 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroCLIP: Brain-Inspired Prompt Tuning for EEG-to-Image Multimodal Contrastive Learning
Nov 12, 2025Recent advances in brain-inspired artificial intelligence have sought to align neural signals with visual semantics using multimodal models such as CLIP. However, existing methods often treat CLIP as a static feature extractor, overlooking its adaptability to neural representations and the inherent physiological-symbolic gap in EEG-image alignment. To address these challenges, we present NeuroCLIP, a prompt tuning framework tailored for EEG-to-image contrastive learning. Our approach introduces three core innovations: (1) We design a dual-stream visual embedding pipeline that combines dynamic filtering and token-level fusion to generate instance-level adaptive prompts, which guide the adjustment of patch embedding tokens based on image content, thereby enabling fine-grained modulation of visual representations under neural constraints; (2) We are the first to introduce visual prompt tokens into EEG-image alignment, acting as global, modality-level prompts that work in conjunction with instance-level adjustments. These visual prompt tokens are inserted into the Transformer architecture to facilitate neural-aware adaptation and parameter optimization at a global level; (3) Inspired by neuroscientific principles of human visual encoding, we propose a refined contrastive loss that better model the semantic ambiguity and cross-modal noise present in EEG signals. On the THINGS-EEG2 dataset, NeuroCLIP achieves a Top-1 accuracy of 63.2% in zero-shot image retrieval, surpassing the previous best method by +12.3%, and demonstrates strong generalization under inter-subject conditions (+4.6% Top-1), highlighting the potential of physiology-aware prompt tuning for bridging brain signals and visual semantics.
Integrating Biological and Machine Intelligence: Attention Mechanisms in Brain-Computer Interfaces
Feb 26, 2025With the rapid advancement of deep learning, attention mechanisms have become indispensable in electroencephalography (EEG) signal analysis, significantly enhancing Brain-Computer Interface (BCI) applications. This paper presents a comprehensive review of traditional and Transformer-based attention mechanisms, their embedding strategies, and their applications in EEG-based BCI, with a particular emphasis on multimodal data fusion. By capturing EEG variations across time, frequency, and spatial channels, attention mechanisms improve feature extraction, representation learning, and model robustness. These methods can be broadly categorized into traditional attention mechanisms, which typically integrate with convolutional and recurrent networks, and Transformer-based multi-head self-attention, which excels in capturing long-range dependencies. Beyond single-modality analysis, attention mechanisms also enhance multimodal EEG applications, facilitating effective fusion between EEG and other physiological or sensory data. Finally, we discuss existing challenges and emerging trends in attention-based EEG modeling, highlighting future directions for advancing BCI technology. This review aims to provide valuable insights for researchers seeking to leverage attention mechanisms for improved EEG interpretation and application.
