 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR3-Avatar: Record and Retrieve Temporal Codebook for Reconstructing Photorealistic Human Avatars
Mar 17, 2025
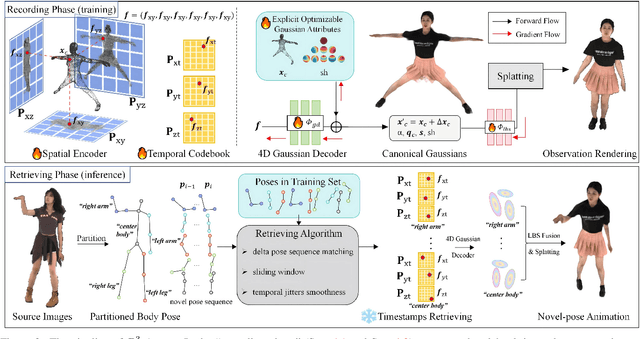
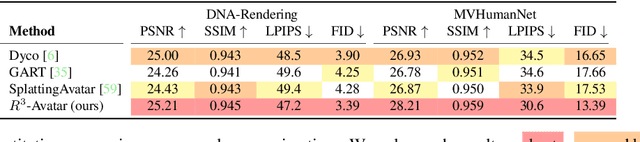

We present R3-Avatar, incorporating a temporal codebook, to overcome the inability of human avatars to be both animatable and of high-fidelity rendering quality. Existing video-based reconstruction of 3D human avatars either focuses solely on rendering, lacking animation support, or learns a pose-appearance mapping for animating, which degrades under limited training poses or complex clothing. In this paper, we adopt a "record-retrieve-reconstruct" strategy that ensures high-quality rendering from novel views while mitigating degradation in novel poses. Specifically, disambiguating timestamps record temporal appearance variations in a codebook, ensuring high-fidelity novel-view rendering, while novel poses retrieve corresponding timestamps by matching the most similar training poses for augmented appearance. Our R3-Avatar outperforms cutting-edge video-based human avatar reconstruction, particularly in overcoming visual quality degradation in extreme scenarios with limited training human poses and complex clothing.
GAST: Sequential Gaussian Avatars with Hierarchical Spatio-temporal Context
Nov 25, 20243D human avatars, through the use of canonical radiance fields and per-frame observed warping, enable high-fidelity rendering and animating. However, existing methods, which rely on either spatial SMPL(-X) poses or temporal embeddings, respectively suffer from coarse rendering quality or limited animation flexibility. To address these challenges, we propose GAST, a framework that unifies 3D human modeling with 3DGS by hierarchically integrating both spatial and temporal information. Specifically, we design a sequential conditioning framework for the non-rigid warping of the human body, under whose guidance more accurate 3D Gaussians can be obtained in the observation space. Moreover, the explicit properties of Gaussians allow us to embed richer sequential information, encompassing both the coarse sequence of human poses and finer per-vertex motion details. These sequence conditions are further sampled across different temporal scales, in a coarse-to-fine manner, ensuring unbiased inputs for non-rigid warping. Experimental results demonstrate that our method combined with hierarchical spatio-temporal modeling surpasses concurrent baselines, delivering both high-quality rendering and flexible animating capabilities.
Structure Consistent Gaussian Splatting with Matching Prior for Few-shot Novel View Synthesis
Nov 06, 2024



Despite the substantial progress of novel view synthesis, existing methods, either based on the Neural Radiance Fields (NeRF) or more recently 3D Gaussian Splatting (3DGS), suffer significant degradation when the input becomes sparse. Numerous efforts have been introduced to alleviate this problem, but they still struggle to synthesize satisfactory results efficiently, especially in the large scene. In this paper, we propose SCGaussian, a Structure Consistent Gaussian Splatting method using matching priors to learn 3D consistent scene structure. Considering the high interdependence of Gaussian attributes, we optimize the scene structure in two folds: rendering geometry and, more importantly, the position of Gaussian primitives, which is hard to be directly constrained in the vanilla 3DGS due to the non-structure property. To achieve this, we present a hybrid Gaussian representation. Besides the ordinary non-structure Gaussian primitives, our model also consists of ray-based Gaussian primitives that are bound to matching rays and whose optimization of their positions is restricted along the ray. Thus, we can utilize the matching correspondence to directly enforce the position of these Gaussian primitives to converge to the surface points where rays intersect. Extensive experiments on forward-facing, surrounding, and complex large scenes show the effectiveness of our approach with state-of-the-art performance and high efficiency. Code is available at https://github.com/prstrive/SCGaussian.
MVPGS: Excavating Multi-view Priors for Gaussian Splatting from Sparse Input Views
Sep 22, 2024
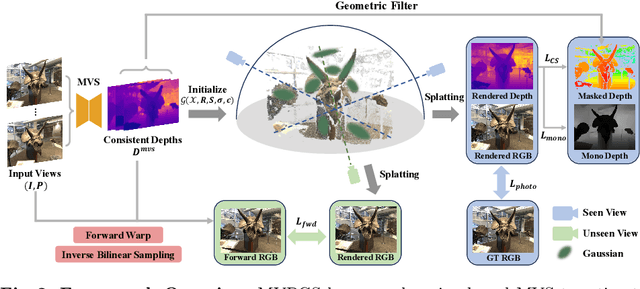
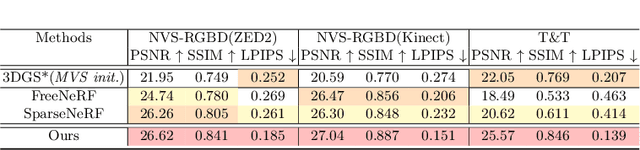
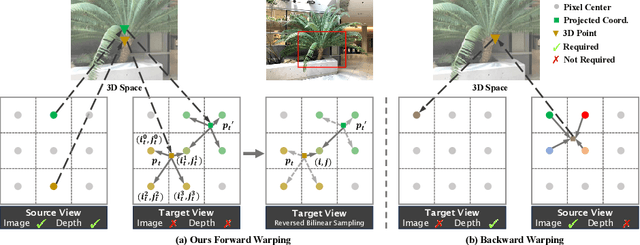
Recently, the Neural Radiance Field (NeRF) advancement has facilitated few-shot Novel View Synthesis (NVS), which is a significant challenge in 3D vision applications. Despite numerous attempts to reduce the dense input requirement in NeRF, it still suffers from time-consumed training and rendering processes. More recently, 3D Gaussian Splatting (3DGS) achieves real-time high-quality rendering with an explicit point-based representation. However, similar to NeRF, it tends to overfit the train views for lack of constraints. In this paper, we propose \textbf{MVPGS}, a few-shot NVS method that excavates the multi-view priors based on 3D Gaussian Splatting. We leverage the recent learning-based Multi-view Stereo (MVS) to enhance the quality of geometric initialization for 3DGS. To mitigate overfitting, we propose a forward-warping method for additional appearance constraints conforming to scenes based on the computed geometry. Furthermore, we introduce a view-consistent geometry constraint for Gaussian parameters to facilitate proper optimization convergence and utilize a monocular depth regularization as compensation. Experiments show that the proposed method achieves state-of-the-art performance with real-time rendering speed. Project page: https://zezeaaa.github.io/projects/MVPGS/