 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpark3R: Asymmetric Token Reduction Makes Fast Feed-Forward 3D Reconstruction
May 07, 2026Feed-forward 3D reconstruction models based on Vision Transformers can directly estimate scene geometry and camera poses from a small set of input images, but scaling them to video inputs with hundreds or thousands of frames remains challenging due to the quadratic cost of global attention layers. Recent token-merging methods accelerate these models by compressing the token sequence within the global attention layers, but they apply a uniform reduction to query tokens and key-value tokens, ignoring their functionally distinct roles in 3D reconstruction. In this work, we identify a key property of feed-forward 3D reconstruction models: query tokens encode view-specific geometric requests and are sensitive to compression, while key-value tokens represent shared scene context and tolerate aggressive compression. Guided by this insight, we propose Spark3R, a training-free acceleration framework that decouples the compression of query tokens and key-value tokens by assigning distinct reduction factors, with intra-group token merging applied to query tokens and lightweight token pruning to key-value tokens. Additionally, Spark3R adaptively adjusts the key-value reduction factor across layers, further improving the quality-efficiency trade-off. As a plug-and-play framework requiring no retraining, Spark3R integrates directly into multiple pretrained feed-forward 3D reconstruction models, including VGGT, $π^3$, and Depth-Anything-3, and achieves up to $28\times$ speedup on 1,000-frame inputs while maintaining competitive reconstruction quality.
RelayGS: Reconstructing Dynamic Scenes with Large-Scale and Complex Motions via Relay Gaussians
Dec 03, 2024
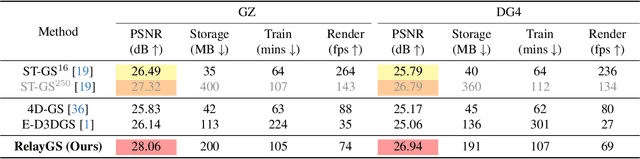
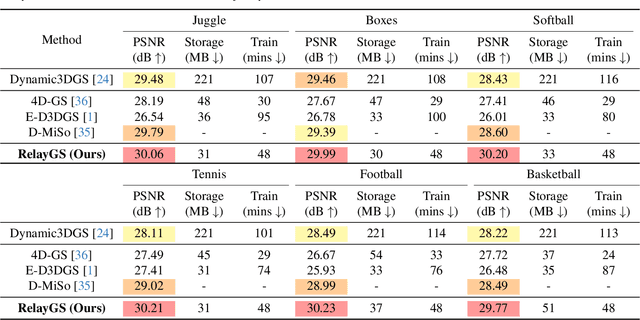
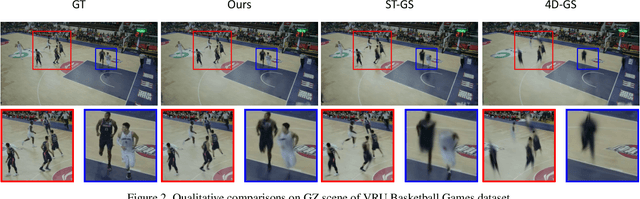
Reconstructing dynamic scenes with large-scale and complex motions remains a significant challenge. Recent techniques like Neural Radiance Fields and 3D Gaussian Splatting (3DGS) have shown promise but still struggle with scenes involving substantial movement. This paper proposes RelayGS, a novel method based on 3DGS, specifically designed to represent and reconstruct highly dynamic scenes. Our RelayGS learns a complete 4D representation with canonical 3D Gaussians and a compact motion field, consisting of three stages. First, we learn a fundamental 3DGS from all frames, ignoring temporal scene variations, and use a learnable mask to separate the highly dynamic foreground from the minimally moving background. Second, we replicate multiple copies of the decoupled foreground Gaussians from the first stage, each corresponding to a temporal segment, and optimize them using pseudo-views constructed from multiple frames within each segment. These Gaussians, termed Relay Gaussians, act as explicit relay nodes, simplifying and breaking down large-scale motion trajectories into smaller, manageable segments. Finally, we jointly learn the scene's temporal motion and refine the canonical Gaussians learned from the first two stages. We conduct thorough experiments on two dynamic scene datasets featuring large and complex motions, where our RelayGS outperforms state-of-the-arts by more than 1 dB in PSNR, and successfully reconstructs real-world basketball game scenes in a much more complete and coherent manner, whereas previous methods usually struggle to capture the complex motion of players. Code will be publicly available at https://github.com/gqk/RelayGS
InstanceGaussian: Appearance-Semantic Joint Gaussian Representation for 3D Instance-Level Perception
