 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelightMaster: Precise Video Relighting with Multi-plane Light Images
Nov 09, 2025Recent advances in diffusion models enable high-quality video generation and editing, but precise relighting with consistent video contents, which is critical for shaping scene atmosphere and viewer attention, remains unexplored. Mainstream text-to-video (T2V) models lack fine-grained lighting control due to text's inherent limitation in describing lighting details and insufficient pre-training on lighting-related prompts. Additionally, constructing high-quality relighting training data is challenging, as real-world controllable lighting data is scarce. To address these issues, we propose RelightMaster, a novel framework for accurate and controllable video relighting. First, we build RelightVideo, the first dataset with identical dynamic content under varying precise lighting conditions based on the Unreal Engine. Then, we introduce Multi-plane Light Image (MPLI), a novel visual prompt inspired by Multi-Plane Image (MPI). MPLI models lighting via K depth-aligned planes, representing 3D light source positions, intensities, and colors while supporting multi-source scenarios and generalizing to unseen light setups. Third, we design a Light Image Adapter that seamlessly injects MPLI into pre-trained Video Diffusion Transformers (DiT): it compresses MPLI via a pre-trained Video VAE and injects latent light features into DiT blocks, leveraging the base model's generative prior without catastrophic forgetting. Experiments show that RelightMaster generates physically plausible lighting and shadows and preserves original scene content. Demos are available at https://wkbian.github.io/Projects/RelightMaster/.
GS-DiT: Advancing Video Generation with Pseudo 4D Gaussian Fields through Efficient Dense 3D Point Tracking
Jan 05, 2025



4D video control is essential in video generation as it enables the use of sophisticated lens techniques, such as multi-camera shooting and dolly zoom, which are currently unsupported by existing methods. Training a video Diffusion Transformer (DiT) directly to control 4D content requires expensive multi-view videos. Inspired by Monocular Dynamic novel View Synthesis (MDVS) that optimizes a 4D representation and renders videos according to different 4D elements, such as camera pose and object motion editing, we bring pseudo 4D Gaussian fields to video generation. Specifically, we propose a novel framework that constructs a pseudo 4D Gaussian field with dense 3D point tracking and renders the Gaussian field for all video frames. Then we finetune a pretrained DiT to generate videos following the guidance of the rendered video, dubbed as GS-DiT. To boost the training of the GS-DiT, we also propose an efficient Dense 3D Point Tracking (D3D-PT) method for the pseudo 4D Gaussian field construction. Our D3D-PT outperforms SpatialTracker, the state-of-the-art sparse 3D point tracking method, in accuracy and accelerates the inference speed by two orders of magnitude. During the inference stage, GS-DiT can generate videos with the same dynamic content while adhering to different camera parameters, addressing a significant limitation of current video generation models. GS-DiT demonstrates strong generalization capabilities and extends the 4D controllability of Gaussian splatting to video generation beyond just camera poses. It supports advanced cinematic effects through the manipulation of the Gaussian field and camera intrinsics, making it a powerful tool for creative video production. Demos are available at https://wkbian.github.io/Projects/GS-DiT/.
A Global Depth-Range-Free Multi-View Stereo Transformer Network with Pose Embedding
Nov 04, 2024