NSSI-Net: Multi-Concept Generative Adversarial Network for Non-Suicidal Self-Injury Detection Using High-Dimensional EEG Signals in a Semi-Supervised Learning Framework
Oct 16, 2024
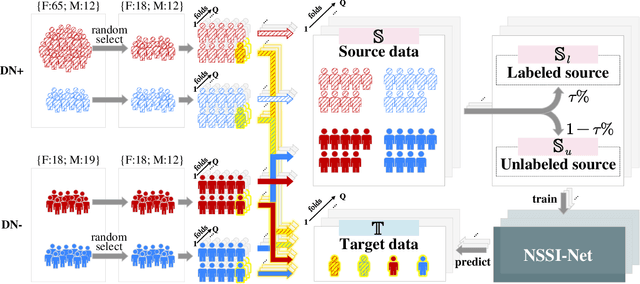
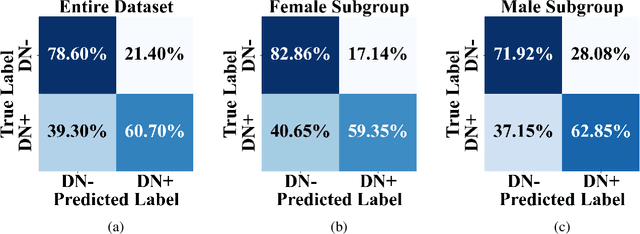

Non-suicidal self-injury (NSSI) is a serious threat to the physical and mental health of adolescents, significantly increasing the risk of suicide and attracting widespread public concern. Electroencephalography (EEG), as an objective tool for identifying brain disorders, holds great promise. However, extracting meaningful and reliable features from high-dimensional EEG data, especially by integrating spatiotemporal brain dynamics into informative representations, remains a major challenge. In this study, we introduce an advanced semi-supervised adversarial network, NSSI-Net, to effectively model EEG features related to NSSI. NSSI-Net consists of two key modules: a spatial-temporal feature extraction module and a multi-concept discriminator. In the spatial-temporal feature extraction module, an integrated 2D convolutional neural network (2D-CNN) and a bi-directional Gated Recurrent Unit (BiGRU) are used to capture both spatial and temporal dynamics in EEG data. In the multi-concept discriminator, signal, gender, domain, and disease levels are fully explored to extract meaningful EEG features, considering individual, demographic, disease variations across a diverse population. Based on self-collected NSSI data (n=114), the model's effectiveness and reliability are demonstrated, with a 7.44% improvement in performance compared to existing machine learning and deep learning methods. This study advances the understanding and early diagnosis of NSSI in adolescents with depression, enabling timely intervention. The source code is available at https://github.com/Vesan-yws/NSSINet.
NIS-SLAM: Neural Implicit Semantic RGB-D SLAM for 3D Consistent Scene Understanding
Jul 30, 2024



In recent years, the paradigm of neural implicit representations has gained substantial attention in the field of Simultaneous Localization and Mapping (SLAM). However, a notable gap exists in the existing approaches when it comes to scene understanding. In this paper, we introduce NIS-SLAM, an efficient neural implicit semantic RGB-D SLAM system, that leverages a pre-trained 2D segmentation network to learn consistent semantic representations. Specifically, for high-fidelity surface reconstruction and spatial consistent scene understanding, we combine high-frequency multi-resolution tetrahedron-based features and low-frequency positional encoding as the implicit scene representations. Besides, to address the inconsistency of 2D segmentation results from multiple views, we propose a fusion strategy that integrates the semantic probabilities from previous non-keyframes into keyframes to achieve consistent semantic learning. Furthermore, we implement a confidence-based pixel sampling and progressive optimization weight function for robust camera tracking. Extensive experimental results on various datasets show the better or more competitive performance of our system when compared to other existing neural dense implicit RGB-D SLAM approaches. Finally, we also show that our approach can be used in augmented reality applications. Project page: \href{https://zju3dv.github.io/nis_slam}{https://zju3dv.github.io/nis\_slam}.
