 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Orbit to Ground: Generative City Photogrammetry from Extreme Off-Nadir Satellite Images
Dec 09, 2025City-scale 3D reconstruction from satellite imagery presents the challenge of extreme viewpoint extrapolation, where our goal is to synthesize ground-level novel views from sparse orbital images with minimal parallax. This requires inferring nearly $90^\circ$ viewpoint gaps from image sources with severely foreshortened facades and flawed textures, causing state-of-the-art reconstruction engines such as NeRF and 3DGS to fail. To address this problem, we propose two design choices tailored for city structures and satellite inputs. First, we model city geometry as a 2.5D height map, implemented as a Z-monotonic signed distance field (SDF) that matches urban building layouts from top-down viewpoints. This stabilizes geometry optimization under sparse, off-nadir satellite views and yields a watertight mesh with crisp roofs and clean, vertically extruded facades. Second, we paint the mesh appearance from satellite images via differentiable rendering techniques. While the satellite inputs may contain long-range, blurry captures, we further train a generative texture restoration network to enhance the appearance, recovering high-frequency, plausible texture details from degraded inputs. Our method's scalability and robustness are demonstrated through extensive experiments on large-scale urban reconstruction. For example, in our teaser figure, we reconstruct a $4\,\mathrm{km}^2$ real-world region from only a few satellite images, achieving state-of-the-art performance in synthesizing photorealistic ground views. The resulting models are not only visually compelling but also serve as high-fidelity, application-ready assets for downstream tasks like urban planning and simulation. Project page can be found at https://pku-vcl-geometry.github.io/Orbit2Ground/.
LocalDyGS: Multi-view Global Dynamic Scene Modeling via Adaptive Local Implicit Feature Decoupling
Jul 03, 2025Due to the complex and highly dynamic motions in the real world, synthesizing dynamic videos from multi-view inputs for arbitrary viewpoints is challenging. Previous works based on neural radiance field or 3D Gaussian splatting are limited to modeling fine-scale motion, greatly restricting their application. In this paper, we introduce LocalDyGS, which consists of two parts to adapt our method to both large-scale and fine-scale motion scenes: 1) We decompose a complex dynamic scene into streamlined local spaces defined by seeds, enabling global modeling by capturing motion within each local space. 2) We decouple static and dynamic features for local space motion modeling. A static feature shared across time steps captures static information, while a dynamic residual field provides time-specific features. These are combined and decoded to generate Temporal Gaussians, modeling motion within each local space. As a result, we propose a novel dynamic scene reconstruction framework to model highly dynamic real-world scenes more realistically. Our method not only demonstrates competitive performance on various fine-scale datasets compared to state-of-the-art (SOTA) methods, but also represents the first attempt to model larger and more complex highly dynamic scenes. Project page: https://wujh2001.github.io/LocalDyGS/.
L-LBVC: Long-Term Motion Estimation and Prediction for Learned Bi-Directional Video Compression
Apr 03, 2025Recently, learned video compression (LVC) has shown superior performance under low-delay configuration. However, the performance of learned bi-directional video compression (LBVC) still lags behind traditional bi-directional coding. The performance gap mainly arises from inaccurate long-term motion estimation and prediction of distant frames, especially in large motion scenes. To solve these two critical problems, this paper proposes a novel LBVC framework, namely L-LBVC. Firstly, we propose an adaptive motion estimation module that can handle both short-term and long-term motions. Specifically, we directly estimate the optical flows for adjacent frames and non-adjacent frames with small motions. For non-adjacent frames with large motions, we recursively accumulate local flows between adjacent frames to estimate long-term flows. Secondly, we propose an adaptive motion prediction module that can largely reduce the bit cost for motion coding. To improve the accuracy of long-term motion prediction, we adaptively downsample reference frames during testing to match the motion ranges observed during training. Experiments show that our L-LBVC significantly outperforms previous state-of-the-art LVC methods and even surpasses VVC (VTM) on some test datasets under random access configuration.