In this paper, we propose a novel multi-view stereo (MVS) framework that gets rid of the depth range prior. Unlike recent prior-free MVS methods that work in a pair-wise manner, our method simultaneously considers all the source images. Specifically, we introduce a Multi-view Disparity Attention (MDA) module to aggregate long-range context information within and across multi-view images. Considering the asymmetry of the epipolar disparity flow, the key to our method lies in accurately modeling multi-view geometric constraints. We integrate pose embedding to encapsulate information such as multi-view camera poses, providing implicit geometric constraints for multi-view disparity feature fusion dominated by attention. Additionally, we construct corresponding hidden states for each source image due to significant differences in the observation quality of the same pixel in the reference frame across multiple source frames. We explicitly estimate the quality of the current pixel corresponding to sampled points on the epipolar line of the source image and dynamically update hidden states through the uncertainty estimation module. Extensive results on the DTU dataset and Tanks&Temple benchmark demonstrate the effectiveness of our method. The code is available at our project page: https://zju3dv.github.io/GD-PoseMVS/.
BlinkVision: A Benchmark for Optical Flow, Scene Flow and Point Tracking Estimation using RGB Frames and Events
Oct 27, 2024Recent advances in event-based vision suggest that these systems complement traditional cameras by providing continuous observation without frame rate limitations and a high dynamic range, making them well-suited for correspondence tasks such as optical flow and point tracking. However, there is still a lack of comprehensive benchmarks for correspondence tasks that include both event data and images. To address this gap, we propose BlinkVision, a large-scale and diverse benchmark with multiple modalities and dense correspondence annotations. BlinkVision offers several valuable features: 1) Rich modalities: It includes both event data and RGB images. 2) Extensive annotations: It provides dense per-pixel annotations covering optical flow, scene flow, and point tracking. 3) Large vocabulary: It contains 410 everyday categories, sharing common classes with popular 2D and 3D datasets like LVIS and ShapeNet. 4) Naturalistic: It delivers photorealistic data and covers various naturalistic factors, such as camera shake and deformation. BlinkVision enables extensive benchmarks on three types of correspondence tasks (optical flow, point tracking, and scene flow estimation) for both image-based and event-based methods, offering new observations, practices, and insights for future research. The benchmark website is https://www.blinkvision.net/.
Phased Consistency Model
May 28, 2024The consistency model (CM) has recently made significant progress in accelerating the generation of diffusion models. However, its application to high-resolution, text-conditioned image generation in the latent space (a.k.a., LCM) remains unsatisfactory. In this paper, we identify three key flaws in the current design of LCM. We investigate the reasons behind these limitations and propose the Phased Consistency Model (PCM), which generalizes the design space and addresses all identified limitations. Our evaluations demonstrate that PCM significantly outperforms LCM across 1--16 step generation settings. While PCM is specifically designed for multi-step refinement, it achieves even superior or comparable 1-step generation results to previously state-of-the-art specifically designed 1-step methods. Furthermore, we show that PCM's methodology is versatile and applicable to video generation, enabling us to train the state-of-the-art few-step text-to-video generator. More details are available at https://g-u-n.github.io/projects/pcm/.
AnimateLCM: Accelerating the Animation of Personalized Diffusion Models and Adapters with Decoupled Consistency Learning
Feb 01, 2024



Video diffusion models has been gaining increasing attention for its ability to produce videos that are both coherent and of high fidelity. However, the iterative denoising process makes it computationally intensive and time-consuming, thus limiting its applications. Inspired by the Consistency Model (CM) that distills pretrained image diffusion models to accelerate the sampling with minimal steps and its successful extension Latent Consistency Model (LCM) on conditional image generation, we propose AnimateLCM, allowing for high-fidelity video generation within minimal steps. Instead of directly conducting consistency learning on the raw video dataset, we propose a decoupled consistency learning strategy that decouples the distillation of image generation priors and motion generation priors, which improves the training efficiency and enhance the generation visual quality. Additionally, to enable the combination of plug-and-play adapters in stable diffusion community to achieve various functions (e.g., ControlNet for controllable generation). we propose an efficient strategy to adapt existing adapters to our distilled text-conditioned video consistency model or train adapters from scratch without harming the sampling speed. We validate the proposed strategy in image-conditioned video generation and layout-conditioned video generation, all achieving top-performing results. Experimental results validate the effectiveness of our proposed method. Code and weights will be made public. More details are available at https://github.com/G-U-N/AnimateLCM.
Motion-I2V: Consistent and Controllable Image-to-Video Generation with Explicit Motion Modeling
Jan 31, 2024