Nov 28, 2024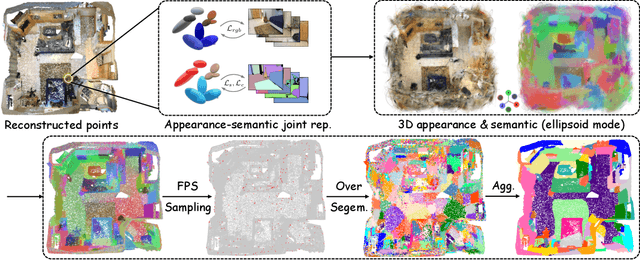
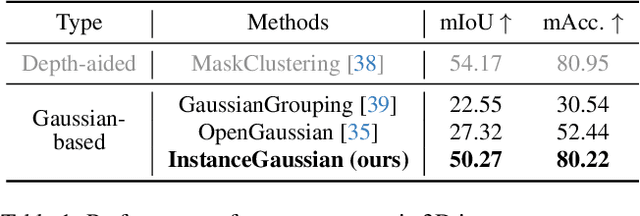
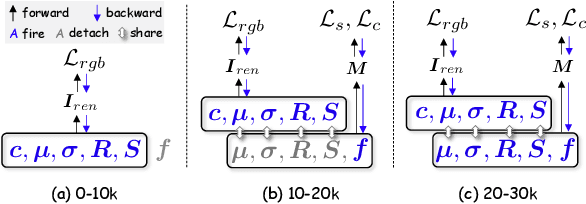
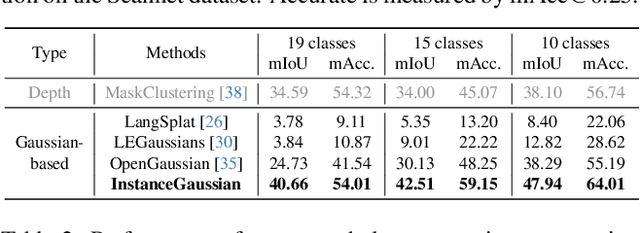
3D scene understanding has become an essential area of research with applications in autonomous driving, robotics, and augmented reality. Recently, 3D Gaussian Splatting (3DGS) has emerged as a powerful approach, combining explicit modeling with neural adaptability to provide efficient and detailed scene representations. However, three major challenges remain in leveraging 3DGS for scene understanding: 1) an imbalance between appearance and semantics, where dense Gaussian usage for fine-grained texture modeling does not align with the minimal requirements for semantic attributes; 2) inconsistencies between appearance and semantics, as purely appearance-based Gaussians often misrepresent object boundaries; and 3) reliance on top-down instance segmentation methods, which struggle with uneven category distributions, leading to over- or under-segmentation. In this work, we propose InstanceGaussian, a method that jointly learns appearance and semantic features while adaptively aggregating instances. Our contributions include: i) a novel Semantic-Scaffold-GS representation balancing appearance and semantics to improve feature representations and boundary delineation; ii) a progressive appearance-semantic joint training strategy to enhance stability and segmentation accuracy; and iii) a bottom-up, category-agnostic instance aggregation approach that addresses segmentation challenges through farthest point sampling and connected component analysis. Our approach achieves state-of-the-art performance in category-agnostic, open-vocabulary 3D point-level segmentation, highlighting the effectiveness of the proposed representation and training strategies. Project page: https://lhj-git.github.io/InstanceGaussian/
HiCoM: Hierarchical Coherent Motion for Streamable Dynamic Scene with 3D Gaussian Splatting
Nov 12, 2024



The online reconstruction of dynamic scenes from multi-view streaming videos faces significant challenges in training, rendering and storage efficiency. Harnessing superior learning speed and real-time rendering capabilities, 3D Gaussian Splatting (3DGS) has recently demonstrated considerable potential in this field. However, 3DGS can be inefficient in terms of storage and prone to overfitting by excessively growing Gaussians, particularly with limited views. This paper proposes an efficient framework, dubbed HiCoM, with three key components. First, we construct a compact and robust initial 3DGS representation using a perturbation smoothing strategy. Next, we introduce a Hierarchical Coherent Motion mechanism that leverages the inherent non-uniform distribution and local consistency of 3D Gaussians to swiftly and accurately learn motions across frames. Finally, we continually refine the 3DGS with additional Gaussians, which are later merged into the initial 3DGS to maintain consistency with the evolving scene. To preserve a compact representation, an equivalent number of low-opacity Gaussians that minimally impact the representation are removed before processing subsequent frames. Extensive experiments conducted on two widely used datasets show that our framework improves learning efficiency of the state-of-the-art methods by about $20\%$ and reduces the data storage by $85\%$, achieving competitive free-viewpoint video synthesis quality but with higher robustness and stability. Moreover, by parallel learning multiple frames simultaneously, our HiCoM decreases the average training wall time to $<2$ seconds per frame with negligible performance degradation, substantially boosting real-world applicability and responsiveness.