Enhancing 3D Gaussian Splatting Compression via Spatial Condition-based Prediction
Mar 30, 2025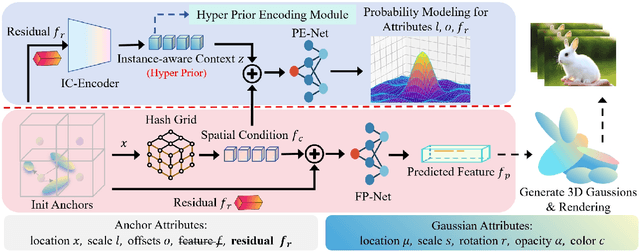
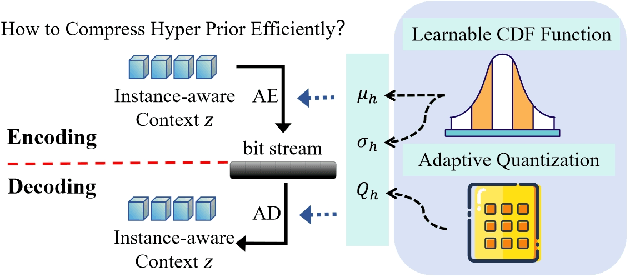

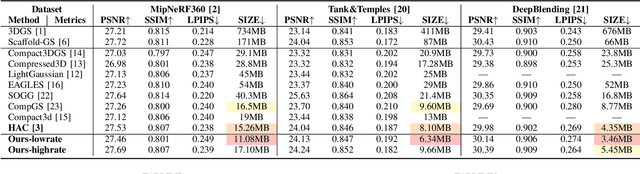
Recently, 3D Gaussian Spatting (3DGS) has gained widespread attention in Novel View Synthesis (NVS) due to the remarkable real-time rendering performance. However, the substantial cost of storage and transmission of vanilla 3DGS hinders its further application (hundreds of megabytes or even gigabytes for a single scene). Motivated by the achievements of prediction in video compression, we introduce the prediction technique into the anchor-based Gaussian representation to effectively reduce the bit rate. Specifically, we propose a spatial condition-based prediction module to utilize the grid-captured scene information for prediction, with a residual compensation strategy designed to learn the missing fine-grained information. Besides, to further compress the residual, we propose an instance-aware hyper prior, developing a structure-aware and instance-aware entropy model. Extensive experiments demonstrate the effectiveness of our prediction-based compression framework and each technical component. Even compared with SOTA compression method, our framework still achieves a bit rate savings of 24.42 percent. Code is to be released!
Swift4D:Adaptive divide-and-conquer Gaussian Splatting for compact and efficient reconstruction of dynamic scene
Mar 16, 2025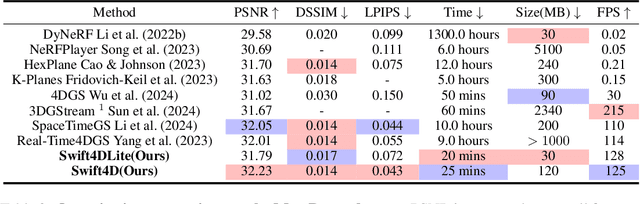
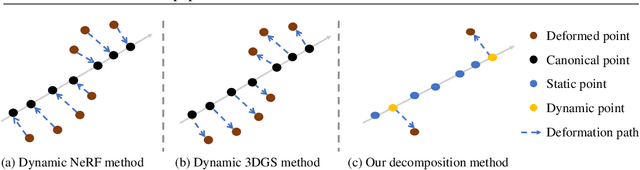
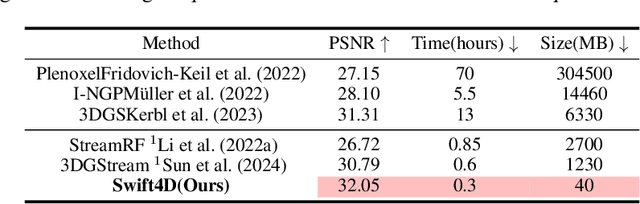
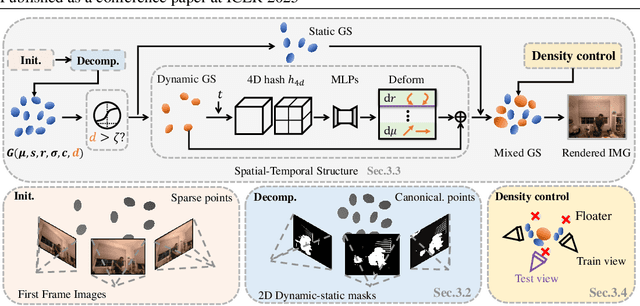
Novel view synthesis has long been a practical but challenging task, although the introduction of numerous methods to solve this problem, even combining advanced representations like 3D Gaussian Splatting, they still struggle to recover high-quality results and often consume too much storage memory and training time. In this paper we propose Swift4D, a divide-and-conquer 3D Gaussian Splatting method that can handle static and dynamic primitives separately, achieving a good trade-off between rendering quality and efficiency, motivated by the fact that most of the scene is the static primitive and does not require additional dynamic properties. Concretely, we focus on modeling dynamic transformations only for