 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuraLoc: Visual Localization in Neural Implicit Map with Dual Complementary Features
Mar 08, 2025Recently, neural radiance fields (NeRF) have gained significant attention in the field of visual localization. However, existing NeRF-based approaches either lack geometric constraints or require extensive storage for feature matching, limiting their practical applications. To address these challenges, we propose an efficient and novel visual localization approach based on the neural implicit map with complementary features. Specifically, to enforce geometric constraints and reduce storage requirements, we implicitly learn a 3D keypoint descriptor field, avoiding the need to explicitly store point-wise features. To further address the semantic ambiguity of descriptors, we introduce additional semantic contextual feature fields, which enhance the quality and reliability of 2D-3D correspondences. Besides, we propose descriptor similarity distribution alignment to minimize the domain gap between 2D and 3D feature spaces during matching. Finally, we construct the matching graph using both complementary descriptors and contextual features to establish accurate 2D-3D correspondences for 6-DoF pose estimation. Compared with the recent NeRF-based approaches, our method achieves a 3$\times$ faster training speed and a 45$\times$ reduction in model storage. Extensive experiments on two widely used datasets demonstrate that our approach outperforms or is highly competitive with other state-of-the-art NeRF-based visual localization methods. Project page: \href{https://zju3dv.github.io/neuraloc}{https://zju3dv.github.io/neuraloc}
DOGE: An Extrinsic Orientation and Gyroscope Bias Estimation for Visual-Inertial Odometry Initialization
Dec 11, 2024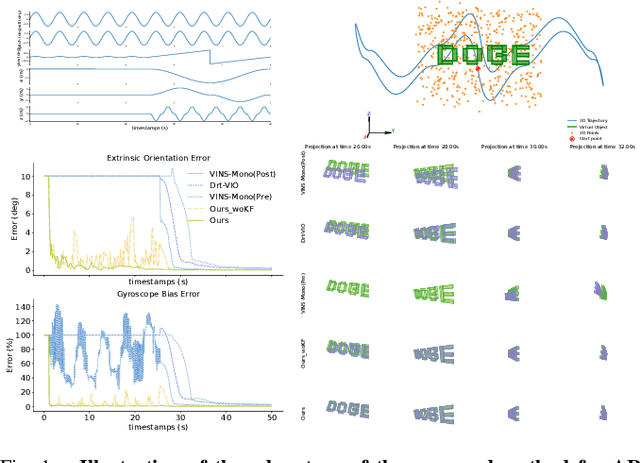
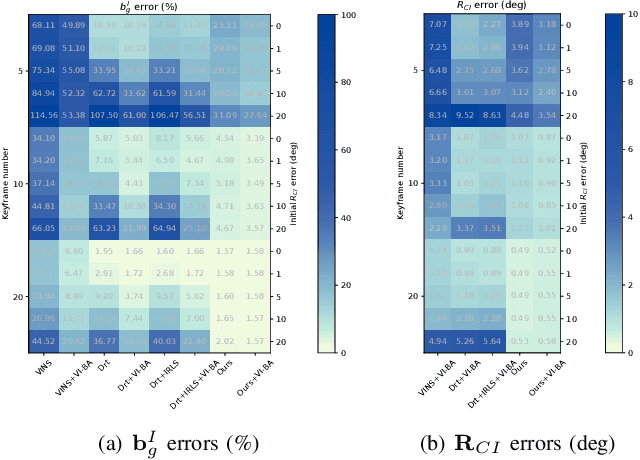
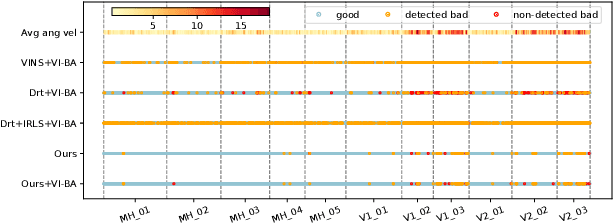
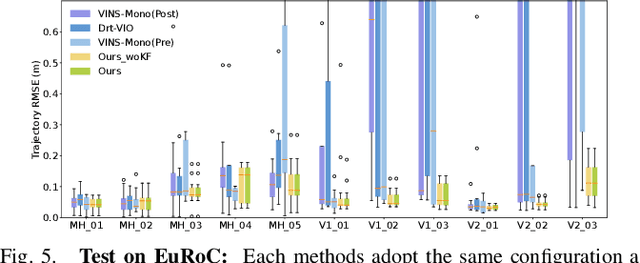
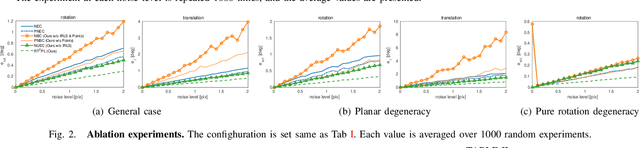
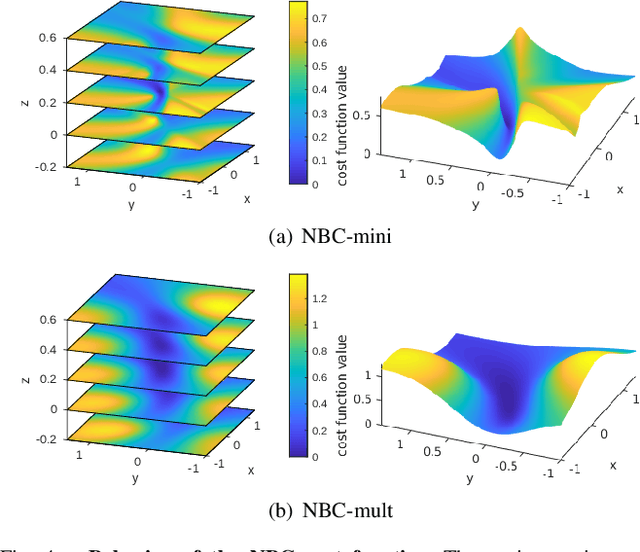
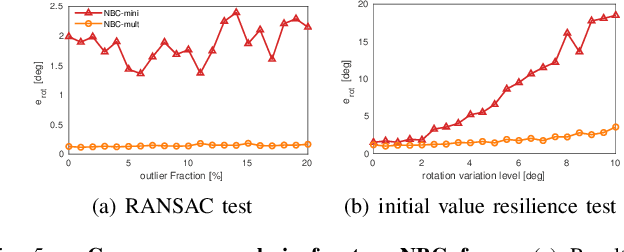
Most existing visual-inertial odometry (VIO) initialization methods rely on accurate pre-calibrated extrinsic parameters. However, during long-term use, irreversible structural deformation caused by temperature changes, mechanical squeezing, etc. will cause changes in extrinsic parameters, especially in the rotational part. Existing initialization methods that simultaneously estimate