 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFree360: Layered Gaussian Splatting for Unbounded 360-Degree View Synthesis from Extremely Sparse and Unposed Views
Mar 31, 2025

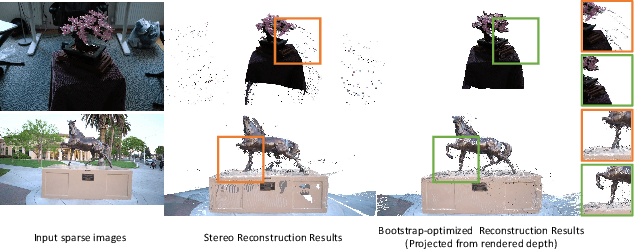

Neural rendering has demonstrated remarkable success in high-quality 3D neural reconstruction and novel view synthesis with dense input views and accurate poses. However, applying it to extremely sparse, unposed views in unbounded 360{\deg} scenes remains a challenging problem. In this paper, we propose a novel neural rendering framework to accomplish the unposed and extremely sparse-view 3D reconstruction in unbounded 360{\deg} scenes. To resolve the spatial ambiguity inherent in unbounded scenes with sparse input views, we propose a layered Gaussian-based representation to effectively model the scene with distinct spatial layers. By employing a dense stereo reconstruction model to recover coarse geometry, we introduce a layer-specific bootstrap optimization to refine the noise and fill occluded regions in the reconstruction. Furthermore, we propose an iterative fusion of reconstruction and generation alongside an uncertainty-aware training approach to facilitate mutual conditioning and enhancement between these two processes. Comprehensive experiments show that our approach outperforms existing state-of-the-art methods in terms of rendering quality and surface reconstruction accuracy. Project page: https://zju3dv.github.io/free360/
Unlocking Generalization Power in LiDAR Point Cloud Registration
Mar 13, 2025



In real-world environments, a LiDAR point cloud registration method with robust generalization capabilities (across varying distances and datasets) is crucial for ensuring safety in autonomous driving and other LiDAR-based applications. However, current methods fall short in achieving this level of generalization. To address these limitations, we propose UGP, a pruned framework designed to enhance generalization power for LiDAR point cloud registration. The core insight in UGP is the elimination of cross-attention mechanisms to improve generalization, allowing the network to concentrate on intra-frame feature extraction. Additionally, we introduce a progressive self-attention module to reduce ambiguity in large-scale scenes and integrate Bird's Eye View (BEV) features to incorporate semantic information about scene elements. Together, these enhancements significantly boost the network's generalization performance. We validated our approach through various generalization experiments in multiple outdoor scenes. In cross-distance generalization experiments on KITTI and nuScenes, UGP achieved state-of-the-art mean Registration Recall rates of 94.5% and 91.4%, respectively. In cross-dataset generalization from nuScenes to KITTI, UGP achieved a state-of-the-art mean Registration Recall of 90.9%. Code will be available at https://github.com/peakpang/UGP.
HyperGCT: A Dynamic Hyper-GNN-Learned Geometric Constraint for 3D Registration
Mar 04, 2025



Geometric constraints between feature matches are critical in 3D point cloud registration problems. Existing approaches typically model unordered matches as a consistency graph and sample consistent matches to generate hypotheses. However, explicit graph construction introduces noise, posing great challenges for handcrafted geometric constraints to render consistency among matches. To overcome this, we propose HyperGCT, a flexible dynamic Hyper-GNN-learned geometric constraint that leverages high-order consistency among 3D correspondences. To our knowledge, HyperGCT is the first method that mines robust geometric constraints from dynamic hypergraphs for 3D registration. By dynamically optimizing the hypergraph through vertex and edge feature aggregation, HyperGCT effectively captures the correlations among correspondences, leading to accurate hypothesis generation. Extensive experiments on 3DMatch, 3DLoMatch, KITTI-LC, and ETH show that HyperGCT achieves state-of-the-art performance. Furthermore, our method is robust to graph noise, demonstrating a significant advantage in terms of generalization. The code will be released.
3D Registration in 30 Years: A Survey
Dec 19, 2024