Mirror-3DGS: Incorporating Mirror Reflections into 3D Gaussian Splatting
Apr 01, 2024
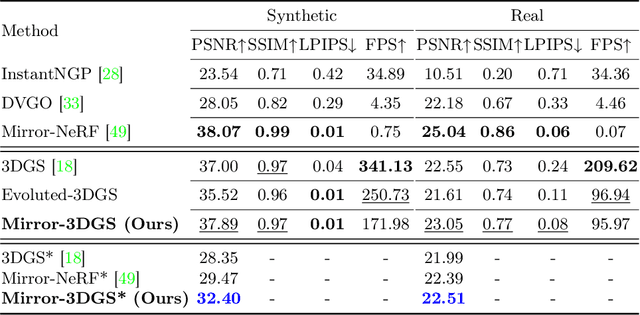
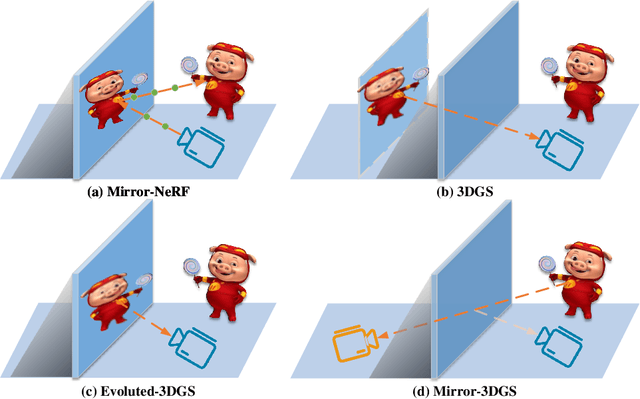
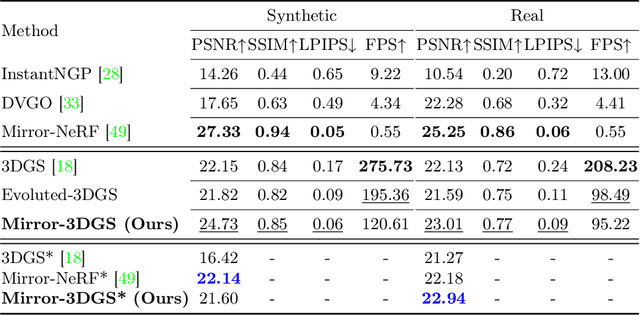
3D Gaussian Splatting (3DGS) has marked a significant breakthrough in the realm of 3D scene reconstruction and novel view synthesis. However, 3DGS, much like its predecessor Neural Radiance Fields (NeRF), struggles to accurately model physical reflections, particularly in mirrors that are ubiquitous in real-world scenes. This oversight mistakenly perceives reflections as separate entities that physically exist, resulting in inaccurate reconstructions and inconsistent reflective properties across varied viewpoints. To address this pivotal challenge, we introduce Mirror-3DGS, an innovative rendering framework devised to master the intricacies of mirror geometries and reflections, paving the way for the generation of realistically depicted mirror reflections. By ingeniously incorporating mirror attributes into the 3DGS and leveraging the principle of plane mirror imaging, Mirror-3DGS crafts a mirrored viewpoint to observe from behind the mirror, enriching the realism of scene renderings. Extensive assessments, spanning both synthetic and real-world scenes, showcase our method's ability to render novel views with enhanced fidelity in real-time, surpassing the state-of-the-art Mirror-NeRF specifically within the challenging mirror regions. Our code will be made publicly available for reproducible research.
Language-Assisted 3D Scene Understanding
Dec 31, 2023



The scale and quality of point cloud datasets constrain the advancement of point cloud learning. Recently, with the development of multi-modal learning, the incorporation of domain-agnostic prior knowledge from other modalities, such as images and text, to assist in point cloud feature learning has been considered a promising avenue. Existing methods have demonstrated the effectiveness of multi-modal contrastive training and feature distillation on point clouds. However, challenges remain, including the requirement for paired triplet data, redundancy and ambiguity in supervised features, and the disruption of the original priors. In this paper, we propose a language-assisted approach to point cloud feature learning (LAST-PCL), enriching semantic concepts through LLMs-based text enrichment. We achieve de-redundancy and feature dimensionality reduction without compromising textual priors by statistical-based and training-free significant feature selection. Furthermore, we also delve into an in-depth analysis of the impact of text contrastive training on the point cloud. Extensive experiments validate that the proposed method learns semantically meaningful point cloud features and achieves state-of-the-art or comparable performance in 3D semantic segmentation, 3D object detection, and 3D scene classification tasks.
