 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR2AoP: Reliable and Robust Angle of Progression Estimation from Intrapartum Ultrasound
May 20, 2026Accurate estimation of the Angle of Progression (AoP) from intrapartum transperineal ultrasound is critical for objective assessment of labor progression, yet remains highly sensitive to imaging noise, boundary ambiguities, and the geometric amplification of local segmentation errors. We propose R2AoP, a reliable and robust AoP estimation framework that integrates structurally informed segmentation and confidence-guided geometric modeling to achieve stable and reproducible measurements. A three-branch local-structure-enhanced backbone improves the delineation of the pubic symphysis (PS) and fetal head (FH), while confidence-weighted contour fitting explicitly suppresses the influence of unreliable boundary points in AoP computation. To further improve performance under heterogeneous acquisition conditions, we introduce a lightweight geometry-reliable test-time adaptation strategy as an auxiliary component, enabling stable inference without target annotations. Extensive evaluations on multi-center benchmarks demonstrate consistent reductions in AoP error and boundary metrics compared with state-of-the-art AoP methods. Our source code is available at https://github.com/baiyou1234/R2AoP.
INFANiTE: Implicit Neural representation for high-resolution Fetal brain spatio-temporal Atlas learNing from clinical Thick-slicE MRI
May 11, 2026Spatio-temporal fetal brain atlases are important for characterizing normative neurodevelopment and identifying congenital anomalies. However, existing atlas construction pipelines necessitate days for slice-to-volume reconstruction (SVR) to generate high-resolution 3D brain volumes and several additional days for iterative volume registration, thereby rendering atlas construction from large-scale cohorts prohibitively impractical. We address these limitations with INFANiTE, an Implicit Neural Representation (INR) framework for high-resolution Fetal brain spatio-temporal Atlas learNing from clinical Thick-slicE MRI scans, bypassing both the costly SVR and the iterative non-rigid registration steps entirely, thereby substantially accelerating atlas construction. Extensive experiments demonstrate that INFANiTE outperforms existing baselines in subject consistency, reference fidelity, intrinsic quality and biological plausibility, even under challenging sparse-data settings. Additionally, INFANiTE reduces the end-to-end processing time (i.e., from raw scans to the final atlas) from days to hours compared to the traditional 3D volume-based pipeline (e.g., SyGN), facilitating large-scale population-level fetal brain analysis. Our code is publicly available at: https://anonymous.4open.science/r/INFANiTE-5D74
Annotation-free deep learning for detection and segmentation of fetal germinal matrix-intraventricular hemorrhage in brain MRI
May 10, 2026Background: Prenatal germinal matrix-intraventricular hemorrhage (GMH-IVH) is a leading cause of infant mortality and neurodevelopmental impairment. Manual diagnosis and lesion segmentation are labor-intensive and error-prone. Deep learning models offer potential for automation but typically require large annotated datasets, which are challenging to obtain. Purpose: To develop and validate an annotation-free deep learning framework for automated detection and segmentation of GMH-IVH on brain MRI. Materials and Methods: This retrospective study analyzed 2D T2-weighted MRI data from pregnant women collected from October 2015 to October 2023 at one hospital (internal validation) and two hospitals (external validation). Eligible participants included healthy fetuses and those with GMH-IVH. FreeHemoSeg was developed and trained using pseudo GMH-IVH images synthesized from normal fetal data guided by medical priors. Primary outcomes included diagnostic accuracy (area under the ROC curve [AUROC], sensitivity, specificity) and segmentation accuracy (Dice similarity coefficient [DSC]). A reader study evaluated clinical utility. Results: A total of 1674 stacks from 558 pregnant women were analyzed. FreeHemoSeg achieved the highest performance in both internal (sensitivity: 0.914, 95% CI 0.869-0.945; specificity: 0.966, 95% CI 0.946-0.978; DSC: 0.559, 95% CI 0.546-0.571) and external validation (sensitivity: 0.824, 95% CI 0.739-0.885; specificity: 0.943, 95% CI 0.913-0.964; DSC: 0.512, 95% CI 0.497-0.526), outperforming supervised and unsupervised methods. FreeHemoSeg assistance improved radiologists' sensitivity (from 0.882 to 0.941-1.000) and diagnostic confidence while reducing interpretation time by 16.0-52.7%. Conclusion: FreeHemoSeg accurately detects and localizes fetal brain hemorrhages without annotated training data, enabling earlier diagnosis and supporting timely clinical management.
DSAGL: Dual-Stream Attention-Guided Learning for Weakly Supervised Whole Slide Image Classification
May 29, 2025Whole-slide images (WSIs) are critical for cancer diagnosis due to their ultra-high resolution and rich semantic content. However, their massive size and the limited availability of fine-grained annotations pose substantial challenges for conventional supervised learning. We propose DSAGL (Dual-Stream Attention-Guided Learning), a novel weakly supervised classification framework that combines a teacher-student architecture with a dual-stream design. DSAGL explicitly addresses instance-level ambiguity and bag-level semantic consistency by generating multi-scale attention-based pseudo labels and guiding instance-level learning. A shared lightweight encoder (VSSMamba) enables efficient long-range dependency modeling, while a fusion-attentive module (FASA) enhances focus on sparse but diagnostically relevant regions. We further introduce a hybrid loss to enforce mutual consistency between the two streams. Experiments on CIFAR-10, NCT-CRC, and TCGA-Lung datasets demonstrate that DSAGL consistently outperforms state-of-the-art MIL baselines, achieving superior discriminative performance and robustness under weak supervision.
