 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Guidance and Explicit Representation of Semantic Information in Points Cloud: A Survey
Jan 07, 2025



Point clouds, a prominent method of 3D representation, are extensively utilized across industries such as autonomous driving, surveying, electricity, architecture, and gaming, and have been rigorously investigated for their accuracy and resilience. The extraction of semantic information from scenes enhances both human understanding and machine perception. By integrating semantic information from two-dimensional scenes with three-dimensional point clouds, researchers aim to improve the precision and efficiency of various tasks. This paper provides a comprehensive review of the diverse applications and recent advancements in the integration of semantic information within point clouds. We explore the dual roles of semantic information in point clouds, encompassing both implicit guidance and explicit representation, across traditional and emerging tasks. Additionally, we offer a comparative analysis of publicly available datasets tailored to specific tasks and present notable observations. In conclusion, we discuss several challenges and potential issues that may arise in the future when fully utilizing semantic information in point clouds, providing our perspectives on these obstacles. The classified and organized articles related to semantic based point cloud tasks, and continuously followed up on relevant achievements in different fields, which can be accessed through https://github.com/Jasmine-tjy/Semantic-based-Point-Cloud-Tasks.
Excavating the Potential Capacity of Self-Supervised Monocular Depth Estimation
Sep 26, 2021
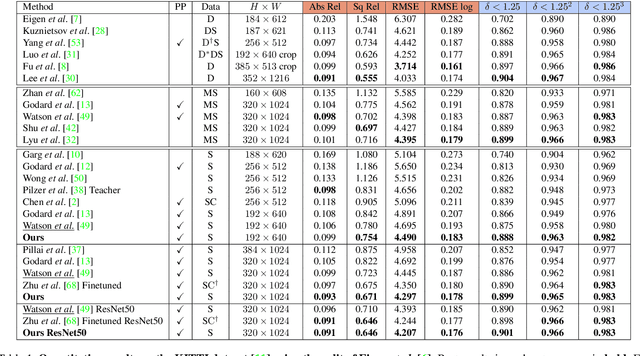
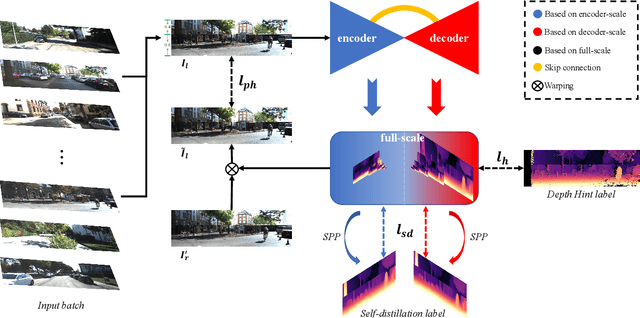
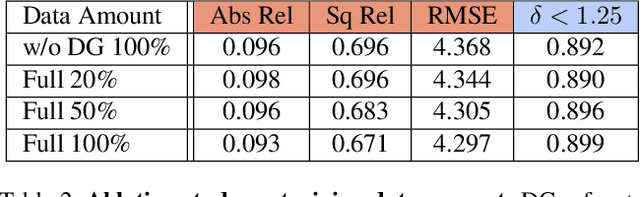
Self-supervised methods play an increasingly important role in monocular depth estimation due to their great potential and low annotation cost. To close the gap with supervised methods, recent works take advantage of extra constraints, e.g., semantic segmentation. However, these methods will inevitably increase the burden on the model. In this paper, we show theoretical and empirical evidence that the potential capacity of self-supervised monocular depth estimation can be excavated without increasing this cost. In particular, we propose (1) a novel data augmentation approach called data grafting, which forces the model to explore more cues to infer depth besides the vertical image position, (2) an exploratory self-distillation loss, which is supervised by the self-distillation label generated by our new post-processing method - selective post-processing, and (3) the full-scale network, designed to endow the encoder with the specialization of depth estimation task and enhance the representational power of the model. Extensive experiments show that our contributions can bring significant performance improvement to the baseline with even less computational overhead, and our model, named EPCDepth, surpasses the previous state-of-the-art methods even those supervised by additional constraints.