the dynamic primitives which benefits both efficiency and quality. We first employ a learnable decomposition strategy to separate the primitives, which relies on an additional parameter to classify primitives as static or dynamic. For the dynamic primitives, we employ a compact multi-resolution 4D Hash mapper to transform these primitives from canonical space into deformation space at each timestamp, and then mix the static and dynamic primitives to produce the final output. This divide-and-conquer method facilitates efficient training and reduces storage redundancy. Our method not only achieves state-of-the-art rendering quality while being 20X faster in training than previous SOTA methods with a minimum storage requirement of only 30MB on real-world datasets. Code is available at https://github.com/WuJH2001/swift4d.
4D Gaussian Splatting with Scale-aware Residual Field and Adaptive Optimization for Real-time Rendering of Temporally Complex Dynamic Scenes
Dec 09, 2024



Reconstructing dynamic scenes from video sequences is a highly promising task in the multimedia domain. While previous methods have made progress, they often struggle with slow rendering and managing temporal complexities such as significant motion and object appearance/disappearance. In this paper, we propose SaRO-GS as a novel dynamic scene representation capable of achieving real-time rendering while effectively handling temporal complexities in dynamic scenes. To address the issue of slow rendering speed, we adopt a Gaussian primitive-based representation and optimize the Gaussians in 4D space, which facilitates real-time rendering with the assistance of 3D Gaussian Splatting. Additionally, to handle temporally complex dynamic scenes, we introduce a Scale-aware Residual Field. This field considers the size information of each Gaussian primitive while encoding its residual feature and aligns with the self-splitting behavior of Gaussian primitives. Furthermore, we propose an Adaptive Optimization Schedule, which assigns different optimization strategies to Gaussian primitives based on their distinct temporal properties, thereby expediting the reconstruction of dynamic regions. Through evaluations on monocular and multi-view datasets, our method has demonstrated state-of-the-art performance. Please see our project page at https://yjb6.github.io/SaRO-GS.github.io.