DuA: Dual Attentive Transformer in Long-Term Continuous EEG Emotion Analysis
Jul 30, 2024
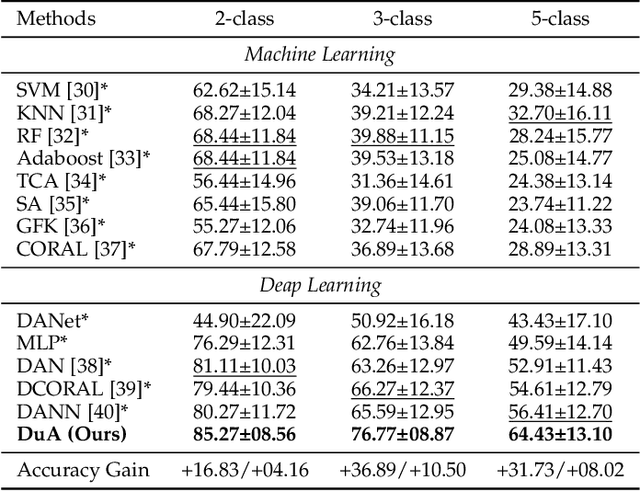
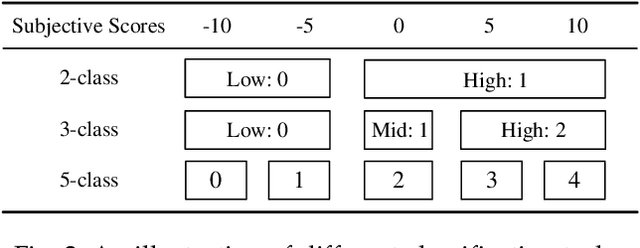

Affective brain-computer interfaces (aBCIs) are increasingly recognized for their potential in monitoring and interpreting emotional states through electroencephalography (EEG) signals. Current EEG-based emotion recognition methods perform well with short segments of EEG data. However, these methods encounter significant challenges in real-life scenarios where emotional states evolve over extended periods. To address this issue, we propose a Dual Attentive (DuA) transformer framework for long-term continuous EEG emotion analysis. Unlike segment-based approaches, the DuA transformer processes an entire EEG trial as a whole, identifying emotions at the trial level, referred to as trial-based emotion analysis. This framework is designed to adapt to varying signal lengths, providing a substantial advantage over traditional methods. The DuA transformer incorporates three key modules: the spatial-spectral network module, the temporal network module, and the transfer learning module. The spatial-spectral network module simultaneously captures spatial and spectral information from EEG signals, while the temporal network module detects temporal dependencies within long-term EEG data. The transfer learning module enhances the model's adaptability across different subjects and conditions. We extensively evaluate the DuA transformer using a self-constructed long-term EEG emotion database, along with two benchmark EEG emotion databases. On the basis of the trial-based leave-one-subject-out cross-subject cross-validation protocol, our experimental results demonstrate that the proposed DuA transformer significantly outperforms existing methods in long-term continuous EEG emotion analysis, with an average enhancement of 5.28%.
Vox-Fusion++: Voxel-based Neural Implicit Dense Tracking and Mapping with Multi-maps
