 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLICv2: Enhanced Multi-Reference Entropy Modeling for Learned Image Compression
Apr 27, 2025Recent advancements in learned image compression (LIC) have yielded impressive performance gains. Notably, the learned image compression models with multi-reference entropy models (MLIC series) have significantly outperformed existing traditional image codecs such as the Versatile Video Coding (VVC) Intra. In this paper, we present MLICv2 and MLICv2$^+$, enhanced versions of the MLIC series, featuring improved transform techniques, entropy modeling, and instance adaptability. For better transform, we introduce a simple token mixing transform block inspired by the meta transformer architecture, addressing the performance degradation at high bit-rates observed in previous MLIC series while maintaining computational efficiency. To enhance entropy modeling, we propose a hyperprior-guided global correlation prediction, enabling the capture of global contexts in the initial slice of the latent representation. We also develop a channel reweighting module to dynamically prioritize important channels within each context. Additionally, advanced positional embedding for context modeling and selective compression with guided optimization are investigated. To boost instance adaptability, we employ stochastic Gumbel annealing to iteratively refine the latent representation according to the rate-distortion optimization of a specific input image. This approach further enhances performance without impacting decoding speed. Experimental results demonstrate that our MLICv2 and MLICv2$^+$ achieve state-of-the-art performance, reducing Bjontegaard-Delta rate (BD-rate) by 16.54%, 21.61%, 16.05% and 20.46%, 24.35%, 19.14% respectively, compared to VTM-17.0 Intra on the Kodak, Tecnick, CLIC Pro Val dataset, respectively.
L-LBVC: Long-Term Motion Estimation and Prediction for Learned Bi-Directional Video Compression
Apr 03, 2025Recently, learned video compression (LVC) has shown superior performance under low-delay configuration. However, the performance of learned bi-directional video compression (LBVC) still lags behind traditional bi-directional coding. The performance gap mainly arises from inaccurate long-term motion estimation and prediction of distant frames, especially in large motion scenes. To solve these two critical problems, this paper proposes a novel LBVC framework, namely L-LBVC. Firstly, we propose an adaptive motion estimation module that can handle both short-term and long-term motions. Specifically, we directly estimate the optical flows for adjacent frames and non-adjacent frames with small motions. For non-adjacent frames with large motions, we recursively accumulate local flows between adjacent frames to estimate long-term flows. Secondly, we propose an adaptive motion prediction module that can largely reduce the bit cost for motion coding. To improve the accuracy of long-term motion prediction, we adaptively downsample reference frames during testing to match the motion ranges observed during training. Experiments show that our L-LBVC significantly outperforms previous state-of-the-art LVC methods and even surpasses VVC (VTM) on some test datasets under random access configuration.
Enhancing 3D Gaussian Splatting Compression via Spatial Condition-based Prediction
Mar 30, 2025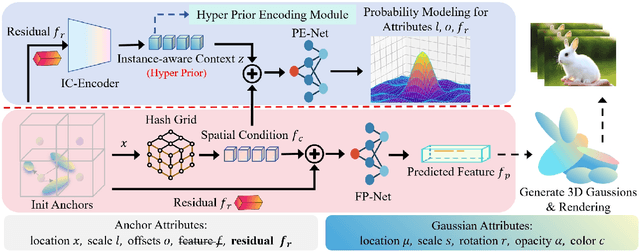
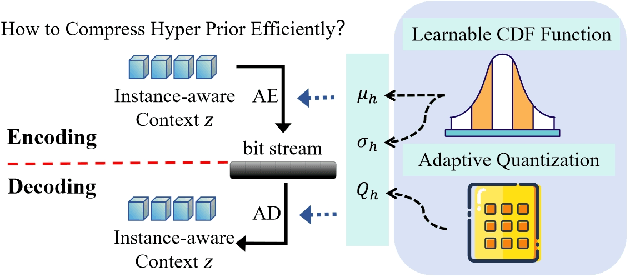

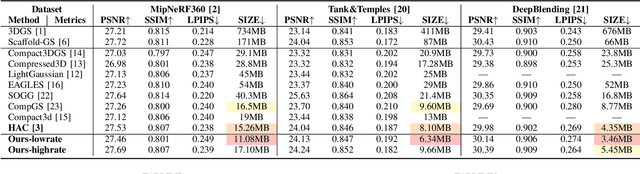
Recently, 3D Gaussian Spatting (3DGS) has gained widespread attention in Novel View Synthesis (NVS) due to the remarkable real-time rendering performance. However, the substantial cost of storage and transmission of vanilla 3DGS hinders its further application (hundreds of megabytes or even gigabytes for a single scene). Motivated by the achievements of prediction in video compression, we introduce the prediction technique into the anchor-based Gaussian representation to effectively reduce the bit rate. Specifically, we propose a spatial condition-based prediction module to utilize the grid-captured scene information for prediction, with a residual compensation strategy designed to learn the missing fine-grained information. Besides, to further compress the residual, we propose an instance-aware hyper prior, developing a structure-aware and instance-aware entropy model. Extensive experiments demonstrate the effectiveness of our prediction-based compression framework and each technical component. Even compared with SOTA compression method, our framework still achieves a bit rate savings of 24.42 percent. Code is to be released!
Hybrid Local-Global Context Learning for Neural Video Compression
Nov 30, 2024



