 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuMesh++: Towards Versatile and Efficient Volumetric Editing with Disentangled Neural Mesh-based Implicit Field
Jun 17, 2026Recently neural implicit rendering techniques have evolved rapidly and demonstrated significant advantages in novel view synthesis and 3D scene reconstruction. However, existing neural rendering methods for editing purposes offer limited functionalities, e.g., rigid transformation and category-specific editing. In this paper, we present a novel mesh-based representation by encoding the neural radiance field with disentangled geometry, texture, and semantic codes on mesh vertices, which empowers a set of efficient and comprehensive editing functionalities, including mesh-guided geometry editing, designated texture editing with texture swapping, filling and painting operations, and semantic-guided editing. To this end, we develop several techniques including a novel local space parameterization to enhance rendering quality and training stability, a learnable modification color on vertex to improve the fidelity of texture editing, a spatial-aware optimization strategy to realize precise texture editing, and a semantic-aided region selection to ease the laborious annotation of implicit field editing. Extensive experiments and editing examples on both real and synthetic datasets demonstrate the superiority of our method on representation quality and editing ability. Project page: https://zju3dv.github.io/neumeshplusplus/
Seedance 2.0: Advancing Video Generation for World Complexity
Apr 15, 2026Seedance 2.0 is a new native multi-modal audio-video generation model, officially released in China in early February 2026. Compared with its predecessors, Seedance 1.0 and 1.5 Pro, Seedance 2.0 adopts a unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation. This allows it to support four input modalities: text, image, audio, and video, by integrating one of the most comprehensive suites of multi-modal content reference and editing capabilities available in the industry to date. It delivers substantial, well-rounded improvements across all key sub-dimensions of video and audio generation. In both expert evaluations and public user tests, the model has demonstrated performance on par with the leading levels in the field. Seedance 2.0 supports direct generation of audio-video content with durations ranging from 4 to 15 seconds, with native output resolutions of 480p and 720p. For multi-modal inputs as reference, its current open platform supports up to 3 video clips, 9 images, and 3 audio clips. In addition, we provide Seedance 2.0 Fast version, an accelerated variant of Seedance 2.0 designed to boost generation speed for low-latency scenarios. Seedance 2.0 has delivered significant improvements to its foundational generation capabilities and multi-modal generation performance, bringing an enhanced creative experience for end users.
Gen3R: 3D Scene Generation Meets Feed-Forward Reconstruction
Jan 07, 2026We present Gen3R, a method that bridges the strong priors of foundational reconstruction models and video diffusion models for scene-level 3D generation. We repurpose the VGGT reconstruction model to produce geometric latents by training an adapter on its tokens, which are regularized to align with the appearance latents of pre-trained video diffusion models. By jointly generating these disentangled yet aligned latents, Gen3R produces both RGB videos and corresponding 3D geometry, including camera poses, depth maps, and global point clouds. Experiments demonstrate that our approach achieves state-of-the-art results in single- and multi-image conditioned 3D scene generation. Additionally, our method can enhance the robustness of reconstruction by leveraging generative priors, demonstrating the mutual benefit of tightly coupling reconstruction and generative models.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
ImmerseGen: Agent-Guided Immersive World Generation with Alpha-Textured Proxies
Jun 18, 2025Automatic creation of 3D scenes for immersive VR presence has been a significant research focus for decades. However, existing methods often rely on either high-poly mesh modeling with post-hoc simplification or massive 3D Gaussians, resulting in a complex pipeline or limited visual realism. In this paper, we demonstrate that such exhaustive modeling is unnecessary for achieving compelling immersive experience. We introduce ImmerseGen, a novel agent-guided framework for compact and photorealistic world modeling. ImmerseGen represents scenes as hierarchical compositions of lightweight geometric proxies, i.e., simplified terrain and billboard meshes, and generates photorealistic appearance by synthesizing RGBA textures onto these proxies. Specifically, we propose terrain-conditioned texturing for user-centric base world synthesis, and RGBA asset texturing for midground and foreground scenery. This reformulation offers several advantages: (i) it simplifies modeling by enabling agents to guide generative models in producing coherent textures that integrate seamlessly with the scene; (ii) it bypasses complex geometry creation and decimation by directly synthesizing photorealistic textures on proxies, preserving visual quality without degradation; (iii) it enables compact representations suitable for real-time rendering on mobile VR headsets. To automate scene creation from text prompts, we introduce VLM-based modeling agents enhanced with semantic grid-based analysis for improved spatial reasoning and accurate asset placement. ImmerseGen further enriches scenes with dynamic effects and ambient audio to support multisensory immersion. Experiments on scene generation and live VR showcases demonstrate that ImmerseGen achieves superior photorealism, spatial coherence and rendering efficiency compared to prior methods. Project webpage: https://immersegen.github.io.