CoProSketch: Controllable and Progressive Sketch Generation with Diffusion Model
Apr 11, 2025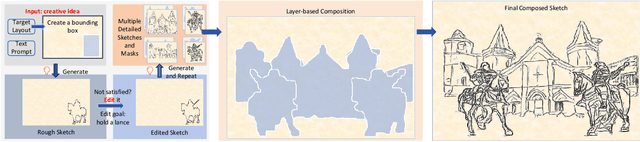
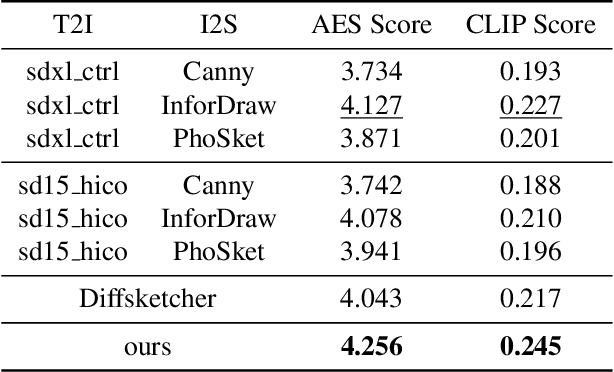
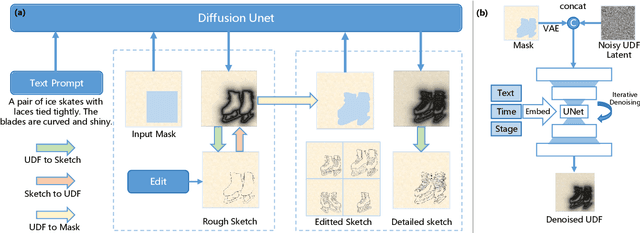
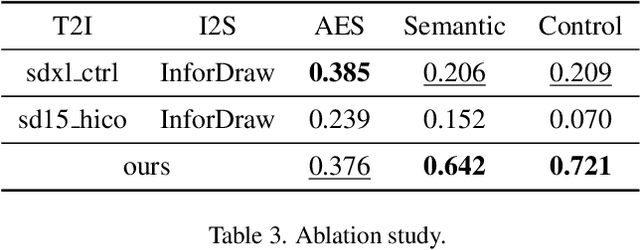
Sketches serve as fundamental blueprints in artistic creation because sketch editing is easier and more intuitive than pixel-level RGB image editing for painting artists, yet sketch generation remains unexplored despite advancements in generative models. We propose a novel framework CoProSketch, providing prominent controllability and details for sketch generation with diffusion models. A straightforward method is fine-tuning a pretrained image generation diffusion model with binarized sketch images. However, we find that the diffusion models fail to generate clear binary images, which makes the produced sketches chaotic. We thus propose to represent the sketches by unsigned distance field (UDF), which is continuous and can be easily decoded to sketches through a lightweight network. With CoProSketch, users generate a rough sketch from a bounding box and a text prompt. The rough sketch can be manually edited and fed back into the model for iterative refinement and will be decoded to a detailed sketch as the final result. Additionally, we curate the first large-scale text-sketch paired dataset as the training data. Experiments demonstrate superior semantic consistency and controllability over baselines, offering a practical solution for integrating user feedback into generative workflows.
OpticFusion: Multi-Modal Neural Implicit 3D Reconstruction of Microstructures by Fusing White Light Interferometry and Optical Microscopy
Jan 16, 2025White Light Interferometry (WLI) is a precise optical tool for measuring the 3D topography of microstructures. However, conventional WLI cannot capture the natural color of a sample's surface, which is essential for many microscale research applications that require both 3D geometry and color information. Previous methods have attempted to overcome this limitation by modifying WLI hardware and analysis software, but these solutions are often costly. In this work, we address this challenge from a computer vision multi-modal reconstruction perspective for the first time. We introduce OpticFusion, a novel approach that uses an additional digital optical microscope (OM) to achieve 3D reconstruction with natural color textures using multi-view WLI and OM images. Our method employs a two-step data association process to obtain the poses of WLI and OM data. By leveraging the neural implicit representation, we fuse multi-modal data and apply color decomposition technology to extract the sample's natural color. Tested on our multi-modal dataset of various microscale samples, OpticFusion achieves detailed 3D reconstructions with color textures. Our method provides an effective tool for practical applications across numerous microscale research fields. The source code and our real-world dataset are available at https://github.com/zju3dv/OpticFusion.