RelayGS: Reconstructing Dynamic Scenes with Large-Scale and Complex Motions via Relay Gaussians
Dec 03, 2024
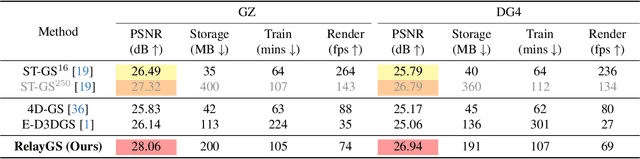
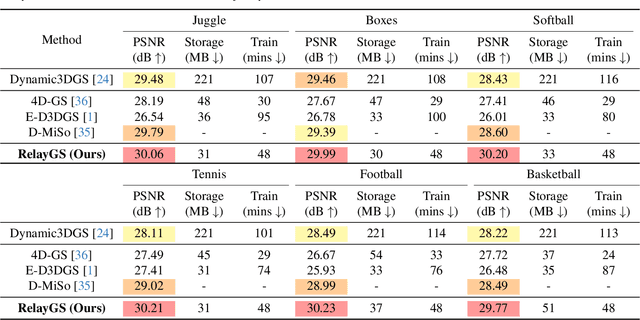
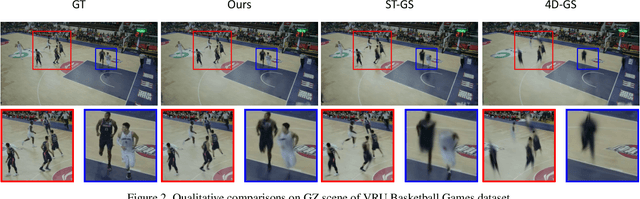
Reconstructing dynamic scenes with large-scale and complex motions remains a significant challenge. Recent techniques like Neural Radiance Fields and 3D Gaussian Splatting (3DGS) have shown promise but still struggle with scenes involving substantial movement. This paper proposes RelayGS, a novel method based on 3DGS, specifically designed to represent and reconstruct highly dynamic scenes. Our RelayGS learns a complete 4D representation with canonical 3D Gaussians and a compact motion field, consisting of three stages. First, we learn a fundamental 3DGS from all frames, ignoring temporal scene variations, and use a learnable mask to separate the highly dynamic foreground from the minimally moving background. Second, we replicate multiple copies of the decoupled foreground Gaussians from the first stage, each corresponding to a temporal segment, and optimize them using pseudo-views constructed from multiple frames within each segment. These Gaussians, termed Relay Gaussians, act as explicit relay nodes, simplifying and breaking down large-scale motion trajectories into smaller, manageable segments. Finally, we jointly learn the scene's temporal motion and refine the canonical Gaussians learned from the first two stages. We conduct thorough experiments on two dynamic scene datasets featuring large and complex motions, where our RelayGS outperforms state-of-the-arts by more than 1 dB in PSNR, and successfully reconstructs real-world basketball game scenes in a much more complete and coherent manner, whereas previous methods usually struggle to capture the complex motion of players. Code will be publicly available at https://github.com/gqk/RelayGS
Hybrid Local-Global Context Learning for Neural Video Compression
Nov 30, 2024



In neural video codecs, current state-of-the-art methods typically adopt multi-scale motion compensation to handle diverse motions. These methods estimate and compress either optical flow or deformable offsets to reduce inter-frame redundancy. However, flow-based methods often suffer from inaccurate motion estimation in complicated scenes. Deformable convolution-based methods are more robust but have a higher bit cost for motion coding. In this paper, we propose a hybrid context generation module, which combines the advantages of the above methods in an optimal way and achieves accurate compensation at a low bit cost. Specifically, considering the characteristics of features at different scales, we adopt flow-guided deformable compensation at largest-scale to produce accurate alignment in detailed regions. For smaller-scale features, we perform flow-based warping to save the bit cost for motion coding. Furthermore, we design a local-global context enhancement module to fully explore the local-global information of previous reconstructed signals. Experimental results demonstrate that our proposed Hybrid Local-Global Context learning (HLGC) method can significantly enhance the state-of-the-art methods on standard test datasets.