HiScene: Creating Hierarchical 3D Scenes with Isometric View Generation
Apr 17, 2025Scene-level 3D generation represents a critical frontier in multimedia and computer graphics, yet existing approaches either suffer from limited object categories or lack editing flexibility for interactive applications. In this paper, we present HiScene, a novel hierarchical framework that bridges the gap between 2D image generation and 3D object generation and delivers high-fidelity scenes with compositional identities and aesthetic scene content. Our key insight is treating scenes as hierarchical "objects" under isometric views, where a room functions as a complex object that can be further decomposed into manipulatable items. This hierarchical approach enables us to generate 3D content that aligns with 2D representations while maintaining compositional structure. To ensure completeness and spatial alignment of each decomposed instance, we develop a video-diffusion-based amodal completion technique that effectively handles occlusions and shadows between objects, and introduce shape prior injection to ensure spatial coherence within the scene. Experimental results demonstrate that our method produces more natural object arrangements and complete object instances suitable for interactive applications, while maintaining physical plausibility and alignment with user inputs.
DiffSplat: Repurposing Image Diffusion Models for Scalable Gaussian Splat Generation
Jan 28, 2025Recent advancements in 3D content generation from text or a single image struggle with limited high-quality 3D datasets and inconsistency from 2D multi-view generation. We introduce DiffSplat, a novel 3D generative framework that natively generates 3D Gaussian splats by taming large-scale text-to-image diffusion models. It differs from previous 3D generative models by effectively utilizing web-scale 2D priors while maintaining 3D consistency in a unified model. To bootstrap the training, a lightweight reconstruction model is proposed to instantly produce multi-view Gaussian splat grids for scalable dataset curation. In conjunction with the regular diffusion loss on these grids, a 3D rendering loss is introduced to facilitate 3D coherence across arbitrary views. The compatibility with image diffusion models enables seamless adaptions of numerous techniques for image generation to the 3D realm. Extensive experiments reveal the superiority of DiffSplat in text- and image-conditioned generation tasks and downstream applications. Thorough ablation studies validate the efficacy of each critical design choice and provide insights into the underlying mechanism.
TexPro: Text-guided PBR Texturing with Procedural Material Modeling
Oct 21, 2024
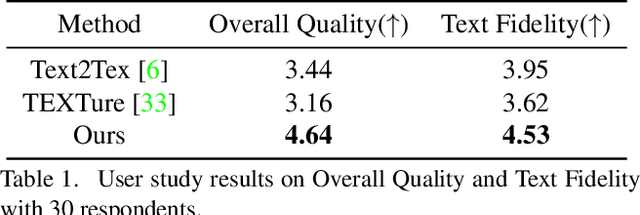
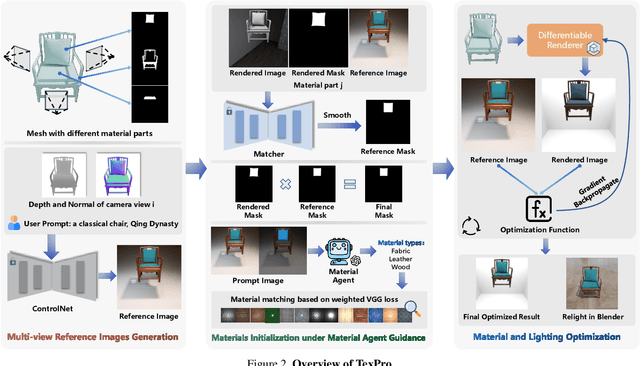
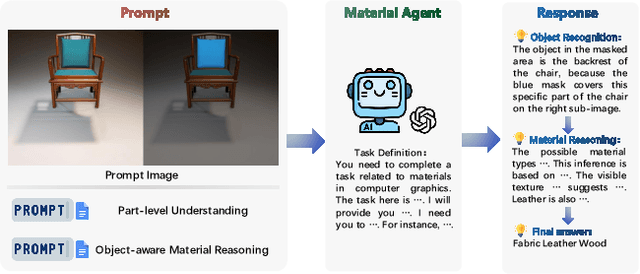
In this paper, we present TexPro, a novel method for high-fidelity material generation for input 3D meshes given text prompts. Unlike existing text-conditioned texture generation methods that typically generate RGB textures with baked lighting, TexPro is able to produce diverse texture maps via procedural material modeling, which enables physical-based rendering, relighting, and additional benefits inherent to procedural materials. Specifically, we first generate multi-view reference images given the input textual prompt by employing the latest text-to-image model. We then derive texture maps through a rendering-based optimization with recent differentiable procedural materials. To this end, we design several techniques to handle the misalignment between the generated multi-view images and 3D meshes, and introduce a novel material agent that enhances material classification and matching by exploring both part-level understanding and object-aware material reasoning. Experiments demonstrate the superiority of the proposed method over existing SOTAs and its capability of relighting.