Mar 19, 2024In this paper, we introduce Vox-Fusion++, a multi-maps-based robust dense tracking and mapping system that seamlessly fuses neural implicit representations with traditional volumetric fusion techniques. Building upon the concept of implicit mapping and positioning systems, our approach extends its applicability to real-world scenarios. Our system employs a voxel-based neural implicit surface representation, enabling efficient encoding and optimization of the scene within each voxel. To handle diverse environments without prior knowledge, we incorporate an octree-based structure for scene division and dynamic expansion. To achieve real-time performance, we propose a high-performance multi-process framework. This ensures the system's suitability for applications with stringent time constraints. Additionally, we adopt the idea of multi-maps to handle large-scale scenes, and leverage loop detection and hierarchical pose optimization strategies to reduce long-term pose drift and remove duplicate geometry. Through comprehensive evaluations, we demonstrate that our method outperforms previous methods in terms of reconstruction quality and accuracy across various scenarios. We also show that our Vox-Fusion++ can be used in augmented reality and collaborative mapping applications. Our source code will be publicly available at \url{https://github.com/zju3dv/Vox-Fusion_Plus_Plus}
RD-VIO: Robust Visual-Inertial Odometry for Mobile Augmented Reality in Dynamic Environments
Oct 23, 2023
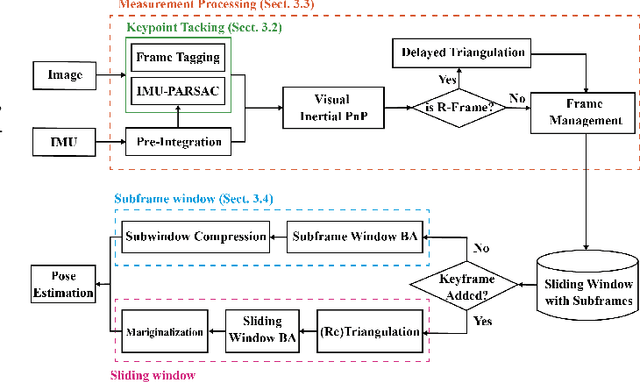

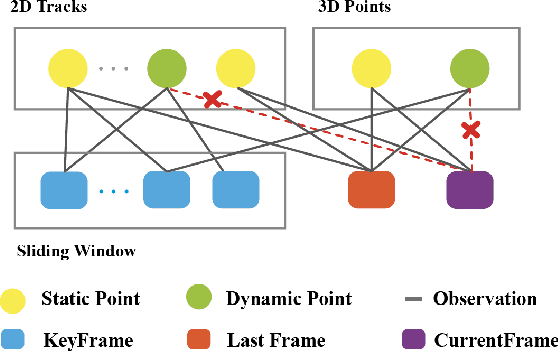
It is typically challenging for visual or visual-inertial odometry systems to handle the problems of dynamic scenes and pure rotation. In this work, we design a novel visual-inertial odometry (VIO) system called RD-VIO to handle both of these two problems. Firstly, we propose an IMU-PARSAC algorithm which can robustly detect and match keypoints in a two-stage process. In the first state, landmarks are matched with new keypoints using visual and IMU measurements. We collect statistical information from the matching and then guide the intra-keypoint matching in the second stage. Secondly, to handle the problem of pure rotation, we detect