extrinsic parameters suffer from poor robustness, low precision, and long initialization latency due to the need for sufficient translational motion. To address these problems, we propose a novel VIO initialization method, which jointly considers extrinsic orientation and gyroscope bias within the normal epipolar constraints, achieving higher precision and better robustness without delayed rotational calibration. First, a rotation-only constraint is designed for extrinsic orientation and gyroscope bias estimation, which tightly couples gyroscope measurements and visual observations and can be solved in pure-rotation cases. Second, we propose a weighting strategy together with a failure detection strategy to enhance the precision and robustness of the estimator. Finally, we leverage Maximum A Posteriori to refine the results before enough translation parallax comes. Extensive experiments have demonstrated that our method outperforms the state-of-the-art methods in both accuracy and robustness while maintaining competitive efficiency.
SplatLoc: 3D Gaussian Splatting-based Visual Localization for Augmented Reality
Sep 21, 2024



Visual localization plays an important role in the applications of Augmented Reality (AR), which enable AR devices to obtain their 6-DoF pose in the pre-build map in order to render virtual content in real scenes. However, most existing approaches can not perform novel view rendering and require large storage capacities for maps. To overcome these limitations, we propose an efficient visual localization method capable of high-quality rendering with fewer parameters. Specifically, our approach leverages 3D Gaussian primitives as the scene representation. To ensure precise 2D-3D correspondences for pose estimation, we develop an unbiased 3D scene-specific descriptor decoder for Gaussian primitives, distilled from a constructed feature volume. Additionally, we introduce a salient 3D landmark selection algorithm that selects a suitable primitive subset based on the saliency score for localization. We further regularize key Gaussian primitives to prevent anisotropic effects, which also improves localization performance. Extensive experiments on two widely used datasets demonstrate that our method achieves superior or comparable rendering and localization performance to state-of-the-art implicit-based visual localization approaches. Project page: \href{https://zju3dv.github.io/splatloc}{https://zju3dv.github.io/splatloc}.