4K4DGen: Panoramic 4D Generation at 4K Resolution
Jun 19, 2024
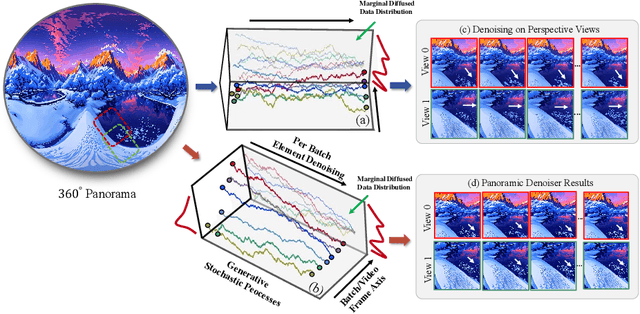

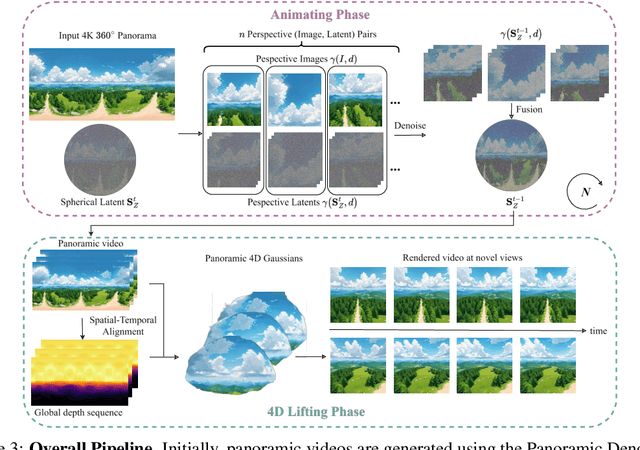
The blooming of virtual reality and augmented reality (VR/AR) technologies has driven an increasing demand for the creation of high-quality, immersive, and dynamic environments. However, existing generative techniques either focus solely on dynamic objects or perform outpainting from a single perspective image, failing to meet the needs of VR/AR applications. In this work, we tackle the challenging task of elevating a single panorama to an immersive 4D experience. For the first time, we demonstrate the capability to generate omnidirectional dynamic scenes with 360-degree views at 4K resolution, thereby providing an immersive user experience. Our method introduces a pipeline that facilitates natural scene animations and optimizes a set of 4D Gaussians using efficient splatting techniques for real-time exploration. To overcome the lack of scene-scale annotated 4D data and models, especially in panoramic formats, we propose a novel Panoramic Denoiser that adapts generic 2D diffusion priors to animate consistently in 360-degree images, transforming them into panoramic videos with dynamic scenes at targeted regions. Subsequently, we elevate the panoramic video into a 4D immersive environment while preserving spatial and temporal consistency. By transferring prior knowledge from 2D models in the perspective domain to the panoramic domain and the 4D lifting with spatial appearance and geometry regularization, we achieve high-quality Panorama-to-4D generation at a resolution of (4096 $\times$ 2048) for the first time. See the project website at https://4k4dgen.github.io.
Coin3D: Controllable and Interactive 3D Assets Generation with Proxy-Guided Conditioning
May 13, 2024As humans, we aspire to create media content that is both freely willed and readily controlled. Thanks to the prominent development of generative techniques, we now can easily utilize 2D diffusion methods to synthesize images controlled by raw sketch or designated human poses, and even progressively edit/regenerate local regions with masked inpainting. However, similar workflows in 3D modeling tasks are still unavailable due to the lack of controllability and efficiency in 3D generation. In this paper, we present a novel controllable and interactive 3D assets modeling framework, named Coin3D. Coin3D allows users to control the 3D generation using a coarse geometry proxy assembled from basic shapes, and introduces an interactive generation workflow to support seamless local part editing while delivering responsive 3D object previewing within a few seconds. To this end, we develop several techniques, including the 3D adapter that applies volumetric coarse shape control to the diffusion model, proxy-bounded editing strategy for precise part editing, progressive volume cache to support responsive preview, and volume-SDS to ensure consistent mesh reconstruction. Extensive experiments of interactive generation and editing on diverse shape proxies demonstrate that our method achieves superior controllability and flexibility in the 3D assets generation task.