A Unified Continual Learning Framework with General Parameter-Efficient Tuning
Mar 17, 2023



The "pre-training $\rightarrow$ downstream adaptation" presents both new opportunities and challenges for Continual Learning (CL). Although the recent state-of-the-art in CL is achieved through Parameter-Efficient-Tuning (PET) adaptation paradigm, only prompt has been explored, limiting its application to Transformers only. In this paper, we position prompting as one instantiation of PET, and propose a unified CL framework with general PET, dubbed as Learning-Accumulation-Ensemble (LAE). PET, e.g., using Adapter, LoRA, or Prefix, can adapt a pre-trained model to downstream tasks with fewer parameters and resources. Given a PET method, our LAE framework incorporates it for CL with three novel designs. 1) Learning: the pre-trained model adapts to the new task by tuning an online PET module, along with our adaptation speed calibration to align different PET modules, 2) Accumulation: the task-specific knowledge learned by the online PET module is accumulated into an offline PET module through momentum update, 3) Ensemble: During inference, we respectively construct two experts with online/offline PET modules (which are favored by the novel/historical tasks) for prediction ensemble. We show that LAE is compatible with a battery of PET methods and gains strong CL capability. For example, LAE with Adaptor PET surpasses the prior state-of-the-art by 1.3% and 3.6% in last-incremental accuracy on CIFAR100 and ImageNet-R datasets, respectively.
R-DFCIL: Relation-Guided Representation Learning for Data-Free Class Incremental Learning
Mar 24, 2022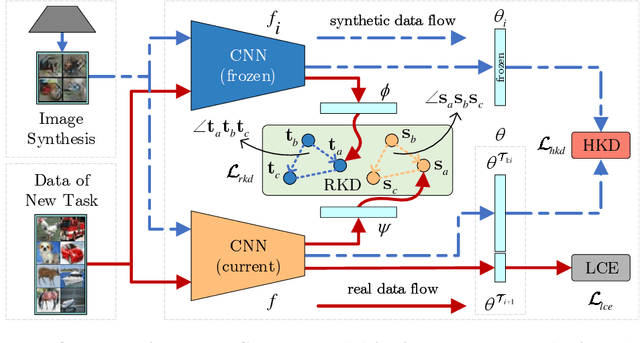
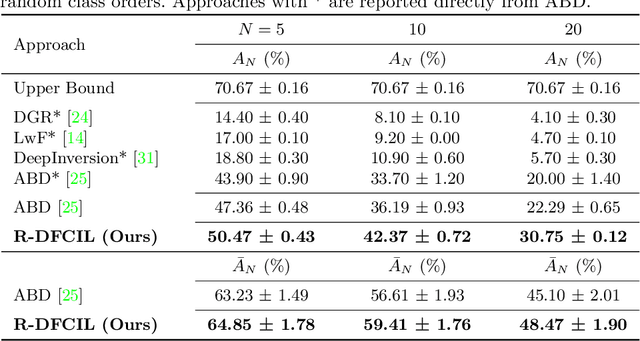

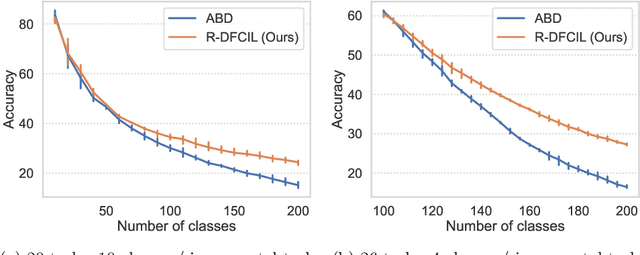
Class-Incremental Learning (CIL) struggles with catastrophic forgetting when learning new knowledge, and Data-Free CIL (DFCIL) is even more challenging without access to the training data of previous classes. Though recent DFCIL works introduce techniques such as model inversion to synthesize data for previous classes, they fail to overcome forgetting due to the severe domain gap between the synthetic and real data. To address this issue, this paper proposes relation-guided representation learning (RRL) for DFCIL, dubbed R-DFCIL. In RRL, we introduce relational knowledge distillation to flexibly transfer the structural relation of new data from the old model to the current model. Our RRL-boosted DFCIL can guide the current model to learn representations of new classes better compatible with representations of previous classes, which greatly reduces forgetting while improving plasticity. To avoid the mutual interference between representation and classifier learning, we employ local rather than global classification loss during RRL. After RRL, the classification head is fine-tuned with global class-balanced classification loss to address the data imbalance issue as well as learn the decision boundary between new and previous classes. Extensive experiments on CIFAR100, Tiny-ImageNet200, and ImageNet100 demonstrate that our R-DFCIL significantly surpasses previous approaches and achieves a new state-of-the-art performance for DFCIL.