 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExcavating the Potential Capacity of Self-Supervised Monocular Depth Estimation
Paper and Code

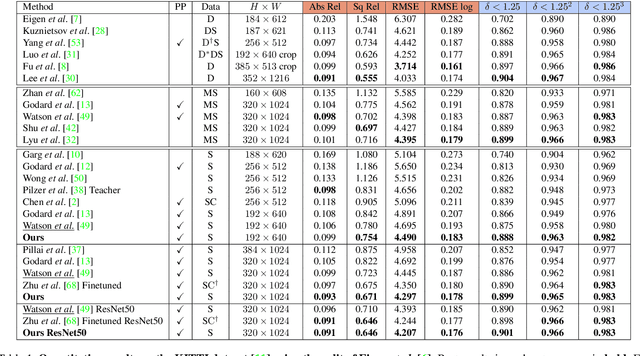
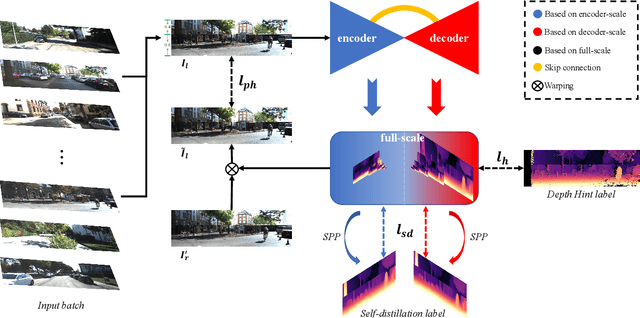
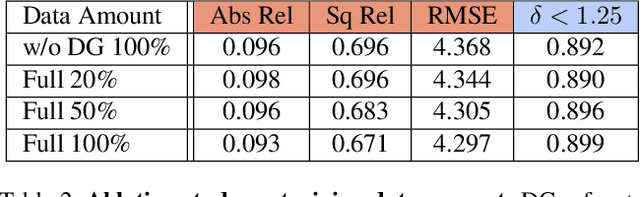
Self-supervised methods play an increasingly important role in monocular depth estimation due to their great potential and low annotation cost. To close the gap with supervised methods, recent works take advantage of extra constraints, e.g., semantic segmentation. However, these methods will inevitably increase the burden on the model. In this paper, we show theoretical and empirical evidence that the potential capacity of self-supervised monocular depth estimation can be excavated without increasing this cost. In particular, we propose (1) a novel data augmentation approach called data grafting, which forces the model to explore more cues to infer depth besides the vertical image position, (2) an exploratory self-distillation loss, which is supervised by the self-distillation label generated by our new post-processing method - selective post-processing, and (3) the full-scale network, designed to endow the encoder with the specialization of depth estimation task and enhance the representational power of the model. Extensive experiments show that our contributions can bring significant performance improvement to the baseline with even less computational overhead, and our model, named EPCDepth, surpasses the previous state-of-the-art methods even those supervised by additional constraints.