 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuraLoc: Visual Localization in Neural Implicit Map with Dual Complementary Features
Mar 08, 2025Recently, neural radiance fields (NeRF) have gained significant attention in the field of visual localization. However, existing NeRF-based approaches either lack geometric constraints or require extensive storage for feature matching, limiting their practical applications. To address these challenges, we propose an efficient and novel visual localization approach based on the neural implicit map with complementary features. Specifically, to enforce geometric constraints and reduce storage requirements, we implicitly learn a 3D keypoint descriptor field, avoiding the need to explicitly store point-wise features. To further address the semantic ambiguity of descriptors, we introduce additional semantic contextual feature fields, which enhance the quality and reliability of 2D-3D correspondences. Besides, we propose descriptor similarity distribution alignment to minimize the domain gap between 2D and 3D feature spaces during matching. Finally, we construct the matching graph using both complementary descriptors and contextual features to establish accurate 2D-3D correspondences for 6-DoF pose estimation. Compared with the recent NeRF-based approaches, our method achieves a 3$\times$ faster training speed and a 45$\times$ reduction in model storage. Extensive experiments on two widely used datasets demonstrate that our approach outperforms or is highly competitive with other state-of-the-art NeRF-based visual localization methods. Project page: \href{https://zju3dv.github.io/neuraloc}{https://zju3dv.github.io/neuraloc}
RD-VIO: Robust Visual-Inertial Odometry for Mobile Augmented Reality in Dynamic Environments
Oct 23, 2023
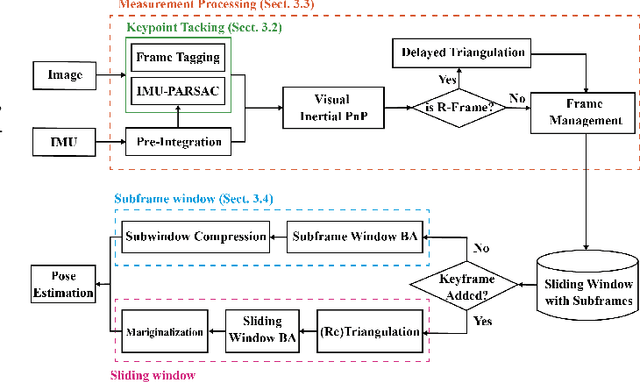

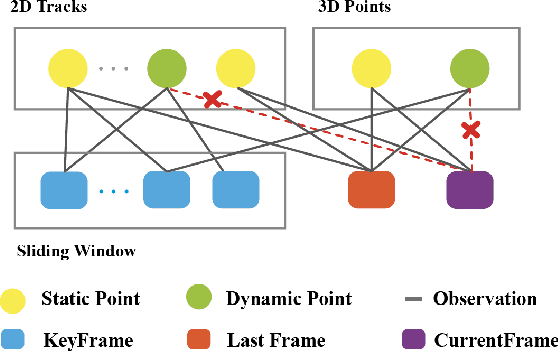
It is typically challenging for visual or visual-inertial odometry systems to handle the problems of dynamic scenes and pure rotation. In this work, we design a novel visual-inertial odometry (VIO) system called RD-VIO to handle both of these two problems. Firstly, we propose an IMU-PARSAC algorithm which can robustly detect and match keypoints in a two-stage process. In the first state, landmarks are matched with new keypoints using visual and IMU measurements. We collect statistical information from the matching and then guide the intra-keypoint matching in the second stage. Secondly, to handle the problem of pure rotation, we detect the motion type and adapt the deferred-triangulation technique during the data-association process. We make the pure-rotational frames into the special subframes. When solving the visual-inertial bundle adjustment, they provide additional constraints to the pure-rotational motion. We evaluate the proposed VIO system on public datasets. Experiments show the proposed RD-VIO has obvious advantages over other methods in dynamic environments.
NeuralMarker: A Framework for Learning General Marker Correspondence
Sep 19, 2022
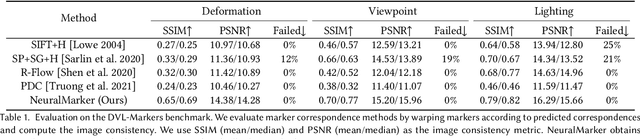


We tackle the problem of estimating correspondences from a general marker, such as a movie poster, to an image that captures such a marker. Conventionally, this problem is addressed by fitting a homography model based on sparse feature matching. However, they are only able to handle plane-like markers and the sparse features do not sufficiently utilize appearance information. In this paper, we propose a novel framework NeuralMarker, training a neural network estimating dense marker correspondences under various challenging conditions, such as marker deformation, harsh lighting, etc. Besides, we also propose a novel marker correspondence evaluation method circumstancing annotations on real marker-image pairs and create a new benchmark. We show that NeuralMarker significantly outperforms previous methods and enables new interesting applications, including Augmented Reality (AR) and video editing.
LIFE: Lighting Invariant Flow Estimation
Apr 19, 2021


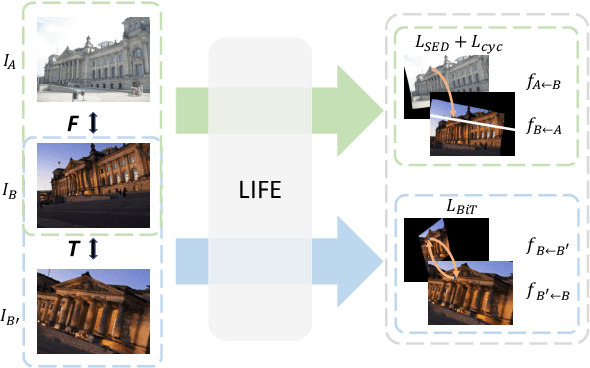
We tackle the problem of estimating flow between two images with large lighting variations. Recent learning-based flow estimation frameworks have shown remarkable performance on image pairs with small displacement and constant illuminations, but cannot work well on cases with large viewpoint change and lighting variations because of the lack of pixel-wise flow annotations for such cases. We observe that via the Structure-from-Motion (SfM) techniques, one can easily estimate relative camera poses between image pairs with large viewpoint change and lighting variations. We propose a novel weakly supervised framework LIFE to train a neural network for estimating accurate lighting-invariant flows between image pairs. Sparse correspondences are conventionally established via feature matching with descriptors encoding local image contents. However, local image contents are inevitably ambiguous and error-prone during the cross-image feature matching process, which hinders downstream tasks. We propose to guide feature matching with the flows predicted by LIFE, which addresses the ambiguous matching by utilizing abundant context information in the image pairs. We show that LIFE outperforms previous flow learning frameworks by large margins in challenging scenarios, consistently improves feature matching, and benefits downstream tasks.