Structure Consistent Gaussian Splatting with Matching Prior for Few-shot Novel View Synthesis
Nov 06, 2024



Despite the substantial progress of novel view synthesis, existing methods, either based on the Neural Radiance Fields (NeRF) or more recently 3D Gaussian Splatting (3DGS), suffer significant degradation when the input becomes sparse. Numerous efforts have been introduced to alleviate this problem, but they still struggle to synthesize satisfactory results efficiently, especially in the large scene. In this paper, we propose SCGaussian, a Structure Consistent Gaussian Splatting method using matching priors to learn 3D consistent scene structure. Considering the high interdependence of Gaussian attributes, we optimize the scene structure in two folds: rendering geometry and, more importantly, the position of Gaussian primitives, which is hard to be directly constrained in the vanilla 3DGS due to the non-structure property. To achieve this, we present a hybrid Gaussian representation. Besides the ordinary non-structure Gaussian primitives, our model also consists of ray-based Gaussian primitives that are bound to matching rays and whose optimization of their positions is restricted along the ray. Thus, we can utilize the matching correspondence to directly enforce the position of these Gaussian primitives to converge to the surface points where rays intersect. Extensive experiments on forward-facing, surrounding, and complex large scenes show the effectiveness of our approach with state-of-the-art performance and high efficiency. Code is available at https://github.com/prstrive/SCGaussian.
GenS: Generalizable Neural Surface Reconstruction from Multi-View Images
Jun 04, 2024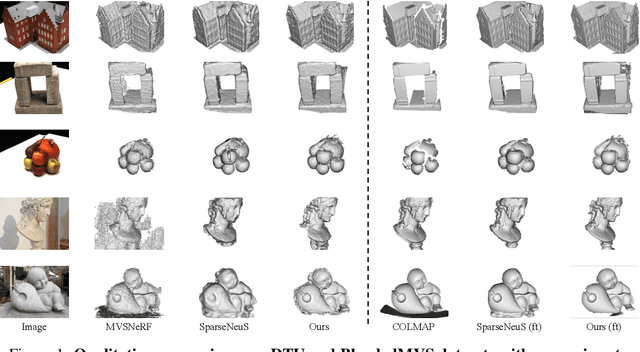
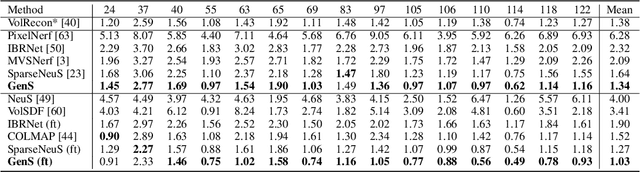
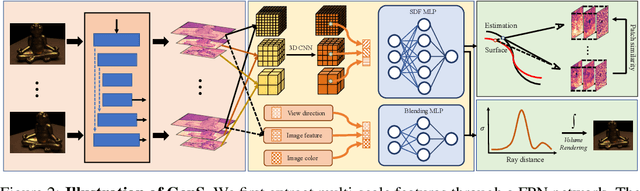
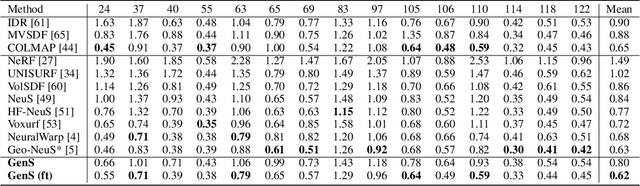
Combining the signed distance function (SDF) and differentiable volume rendering has emerged as a powerful paradigm for surface reconstruction from multi-view images without 3D supervision. However, current methods are impeded by requiring long-time per-scene optimizations and cannot generalize to new scenes. In this paper, we present GenS, an end-to-end generalizable neural surface reconstruction model. Unlike coordinate-based methods that train a separate network for each scene, we construct a generalized multi-scale volume to directly encode all scenes. Compared with existing solutions, our representation is more powerful, which can recover high-frequency details while maintaining global smoothness. Meanwhile, we introduce a multi-scale feature-metric consistency to impose the multi-view consistency in a more discriminative multi-scale feature space, which is robust to the failures of the photometric consistency. And the learnable feature can be self-enhanced to continuously improve the matching accuracy and mitigate aggregation ambiguity. Furthermore, we design a view contrast loss to force the model to be robust to those regions covered by few viewpoints through distilling the geometric prior from dense input to sparse input. Extensive experiments on popular benchmarks show that our model can generalize well to new scenes and outperform existing state-of-the-art methods even those employing ground-truth depth supervision. Code is available at https://github.com/prstrive/GenS.