3D point cloud registration is a fundamental problem in computer vision, computer graphics, robotics, remote sensing, and etc. Over the last thirty years, we have witnessed the amazing advancement in this area with numerous kinds of solutions. Although a handful of relevant surveys have been conducted, their coverage is still limited. In this work, we present a comprehensive survey on 3D point cloud registration, covering a set of sub-areas such as pairwise coarse registration, pairwise fine registration, multi-view registration, cross-scale registration, and multi-instance registration. The datasets, evaluation metrics, method taxonomy, discussions of the merits and demerits, insightful thoughts of future directions are comprehensively presented in this survey. The regularly updated project page of the survey is available at https://github.com/Amyyyy11/3D-Registration-in-30-Years-A-Survey.
SplatLoc: 3D Gaussian Splatting-based Visual Localization for Augmented Reality
Sep 21, 2024



Visual localization plays an important role in the applications of Augmented Reality (AR), which enable AR devices to obtain their 6-DoF pose in the pre-build map in order to render virtual content in real scenes. However, most existing approaches can not perform novel view rendering and require large storage capacities for maps. To overcome these limitations, we propose an efficient visual localization method capable of high-quality rendering with fewer parameters. Specifically, our approach leverages 3D Gaussian primitives as the scene representation. To ensure precise 2D-3D correspondences for pose estimation, we develop an unbiased 3D scene-specific descriptor decoder for Gaussian primitives, distilled from a constructed feature volume. Additionally, we introduce a salient 3D landmark selection algorithm that selects a suitable primitive subset based on the saliency score for localization. We further regularize key Gaussian primitives to prevent anisotropic effects, which also improves localization performance. Extensive experiments on two widely used datasets demonstrate that our method achieves superior or comparable rendering and localization performance to state-of-the-art implicit-based visual localization approaches. Project page: \href{https://zju3dv.github.io/splatloc}{https://zju3dv.github.io/splatloc}.
GeneAvatar: Generic Expression-Aware Volumetric Head Avatar Editing from a Single Image
Apr 02, 2024



Recently, we have witnessed the explosive growth of various volumetric representations in modeling animatable head avatars. However, due to the diversity of frameworks, there is no practical method to support high-level applications like 3D head avatar editing across different representations. In this paper, we propose a generic avatar editing approach that can be universally applied to various 3DMM driving volumetric head avatars. To achieve this goal, we design a novel expression-aware modification generative model, which enables lift 2D editing from a single image to a consistent 3D modification field. To ensure the effectiveness of the generative modification process, we develop several techniques, including an expression-dependent modification distillation scheme to draw knowledge from the large-scale head avatar model and 2D facial texture editing tools, implicit latent space guidance to enhance model convergence, and a segmentation-based loss reweight strategy for fine-grained texture inversion. Extensive experiments demonstrate that our method delivers high-quality and consistent results across multiple expression and viewpoints. Project page: https://zju3dv.github.io/geneavatar/
Instance by Instance: An Iterative Framework for Multi-instance 3D Registration
Feb 06, 2024



Multi-instance registration is a challenging problem in computer vision and robotics, where multiple instances of an object need to be registered in a standard coordinate system. In this work, we propose the first iterative framework called instance-by-instance (IBI) for multi-instance 3D registration (MI-3DReg). It successively registers all instances in a given scenario, starting from the easiest and progressing to more challenging ones. Throughout the iterative process, outliers are eliminated continuously, leading to an increasing inlier rate for the remaining and more challenging instances. Under the IBI framework, we further propose a sparse-to-dense-correspondence-based multi-instance registration method (IBI-S2DC) to achieve robust MI-3DReg. Experiments on the synthetic and real datasets have demonstrated the effectiveness of IBI and suggested the new state-of-the-art performance of IBI-S2DC, e.g., our MHF1 is 12.02%/12.35% higher than the existing state-of-the-art method ECC on the synthetic/real datasets.
3D Registration with Maximal Cliques
May 18, 2023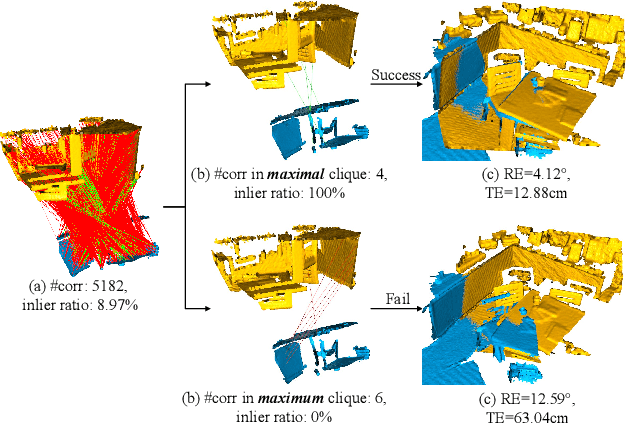



