 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeETO:Efficient Transformer-based Local Feature Matching by Organizing Multiple Homography Hypotheses
Oct 31, 2024



We tackle the efficiency problem of learning local feature matching. Recent advancements have given rise to purely CNN-based and transformer-based approaches, each augmented with deep learning techniques. While CNN-based methods often excel in matching speed, transformer-based methods tend to provide more accurate matches. We propose an efficient transformer-based network architecture for local feature matching. This technique is built on constructing multiple homography hypotheses to approximate the continuous correspondence in the real world and uni-directional cross-attention to accelerate the refinement. On the YFCC100M dataset, our matching accuracy is competitive with LoFTR, a state-of-the-art transformer-based architecture, while the inference speed is boosted to 4 times, even outperforming the CNN-based methods. Comprehensive evaluations on other open datasets such as Megadepth, ScanNet, and HPatches demonstrate our method's efficacy, highlighting its potential to significantly enhance a wide array of downstream applications.
BlinkTrack: Feature Tracking over 100 FPS via Events and Images
Sep 26, 2024Feature tracking is crucial for, structure from motion (SFM), simultaneous localization and mapping (SLAM), object tracking and various computer vision tasks. Event cameras, known for their high temporal resolution and ability to capture asynchronous changes, have gained significant attention for their potential in feature tracking, especially in challenging conditions. However, event cameras lack the fine-grained texture information that conventional cameras provide, leading to error accumulation in tracking. To address this, we propose a novel framework, BlinkTrack, which integrates event data with RGB images for high-frequency feature tracking. Our method extends the traditional Kalman filter into a learning-based framework, utilizing differentiable Kalman filters in both event and image branches. This approach improves single-modality tracking, resolves ambiguities, and supports asynchronous data fusion. We also introduce new synthetic and augmented datasets to better evaluate our model. Experimental results indicate that BlinkTrack significantly outperforms existing event-based methods, exceeding 100 FPS with preprocessed event data and 80 FPS with multi-modality data.
NIS-SLAM: Neural Implicit Semantic RGB-D SLAM for 3D Consistent Scene Understanding
Jul 30, 2024



In recent years, the paradigm of neural implicit representations has gained substantial attention in the field of Simultaneous Localization and Mapping (SLAM). However, a notable gap exists in the existing approaches when it comes to scene understanding. In this paper, we introduce NIS-SLAM, an efficient neural implicit semantic RGB-D SLAM system, that leverages a pre-trained 2D segmentation network to learn consistent semantic representations. Specifically, for high-fidelity surface reconstruction and spatial consistent scene understanding, we combine high-frequency multi-resolution tetrahedron-based features and low-frequency positional encoding as the implicit scene representations. Besides, to address the inconsistency of 2D segmentation results from multiple views, we propose a fusion strategy that integrates the semantic probabilities from previous non-keyframes into keyframes to achieve consistent semantic learning. Furthermore, we implement a confidence-based pixel sampling and progressive optimization weight function for robust camera tracking. Extensive experimental results on various datasets show the better or more competitive performance of our system when compared to other existing neural dense implicit RGB-D SLAM approaches. Finally, we also show that our approach can be used in augmented reality applications. Project page: \href{https://zju3dv.github.io/nis_slam}{https://zju3dv.github.io/nis\_slam}.