the motion type and adapt the deferred-triangulation technique during the data-association process. We make the pure-rotational frames into the special subframes. When solving the visual-inertial bundle adjustment, they provide additional constraints to the pure-rotational motion. We evaluate the proposed VIO system on public datasets. Experiments show the proposed RD-VIO has obvious advantages over other methods in dynamic environments.
Semi-Supervised Dual-Stream Self-Attentive Adversarial Graph Contrastive Learning for Cross-Subject EEG-based Emotion Recognition
Aug 13, 2023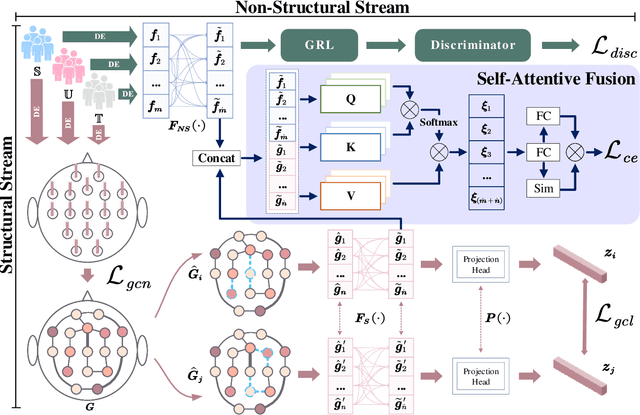
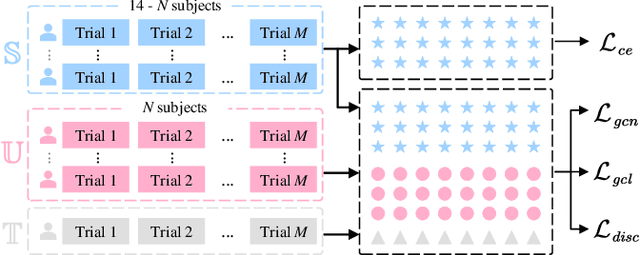
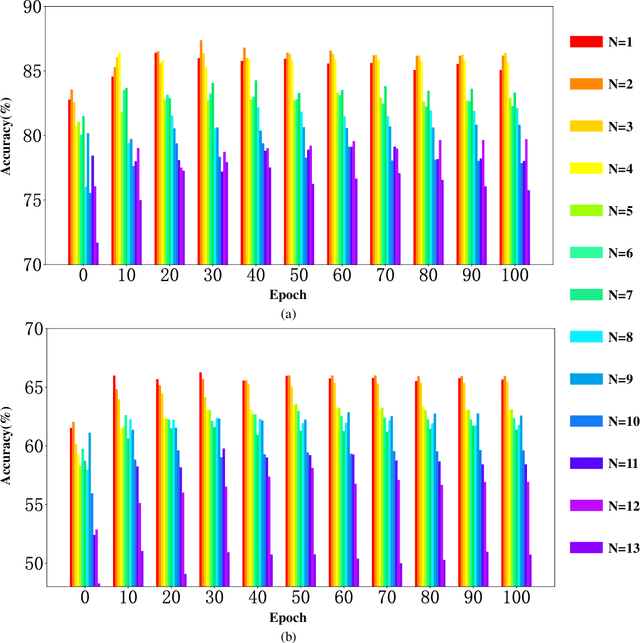
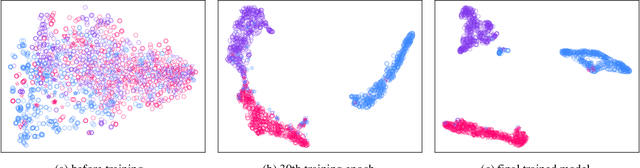
Electroencephalography (EEG) is an objective tool for emotion recognition with promising applications. However, the scarcity of labeled data remains a major challenge in this field, limiting the widespread use of EEG-based emotion recognition. In this paper, a semi-supervised Dual-stream Self-Attentive Adversarial Graph Contrastive learning framework (termed as DS-AGC) is proposed to tackle the challenge of limited labeled data in cross-subject EEG-based emotion recognition. The DS-AGC framework includes two parallel streams for extracting non-structural and structural EEG features. The non-structural stream incorporates a semi-supervised multi-domain adaptation method to alleviate distribution discrepancy among labeled source domain, unlabeled source domain, and unknown target domain. The structural stream develops a graph contrastive learning method to extract effective graph-based feature representation from multiple EEG channels in a semi-supervised manner. Further, a self-attentive fusion module is developed for feature fusion, sample selection, and emotion recognition, which highlights EEG features more relevant to emotions and data samples in the labeled source domain that are closer to the target domain. Extensive experiments conducted on two benchmark databases (SEED and SEED-IV) using a semi-supervised cross-subject leave-one-subject-out