As a fundamental problem in computer vision, 3D point cloud registration (PCR) aims to seek the optimal pose to align a point cloud pair. In this paper, we present a 3D registration method with maximal cliques (MAC). The key insight is to loosen the previous maximum clique constraint, and mine more local consensus information in a graph for accurate pose hypotheses generation: 1) A compatibility graph is constructed to render the affinity relationship between initial correspondences. 2) We search for maximal cliques in the graph, each of which represents a consensus set. We perform node-guided clique selection then, where each node corresponds to the maximal clique with the greatest graph weight. 3) Transformation hypotheses are computed for the selected cliques by the SVD algorithm and the best hypothesis is used to perform registration. Extensive experiments on U3M, 3DMatch, 3DLoMatch and KITTI demonstrate that MAC effectively increases registration accuracy, outperforms various state-of-the-art methods and boosts the performance of deep-learned methods. MAC combined with deep-learned methods achieves state-of-the-art registration recall of 95.7% / 78.9% on 3DMatch / 3DLoMatch.
Attending to Emotional Narratives
Jul 08, 2019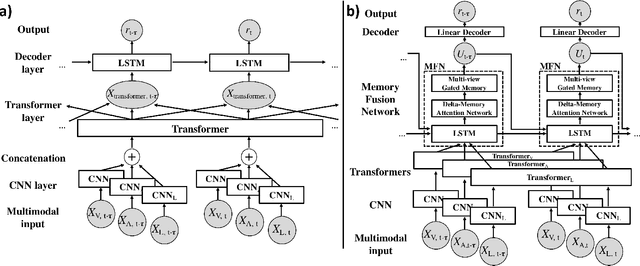
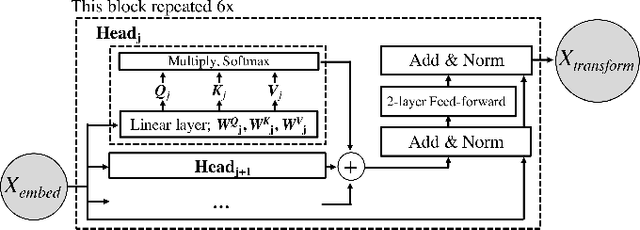
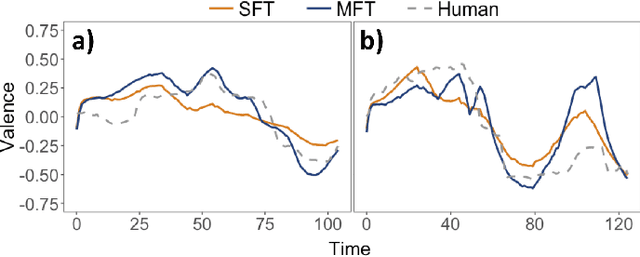

Attention mechanisms in deep neural networks have achieved excellent performance on sequence-prediction tasks. Here, we show that these recently-proposed attention-based mechanisms---in particular, the Transformer with its parallelizable self-attention layers, and the Memory Fusion Network with attention across modalities and time---also generalize well to multimodal time-series emotion recognition. Using a recently-introduced dataset of emotional autobiographical narratives, we adapt and apply these two attention mechanisms to predict emotional valence over time. Our models perform extremely well, in some cases reaching a performance comparable with human raters. We end with a discussion of the implications of attention mechanisms to affective computing.