 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuraLoc: Visual Localization in Neural Implicit Map with Dual Complementary Features
Mar 08, 2025Recently, neural radiance fields (NeRF) have gained significant attention in the field of visual localization. However, existing NeRF-based approaches either lack geometric constraints or require extensive storage for feature matching, limiting their practical applications. To address these challenges, we propose an efficient and novel visual localization approach based on the neural implicit map with complementary features. Specifically, to enforce geometric constraints and reduce storage requirements, we implicitly learn a 3D keypoint descriptor field, avoiding the need to explicitly store point-wise features. To further address the semantic ambiguity of descriptors, we introduce additional semantic contextual feature fields, which enhance the quality and reliability of 2D-3D correspondences. Besides, we propose descriptor similarity distribution alignment to minimize the domain gap between 2D and 3D feature spaces during matching. Finally, we construct the matching graph using both complementary descriptors and contextual features to establish accurate 2D-3D correspondences for 6-DoF pose estimation. Compared with the recent NeRF-based approaches, our method achieves a 3$\times$ faster training speed and a 45$\times$ reduction in model storage. Extensive experiments on two widely used datasets demonstrate that our approach outperforms or is highly competitive with other state-of-the-art NeRF-based visual localization methods. Project page: \href{https://zju3dv.github.io/neuraloc}{https://zju3dv.github.io/neuraloc}
SplatLoc: 3D Gaussian Splatting-based Visual Localization for Augmented Reality
Sep 21, 2024



Visual localization plays an important role in the applications of Augmented Reality (AR), which enable AR devices to obtain their 6-DoF pose in the pre-build map in order to render virtual content in real scenes. However, most existing approaches can not perform novel view rendering and require large storage capacities for maps. To overcome these limitations, we propose an efficient visual localization method capable of high-quality rendering with fewer parameters. Specifically, our approach leverages 3D Gaussian primitives as the scene representation. To ensure precise 2D-3D correspondences for pose estimation, we develop an unbiased 3D scene-specific descriptor decoder for Gaussian primitives, distilled from a constructed feature volume. Additionally, we introduce a salient 3D landmark selection algorithm that selects a suitable primitive subset based on the saliency score for localization. We further regularize key Gaussian primitives to prevent anisotropic effects, which also improves localization performance. Extensive experiments on two widely used datasets demonstrate that our method achieves superior or comparable rendering and localization performance to state-of-the-art implicit-based visual localization approaches. Project page: \href{https://zju3dv.github.io/splatloc}{https://zju3dv.github.io/splatloc}.
NIS-SLAM: Neural Implicit Semantic RGB-D SLAM for 3D Consistent Scene Understanding
Jul 30, 2024



In recent years, the paradigm of neural implicit representations has gained substantial attention in the field of Simultaneous Localization and Mapping (SLAM). However, a notable gap exists in the existing approaches when it comes to scene understanding. In this paper, we introduce NIS-SLAM, an efficient neural implicit semantic RGB-D SLAM system, that leverages a pre-trained 2D segmentation network to learn consistent semantic representations. Specifically, for high-fidelity surface reconstruction and spatial consistent scene understanding, we combine high-frequency multi-resolution tetrahedron-based features and low-frequency positional encoding as the implicit scene representations. Besides, to address the inconsistency of 2D segmentation results from multiple views, we propose a fusion strategy that integrates the semantic probabilities from previous non-keyframes into keyframes to achieve consistent semantic learning. Furthermore, we implement a confidence-based pixel sampling and progressive optimization weight function for robust camera tracking. Extensive experimental results on various datasets show the better or more competitive performance of our system when compared to other existing neural dense implicit RGB-D SLAM approaches. Finally, we also show that our approach can be used in augmented reality applications. Project page: \href{https://zju3dv.github.io/nis_slam}{https://zju3dv.github.io/nis\_slam}.