cross-validation evaluation scheme show that the proposed model outperforms existing methods under different incomplete label conditions (with an average improvement of 5.83% on SEED and 6.99% on SEED-IV), demonstrating its effectiveness in addressing the label scarcity problem in cross-subject EEG-based emotion recognition.
EEGMatch: Learning with Incomplete Labels for Semi-Supervised EEG-based Cross-Subject Emotion Recognition
Mar 27, 2023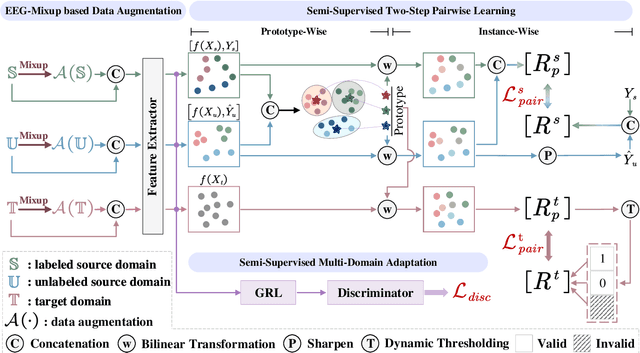
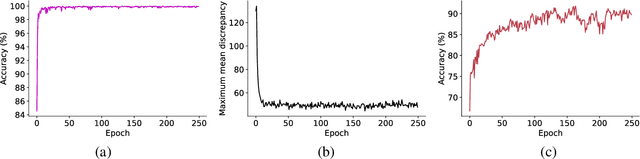
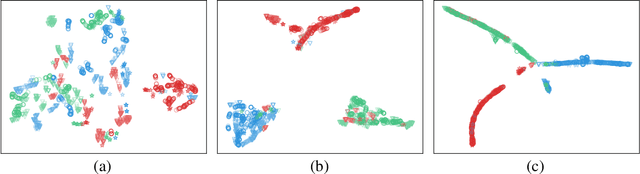
Electroencephalography (EEG) is an objective tool for emotion recognition and shows promising performance. However, the label scarcity problem is a main challenge in this field, which limits the wide application of EEG-based emotion recognition. In this paper, we propose a novel semi-supervised learning framework (EEGMatch) to leverage both labeled and unlabeled EEG data. First, an EEG-Mixup based data augmentation method is developed to generate more valid samples for model learning. Second, a semi-supervised two-step pairwise learning method is proposed to bridge prototype-wise and instance-wise pairwise learning, where the prototype-wise pairwise learning measures the global relationship between EEG data and the prototypical representation of each emotion class and the instance-wise pairwise learning captures the local intrinsic relationship among EEG data. Third, a semi-supervised multi-domain adaptation is introduced to align the data representation among multiple domains (labeled source domain, unlabeled source domain, and target domain), where the distribution mismatch is alleviated. Extensive experiments are conducted on two benchmark databases (SEED and SEED-IV) under a cross-subject leave-one-subject-out cross-validation evaluation protocol. The results show the proposed EEGmatch performs better than the state-of-the-art methods under different incomplete label conditions (with 6.89% improvement on SEED and 1.44% improvement on SEED-IV), which demonstrates the effectiveness of the proposed EEGMatch in dealing with the label scarcity problem in emotion recognition using EEG signals. The source code is available at https://github.com/KAZABANA/EEGMatch.