We introduce Motion-I2V, a novel framework for consistent and controllable image-to-video generation (I2V). In contrast to previous methods that directly learn the complicated image-to-video mapping, Motion-I2V factorizes I2V into two stages with explicit motion modeling. For the first stage, we propose a diffusion-based motion field predictor, which focuses on deducing the trajectories of the reference image's pixels. For the second stage, we propose motion-augmented temporal attention to enhance the limited 1-D temporal attention in video latent diffusion models. This module can effectively propagate reference image's feature to synthesized frames with the guidance of predicted trajectories from the first stage. Compared with existing methods, Motion-I2V can generate more consistent videos even at the presence of large motion and viewpoint variation. By training a sparse trajectory ControlNet for the first stage, Motion-I2V can support users to precisely control motion trajectories and motion regions with sparse trajectory and region annotations. This offers more controllability of the I2V process than solely relying on textual instructions. Additionally, Motion-I2V's second stage naturally supports zero-shot video-to-video translation. Both qualitative and quantitative comparisons demonstrate the advantages of Motion-I2V over prior approaches in consistent and controllable image-to-video generation. Please see our project page at https://xiaoyushi97.github.io/Motion-I2V/.
Context-TAP: Tracking Any Point Demands Spatial Context Features
Jun 03, 2023



We tackle the problem of Tracking Any Point (TAP) in videos, which specifically aims at estimating persistent long-term trajectories of query points in videos. Previous methods attempted to estimate these trajectories independently to incorporate longer image sequences, therefore, ignoring the potential benefits of incorporating spatial context features. We argue that independent video point tracking also demands spatial context features. To this end, we propose a novel framework Context-TAP, which effectively improves point trajectory accuracy by aggregating spatial context features in videos. Context-TAP contains two main modules: 1) a SOurse Feature Enhancement (SOFE) module, and 2) a TArget Feature Aggregation (TAFA) module. Context-TAP significantly improves PIPs all-sided, reducing 11.4% Average Trajectory Error of Occluded Points (ATE-Occ) on CroHD and increasing 11.8% Average Percentage of Correct Keypoint (A-PCK) on TAP-Vid-Kinectics. Demos are available at this $\href{https://wkbian.github.io/Projects/Context-TAP/}{webpage}$.
VideoFlow: Exploiting Temporal Cues for Multi-frame Optical Flow Estimation
Mar 17, 2023



We introduce VideoFlow, a novel optical flow estimation framework for videos. In contrast to previous methods that learn to estimate optical flow from two frames, VideoFlow concurrently estimates bi-directional optical flows for multiple frames that are available in videos by sufficiently exploiting temporal cues. We first propose a TRi-frame Optical Flow (TROF) module that estimates bi-directional optical flows for the center frame in a three-frame manner. The information of the frame triplet is iteratively fused onto the center frame. To extend TROF for handling more frames, we further propose a MOtion Propagation (MOP) module that bridges multiple TROFs and propagates motion features between adjacent TROFs. With the iterative flow estimation refinement, the information fused in individual TROFs can be propagated into the whole sequence via MOP. By effectively exploiting video information, VideoFlow presents extraordinary performance, ranking 1st on all public benchmarks. On the Sintel benchmark, VideoFlow achieves 1.649 and 0.991 average end-point-error (AEPE) on the final and clean passes, a 15.1% and 7.6% error reduction from the best published results (1.943 and 1.073 from FlowFormer++). On the KITTI-2015 benchmark, VideoFlow achieves an F1-all error of 3.65%, a 19.2% error reduction from the best published result (4.52% from FlowFormer++).
NeuralMarker: A Framework for Learning General Marker Correspondence
Sep 19, 2022
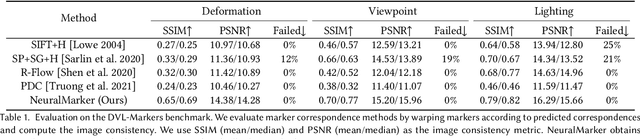


We tackle the problem of estimating correspondences from a general marker, such as a movie poster, to an image that captures such a marker. Conventionally, this problem is addressed by fitting a homography model based on sparse feature matching. However, they are only able to handle plane-like markers and the sparse features do not sufficiently utilize appearance information. In this paper, we propose a novel framework NeuralMarker, training a neural network estimating dense marker correspondences under various challenging conditions, such as marker deformation, harsh lighting, etc. Besides, we also propose a novel marker correspondence evaluation method circumstancing annotations on real marker-image pairs and create a new benchmark. We show that NeuralMarker significantly outperforms previous methods and enables new interesting applications, including Augmented Reality (AR) and video editing.