Vox-Fusion++: Voxel-based Neural Implicit Dense Tracking and Mapping with Multi-maps
Mar 19, 2024In this paper, we introduce Vox-Fusion++, a multi-maps-based robust dense tracking and mapping system that seamlessly fuses neural implicit representations with traditional volumetric fusion techniques. Building upon the concept of implicit mapping and positioning systems, our approach extends its applicability to real-world scenarios. Our system employs a voxel-based neural implicit surface representation, enabling efficient encoding and optimization of the scene within each voxel. To handle diverse environments without prior knowledge, we incorporate an octree-based structure for scene division and dynamic expansion. To achieve real-time performance, we propose a high-performance multi-process framework. This ensures the system's suitability for applications with stringent time constraints. Additionally, we adopt the idea of multi-maps to handle large-scale scenes, and leverage loop detection and hierarchical pose optimization strategies to reduce long-term pose drift and remove duplicate geometry. Through comprehensive evaluations, we demonstrate that our method outperforms previous methods in terms of reconstruction quality and accuracy across various scenarios. We also show that our Vox-Fusion++ can be used in augmented reality and collaborative mapping applications. Our source code will be publicly available at \url{https://github.com/zju3dv/Vox-Fusion_Plus_Plus}
Vox-Fusion: Dense Tracking and Mapping with Voxel-based Neural Implicit Representation
Oct 28, 2022In this work, we present a dense tracking and mapping system named Vox-Fusion, which seamlessly fuses neural implicit representations with traditional volumetric fusion methods. Our approach is inspired by the recently developed implicit mapping and positioning system and further extends the idea so that it can be freely applied to practical scenarios. Specifically, we leverage a voxel-based neural implicit surface representation to encode and optimize the scene inside each voxel. Furthermore, we adopt an octree-based structure to divide the scene and support dynamic expansion, enabling our system to track and map arbitrary scenes without knowing the environment like in previous works. Moreover, we proposed a high-performance multi-process framework to speed up the method, thus supporting some applications that require real-time performance. The evaluation results show that our methods can achieve better accuracy and completeness than previous methods. We also show that our Vox-Fusion can be used in augmented reality and virtual reality applications. Our source code is publicly available at https://github.com/zju3dv/Vox-Fusion.
Vox-Surf: Voxel-based Implicit Surface Representation
Aug 21, 2022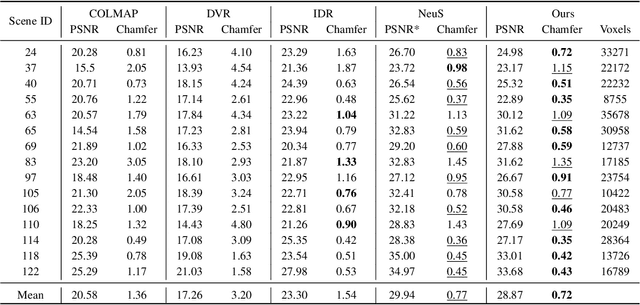
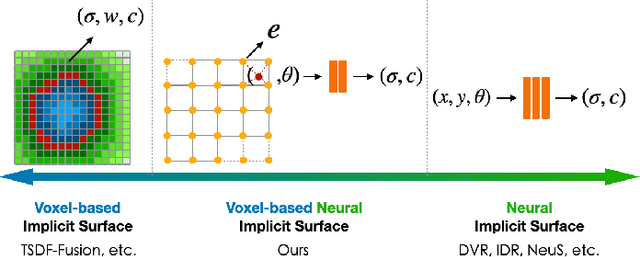
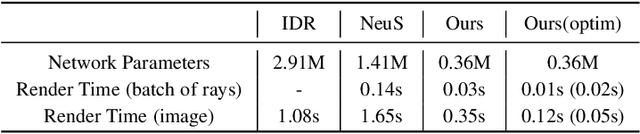
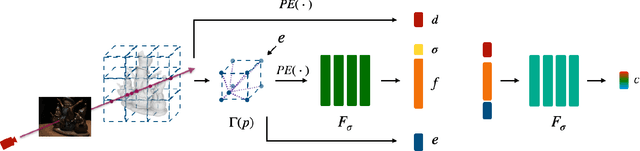
Virtual content creation and interaction play an important role in modern 3D applications such as AR and VR. Recovering detailed 3D models from real scenes can significantly expand the scope of its applications and has been studied for decades in the computer vision and computer graphics community. We propose Vox-Surf, a voxel-based implicit surface representation. Our Vox-Surf divides the space into finite bounded voxels. Each voxel stores geometry and appearance information in its corner vertices. Vox-Surf is suitable for almost any scenario thanks to sparsity inherited from voxel representation and can be easily trained from multiple view images. We leverage the progressive training procedure to extract important voxels gradually for further optimization so that only valid voxels are preserved, which greatly reduces the number of sampling points and increases rendering speed.The fine voxels can also be considered as the bounding volume for collision detection.The experiments show that Vox-Surf representation can learn delicate surface details and accurate color with less memory and faster rendering speed than other methods.We also show that Vox-Surf can be more practical in scene editing and AR applications.