EEGFuseNet: Hybrid Unsupervised Deep Feature Characterization and Fusion for High-Dimensional EEG with An Application to Emotion Recognition
Feb 07, 2021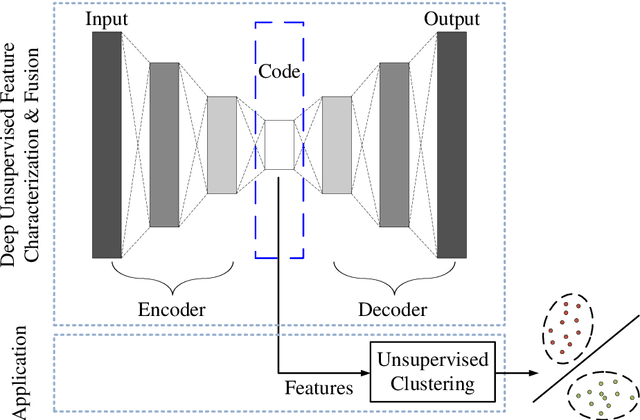
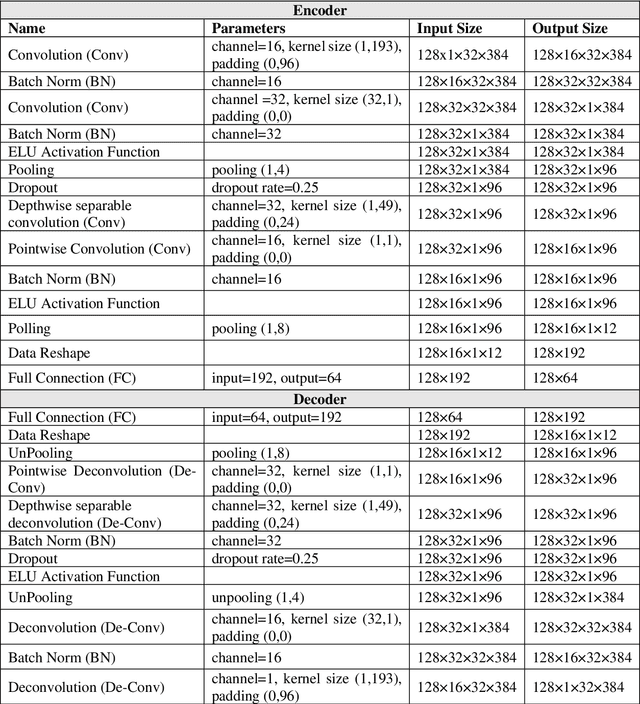
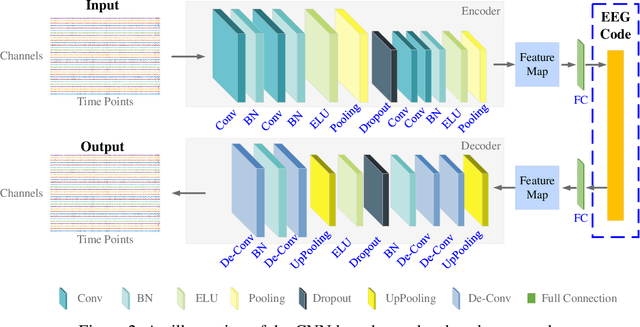
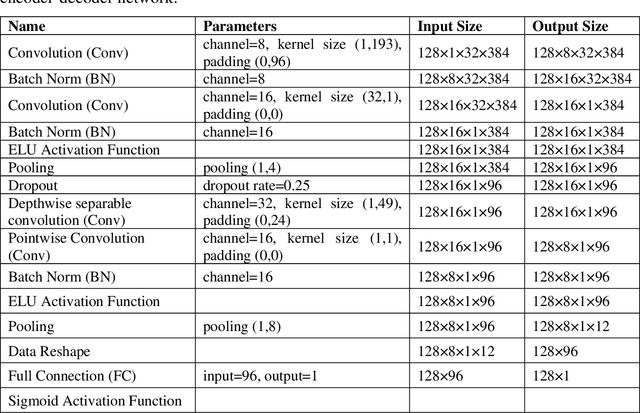
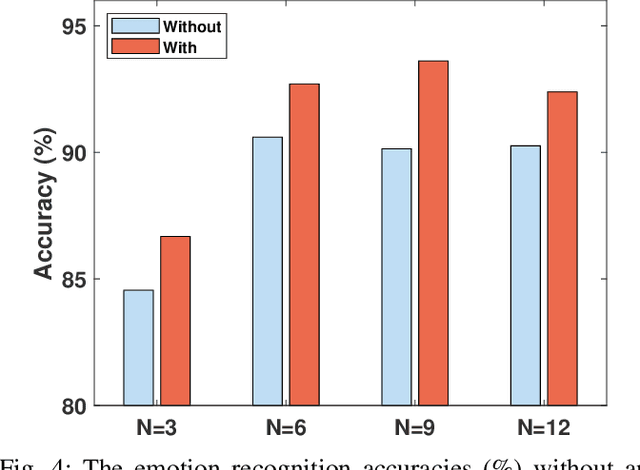
How to effectively and efficiently extract valid and reliable features from high-dimensional electroencephalography (EEG), particularly how to fuse the spatial and temporal dynamic brain information into a better feature representation, is a critical issue in brain data analysis. Most current EEG studies are working on handcrafted features with a supervised modeling, which would be limited by experience and human feedbacks to a great extent. In this paper, we propose a practical hybrid unsupervised deep CNN-RNN-GAN based EEG feature characterization and fusion model, which is termed as EEGFuseNet. EEGFuseNet is trained in an unsupervised manner, and deep EEG features covering spatial and temporal dynamics are automatically characterized. Comparing to the handcrafted features, the deep EEG features could be considered to be more generic and independent of any specific EEG task. The performance of the extracted deep and low-dimensional features by EEGFuseNet is carefully evaluated in an unsupervised emotion recognition application based on a famous public emotion database. The results demonstrate the proposed EEGFuseNet is a robust and reliable model, which is easy to train and manage and perform efficiently in the representation and fusion of dynamic EEG features. In particular, EEGFuseNet is established as an optimal unsupervised fusion model with promising subject-based leave-one-out results in the recognition of four emotion dimensions (valence, arousal, dominance and liking), which demonstrates the possibility of realizing EEG based cross-subject emotion recognition in a pure unsupervised manner.