In neural video codecs, current state-of-the-art methods typically adopt multi-scale motion compensation to handle diverse motions. These methods estimate and compress either optical flow or deformable offsets to reduce inter-frame redundancy. However, flow-based methods often suffer from inaccurate motion estimation in complicated scenes. Deformable convolution-based methods are more robust but have a higher bit cost for motion coding. In this paper, we propose a hybrid context generation module, which combines the advantages of the above methods in an optimal way and achieves accurate compensation at a low bit cost. Specifically, considering the characteristics of features at different scales, we adopt flow-guided deformable compensation at largest-scale to produce accurate alignment in detailed regions. For smaller-scale features, we perform flow-based warping to save the bit cost for motion coding. Furthermore, we design a local-global context enhancement module to fully explore the local-global information of previous reconstructed signals. Experimental results demonstrate that our proposed Hybrid Local-Global Context learning (HLGC) method can significantly enhance the state-of-the-art methods on standard test datasets.
UCVC: A Unified Contextual Video Compression Framework with Joint P-frame and B-frame Coding
Feb 02, 2024



This paper presents a learned video compression method in response to video compression track of the 6th Challenge on Learned Image Compression (CLIC), at DCC 2024.Specifically, we propose a unified contextual video compression framework (UCVC) for joint P-frame and B-frame coding. Each non-intra frame refers to two neighboring decoded frames, which can be either both from the past for P-frame compression, or one from the past and one from the future for B-frame compression. In training stage, the model parameters are jointly optimized with both P-frames and B-frames. Benefiting from the designs, the framework can support both P-frame and B-frame coding and achieve comparable compression efficiency with that specifically designed for P-frame or B-frame.As for challenge submission, we report the optimal compression efficiency by selecting appropriate frame types for each test sequence. Our team name is PKUSZ-LVC.
Learned Image Compression with ROI-Weighted Distortion and Bit Allocation
Jan 17, 2024This one page paper describes our method for the track of image compression. To achieve better perceptual quality, we use the adversarial loss to generate realistic textures, use region of interest (ROI) mask to guide the bit allocation for different regions. Our Team name is TLIC.
Multi-Reference Entropy Model for Learned Image Compression
Nov 14, 2022Recently, learned image compression has achieved remarkable performance. Entropy model, which accurately estimates the distribution of latent representation, plays an important role in boosting rate distortion performance. Most entropy models capture correlations in one dimension. However, there are channel-wise, local and global spatial correlations in latent representation. To address this issue, we propose multi-reference entropy models MEM and MEM+ to capture channel, local and global spatial contexts. We divide latent representation into slices. When decoding current slice, we use previously decoded slices as contexts and use attention map of previously decoded slice to predict global correlations in current slice. To capture local contexts, we propose enhanced checkerboard context capturing to avoid performance degradation while retaining two-pass decoding. Based on MEM and MEM+, we propose image compression models MLIC and MLIC+. Extensive experimental evaluations have shown that our MLIC and MLIC+ achieve state-of-the-art performance and they reduce BD-rate by 9.77% and 13.09% on Kodak dataset over VVC when measured in PSNR.
DeepFGS: Fine-Grained Scalable Coding for Learned Image Compression
Jan 04, 2022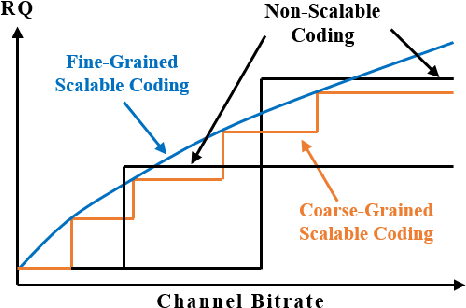

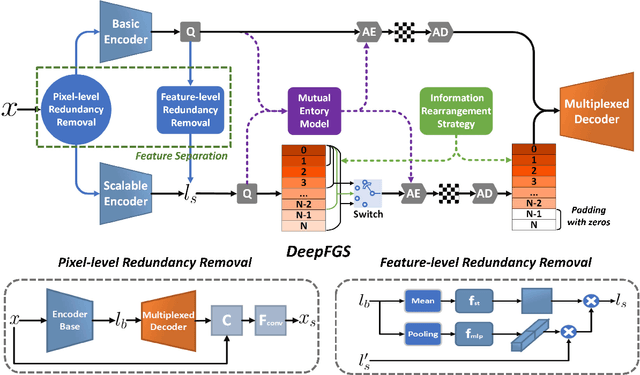

Scalable coding, which can adapt to channel bandwidth variation, performs well in today's complex network environment. However, the existing scalable compression methods face two challenges: reduced compression performance and insufficient scalability. In this paper, we propose the first learned fine-grained scalable image compression model (DeepFGS) to overcome the above two shortcomings. Specifically, we introduce a feature separation backbone to divide the image information into basic and scalable features, then redistribute the features channel by channel through an information rearrangement strategy. In this way, we can generate a continuously scalable bitstream via one-pass encoding. In addition, we reuse the decoder to reduce the parameters and computational complexity of DeepFGS. Experiments demonstrate that our DeepFGS outperforms all learning-based scalable image compression models and conventional scalable image codecs in PSNR and MS-SSIM metrics. To the best of our knowledge, our DeepFGS is the first exploration of learned fine-grained scalable coding, which achieves the finest scalability compared with learning-based methods.