CG-SLAM: Efficient Dense RGB-D SLAM in a Consistent Uncertainty-aware 3D Gaussian Field
Mar 24, 2024
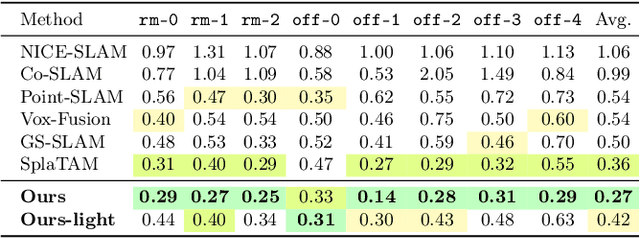
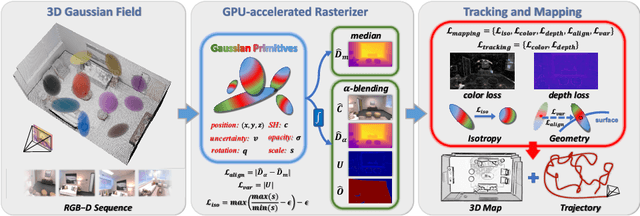
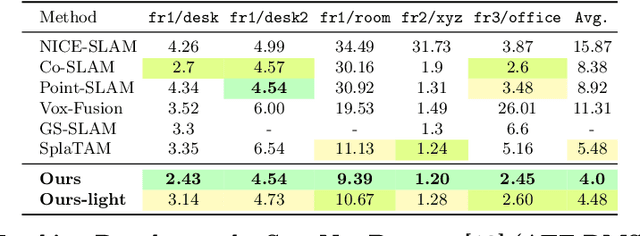
Recently neural radiance fields (NeRF) have been widely exploited as 3D representations for dense simultaneous localization and mapping (SLAM). Despite their notable successes in surface modeling and novel view synthesis, existing NeRF-based methods are hindered by their computationally intensive and time-consuming volume rendering pipeline. This paper presents an efficient dense RGB-D SLAM system, i.e., CG-SLAM, based on a novel uncertainty-aware 3D Gaussian field with high consistency and geometric stability. Through an in-depth analysis of Gaussian Splatting, we propose several techniques to construct a consistent and stable 3D Gaussian field suitable for tracking and mapping. Additionally, a novel depth uncertainty model is proposed to ensure the selection of valuable Gaussian primitives during optimization, thereby improving tracking efficiency and accuracy. Experiments on various datasets demonstrate that CG-SLAM achieves superior tracking and mapping performance with a notable tracking speed of up to 15 Hz. We will make our source code publicly available. Project page: https://zju3dv.github.io/cg-slam.
Multiresolution Dual-Polynomial Decomposition Approach for Optimized Characterization of Motor Intent in Myoelectric Control Systems
Nov 10, 2022



Surface electromyogram (sEMG) is arguably the most sought-after physiological signal with a broad spectrum of biomedical applications, especially in miniaturized rehabilitation robots such as multifunctional prostheses. The widespread use of sEMG to drive pattern recognition (PR)-based control schemes is primarily due to its rich motor information content and non-invasiveness. Moreover, sEMG recordings exhibit non-linear and non-uniformity properties with inevitable interferences that distort intrinsic characteristics of the signal, precluding existing signal processing methods from yielding requisite motor control information. Therefore, we propose a multiresolution decomposition driven by dual-polynomial interpolation (MRDPI) technique for adequate denoising and reconstruction of multi-class EMG signals to guarantee the dual-advantage of enhanced signal quality and motor information preservation. Parameters for optimal MRDPI configuration were constructed across combinations of thresholding estimation schemes and signal resolution levels using EMG datasets of amputees who performed up to 22 predefined upper-limb motions acquired in-house and from the public NinaPro database. Experimental results showed that the proposed method yielded signals that led to consistent and significantly better decoding performance for all metrics compared to existing methods across features, classifiers, and datasets, offering a potential solution for practical deployment of intuitive EMG-PR-based control schemes for multifunctional prostheses and other miniaturized rehabilitation robotic systems that utilize myoelectric signals as control inputs.