GS-DiT: Advancing Video Generation with Pseudo 4D Gaussian Fields through Efficient Dense 3D Point Tracking
Jan 05, 2025



4D video control is essential in video generation as it enables the use of sophisticated lens techniques, such as multi-camera shooting and dolly zoom, which are currently unsupported by existing methods. Training a video Diffusion Transformer (DiT) directly to control 4D content requires expensive multi-view videos. Inspired by Monocular Dynamic novel View Synthesis (MDVS) that optimizes a 4D representation and renders videos according to different 4D elements, such as camera pose and object motion editing, we bring pseudo 4D Gaussian fields to video generation. Specifically, we propose a novel framework that constructs a pseudo 4D Gaussian field with dense 3D point tracking and renders the Gaussian field for all video frames. Then we finetune a pretrained DiT to generate videos following the guidance of the rendered video, dubbed as GS-DiT. To boost the training of the GS-DiT, we also propose an efficient Dense 3D Point Tracking (D3D-PT) method for the pseudo 4D Gaussian field construction. Our D3D-PT outperforms SpatialTracker, the state-of-the-art sparse 3D point tracking method, in accuracy and accelerates the inference speed by two orders of magnitude. During the inference stage, GS-DiT can generate videos with the same dynamic content while adhering to different camera parameters, addressing a significant limitation of current video generation models. GS-DiT demonstrates strong generalization capabilities and extends the 4D controllability of Gaussian splatting to video generation beyond just camera poses. It supports advanced cinematic effects through the manipulation of the Gaussian field and camera intrinsics, making it a powerful tool for creative video production. Demos are available at https://wkbian.github.io/Projects/GS-DiT/.
A Global Depth-Range-Free Multi-View Stereo Transformer Network with Pose Embedding
Nov 04, 2024



In this paper, we propose a novel multi-view stereo (MVS) framework that gets rid of the depth range prior. Unlike recent prior-free MVS methods that work in a pair-wise manner, our method simultaneously considers all the source images. Specifically, we introduce a Multi-view Disparity Attention (MDA) module to aggregate long-range context information within and across multi-view images. Considering the asymmetry of the epipolar disparity flow, the key to our method lies in accurately modeling multi-view geometric constraints. We integrate pose embedding to encapsulate information such as multi-view camera poses, providing implicit geometric constraints for multi-view disparity feature fusion dominated by attention. Additionally, we construct corresponding hidden states for each source image due to significant differences in the observation quality of the same pixel in the reference frame across multiple source frames. We explicitly estimate the quality of the current pixel corresponding to sampled points on the epipolar line of the source image and dynamically update hidden states through the uncertainty estimation module. Extensive results on the DTU dataset and Tanks&Temple benchmark demonstrate the effectiveness of our method. The code is available at our project page: https://zju3dv.github.io/GD-PoseMVS/.
ETO:Efficient Transformer-based Local Feature Matching by Organizing Multiple Homography Hypotheses
Oct 31, 2024



We tackle the efficiency problem of learning local feature matching. Recent advancements have given rise to purely CNN-based and transformer-based approaches, each augmented with deep learning techniques. While CNN-based methods often excel in matching speed, transformer-based methods tend to provide more accurate matches. We propose an efficient transformer-based network architecture for local feature matching. This technique is built on constructing multiple homography hypotheses to approximate the continuous correspondence in the real world and uni-directional cross-attention to accelerate the refinement. On the YFCC100M dataset, our matching accuracy is competitive with LoFTR, a state-of-the-art transformer-based architecture, while the inference speed is boosted to 4 times, even outperforming the CNN-based methods. Comprehensive evaluations on other open datasets such as Megadepth, ScanNet, and HPatches demonstrate our method's efficacy, highlighting its potential to significantly enhance a wide array of downstream applications.
BlinkVision: A Benchmark for Optical Flow, Scene Flow and Point Tracking Estimation using RGB Frames and Events
Oct 27, 2024Recent advances in event-based vision suggest that these systems complement traditional cameras by providing continuous observation without frame rate limitations and a high dynamic range, making them well-suited for correspondence tasks such as optical flow and point tracking. However, there is still a lack of comprehensive benchmarks for correspondence tasks that include both event data and images. To address this gap, we propose BlinkVision, a large-scale and diverse benchmark with multiple modalities and dense correspondence annotations. BlinkVision offers several valuable features: 1) Rich modalities: It includes both event data and RGB images. 2) Extensive annotations: It provides dense per-pixel annotations covering optical flow, scene flow, and point tracking. 3) Large vocabulary: It contains 410 everyday categories, sharing common classes with popular 2D and 3D datasets like LVIS and ShapeNet. 4) Naturalistic: It delivers photorealistic data and covers various naturalistic factors, such as camera shake and deformation. BlinkVision enables extensive benchmarks on three types of correspondence tasks (optical flow, point tracking, and scene flow estimation) for both image-based and event-based methods, offering new observations, practices, and insights for future research. The benchmark website is https://www.blinkvision.net/.