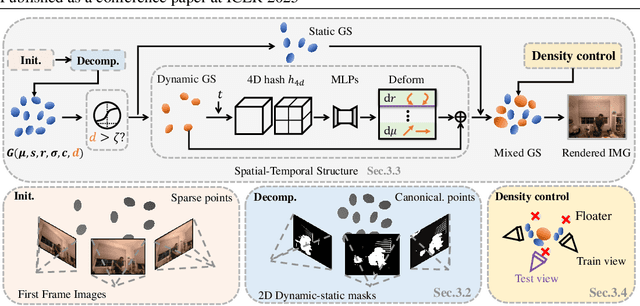
Novel view synthesis has long been a practical but challenging task, although the introduction of numerous methods to solve this problem, even combining advanced representations like 3D Gaussian Splatting, they still struggle to recover high-quality results and often consume too much storage memory and training time. In this paper we propose Swift4D, a divide-and-conquer 3D Gaussian Splatting method that can handle static and dynamic primitives separately, achieving a good trade-off between rendering quality and efficiency, motivated by the fact that most of the scene is the static primitive and does not require additional dynamic properties. Concretely, we focus on modeling dynamic transformations only for the dynamic primitives which benefits both efficiency and quality. We first employ a learnable decomposition strategy to separate the primitives, which relies on an additional parameter to classify primitives as static or dynamic. For the dynamic primitives, we employ a compact multi-resolution 4D Hash mapper to transform these primitives from canonical space into deformation space at each timestamp, and then mix the static and dynamic primitives to produce the final output. This divide-and-conquer method facilitates efficient training and reduces storage redundancy. Our method not only achieves state-of-the-art rendering quality while being 20X faster in training than previous SOTA methods with a minimum storage requirement of only 30MB on real-world datasets. Code is available at https://github.com/WuJH2001/swift4d.
HDRGS: High Dynamic Range Gaussian Splatting
Aug 13, 2024



Recent years have witnessed substantial advancements in the field of 3D reconstruction from 2D images, particularly following the introduction of the neural radiance field (NeRF) technique. However, reconstructing a 3D high dynamic range (HDR) radiance field, which aligns more closely with real-world conditions, from 2D multi-exposure low dynamic range (LDR) images continues to pose significant challenges. Approaches to this issue fall into two categories: grid-based and implicit-based. Implicit methods, using multi-layer perceptrons (MLP), face inefficiencies, limited solvability, and overfitting risks. Conversely, grid-based methods require significant memory and struggle with image quality and long training times. In this paper, we introduce Gaussian Splatting-a recent, high-quality, real-time 3D reconstruction technique-into this domain. We further develop the High Dynamic Range Gaussian Splatting (HDR-GS) method, designed to address the aforementioned challenges. This method enhances color dimensionality by including luminance and uses an asymmetric grid for tone-mapping, swiftly and precisely converting pixel irradiance to color. Our approach improves HDR scene recovery accuracy and integrates a novel coarse-to-fine strategy to speed up model convergence, enhancing robustness against sparse viewpoints and exposure extremes, and preventing local optima. Extensive testing confirms that our method surpasses current state-of-the-art techniques in both synthetic and real-world scenarios. Code will be released at \url{https://github.com/WuJH2001/HDRGS}
Explaining the Contributing Factors for Vulnerability Detection in Machine Learning
Jun 05, 2024There is an increasing trend to mine vulnerabilities from software repositories and use machine learning techniques to automatically detect software vulnerabilities. A fundamental but unresolved research question is: how do different factors in the mining and learning process impact the accuracy of identifying vulnerabilities in software projects of varying characteristics? Substantial research has been dedicated in this area, including source code static analysis, software repository mining, and NLP-based machine learning. However, practitioners lack experience regarding the key factors for building a baseline model of the state-of-the-art. In addition, there lacks of experience regarding the transferability of the vulnerability signatures from project to project. This study investigates how the combination of different vulnerability features and three representative machine learning models impact the accuracy of vulnerability detection in 17 real-world projects. We examine two types of vulnerability representations: 1) code features extracted through NLP with varying tokenization strategies and three different embedding techniques (bag-of-words, word2vec, and fastText) and 2) a set of eight architectural metrics that capture the abstract design of the software systems. The three machine learning algorithms include a random forest model, a support vector machines model, and a residual neural network model. The analysis shows a recommended baseline model with signatures extracted through bag-of-words embedding, combined with the random forest, consistently increases the detection accuracy by about 4% compared to other combinations in all 17 projects. Furthermore, we observe the limitation of transferring vulnerability signatures across domains based on our experiments.
syrapropa at SemEval-2020 Task 11: BERT-based Models Design For Propagandistic Technique and Span Detection
Aug 24, 2020



This paper describes the BERT-based models proposed for two subtasks in SemEval-2020 Task 11: Detection of Propaganda Techniques in News Articles. We first build the model for Span Identification (SI) based on SpanBERT, and facilitate the detection by a deeper model and a sentence-level representation. We then develop a hybrid model for the Technique Classification (TC). The hybrid model is composed of three submodels including two BERT models with different training methods, and a feature-based Logistic Regression model. We endeavor to deal with imbalanced dataset by adjusting cost function. We are in the seventh place in SI subtask (0.4711 of F1-measure), and in the third place in TC subtask (0.6783 of F1-measure) on the development set.