Generative Category-Level Shape and Pose Estimation with Semantic Primitives
Oct 03, 2022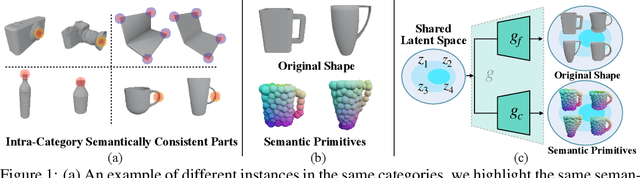
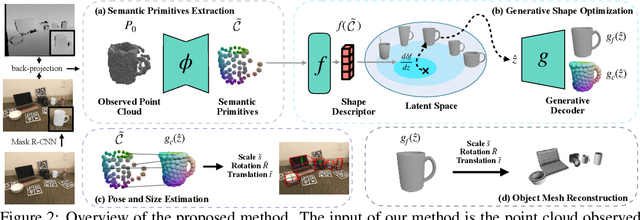
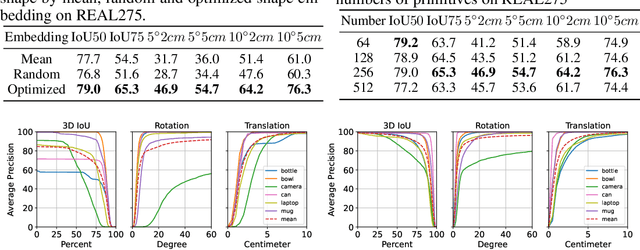

Empowering autonomous agents with 3D understanding for daily objects is a grand challenge in robotics applications. When exploring in an unknown environment, existing methods for object pose estimation are still not satisfactory due to the diversity of object shapes. In this paper, we propose a novel framework for category-level object shape and pose estimation from a single RGB-D image. To handle the intra-category variation, we adopt a semantic primitive representation that encodes diverse shapes into a unified latent space, which is the key to establish reliable correspondences between observed point clouds and estimated shapes. Then, by using a SIM(3)-invariant shape descriptor, we gracefully decouple the shape and pose of an object, thus supporting latent shape optimization of target objects in arbitrary poses. Extensive experiments show that the proposed method achieves SOTA pose estimation performance and better generalization in the real-world dataset. Code and video are available at https://zju3dv.github.io/gCasp
Analyzing the Impact of Varied Window Hyper-parameters on Deep CNN for sEMG based Motion Intent Classification
Sep 13, 2022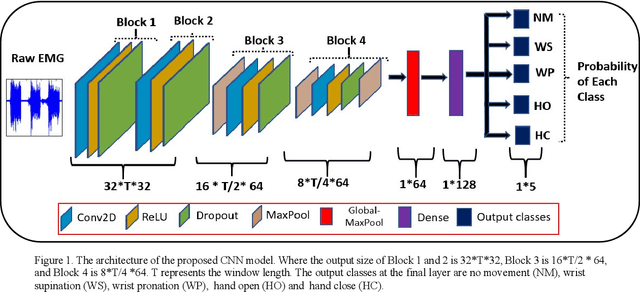
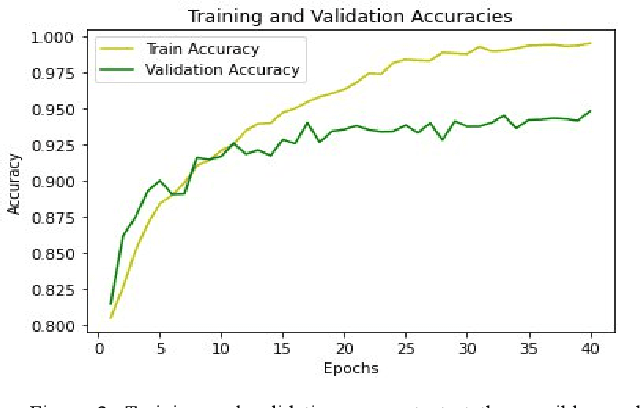
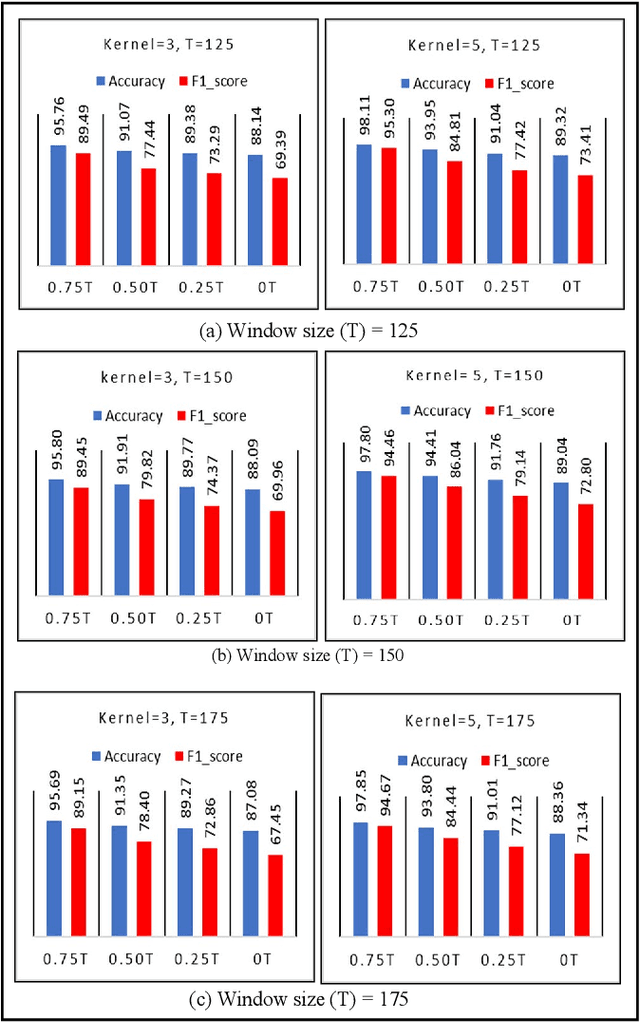
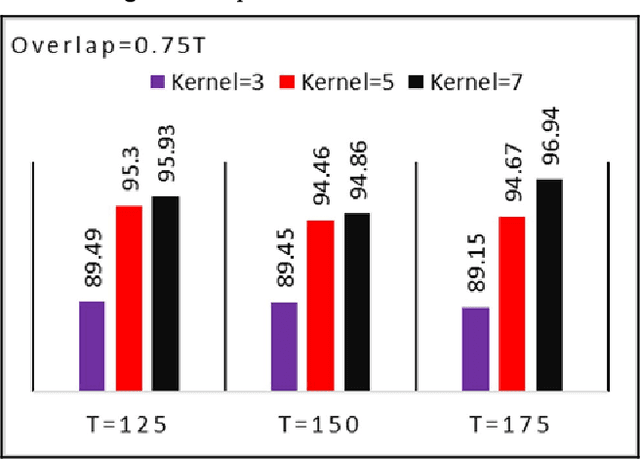
The use of deep neural networks in electromyogram (EMG) based prostheses control provides a promising alternative to the hand-crafted features by automatically learning muscle activation patterns from the EMG signals. Meanwhile, the use of raw EMG signals as input to convolution neural networks (CNN) offers a simple, fast, and ideal scheme for effective control of prostheses. Therefore, this study investigates the relationship between window length and overlap, which may influence the generation of robust raw EMG 2-dimensional (2D) signals for application in CNN. And a rule of thumb for a proper combination of these parameters that could guarantee optimal network performance was derived. Moreover, we investigate the relationship between the CNN receptive window size and the raw EMG signal size. Experimental results show that the performance of the CNN increases with the increase in overlap within the generated signals, with the highest improvement of 9.49% accuracy and 23.33% F1-score realized when the overlap is 75% of the window length. Similarly, the network performance increases with the increase in receptive window (kernel) size. Findings from this study suggest that a combination of 75% overlap in 2D EMG signals and wider network kernels may provide ideal motor intents classification for adequate EMG-CNN based prostheses control scheme.