An Accurate and Real-time Relative Pose Estimation from Triple Point-line Images by Decoupling Rotation and Translation
Mar 18, 2024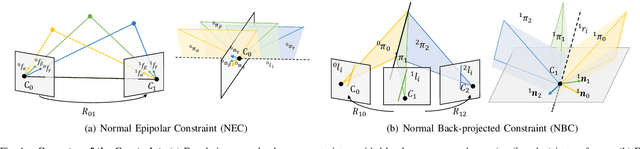
Line features are valid complements for point features in man-made environments. 3D-2D constraints provided by line features have been widely used in Visual Odometry (VO) and Structure-from-Motion (SfM) systems. However, how to accurately solve three-view relative motion only with 2D observations of points and lines in real time has not been fully explored. In this paper, we propose a novel three-view pose solver based on rotation-translation decoupled estimation. First, a high-precision rotation estimation method based on normal vector coplanarity constraints that consider the uncertainty of observations is proposed, which can be solved by Levenberg-Marquardt (LM) algorithm efficiently. Second, a robust linear translation constraint that minimizes the degree of the rotation components and feature observation components in equations is elaborately designed for estimating translations accurately. Experiments on synthetic data and real-world data show that the proposed approach improves both rotation and translation accuracy compared to the classical trifocal-tensor-based method and the state-of-the-art two-view algorithm in outdoor and indoor environments.
A Review and Comparative Study of Close-Range Geometric Camera Calibration Tools
Jun 15, 2023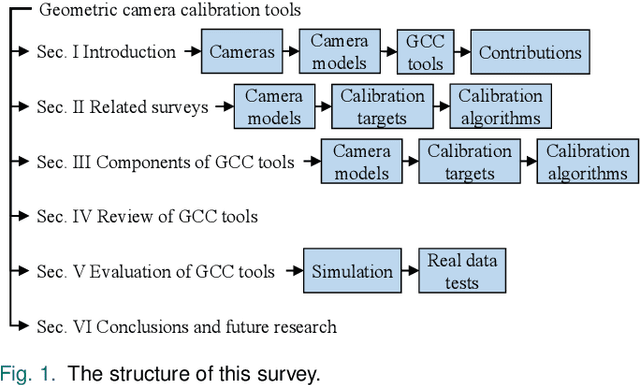
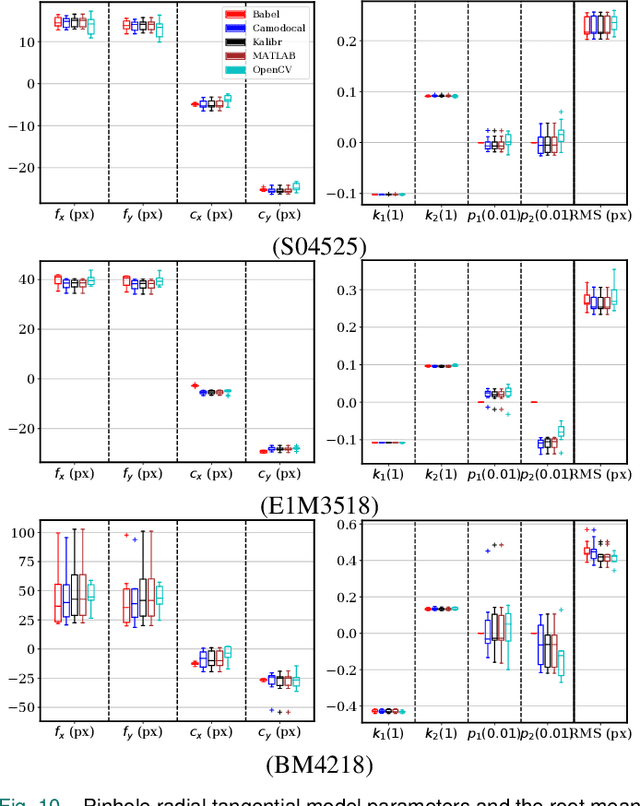
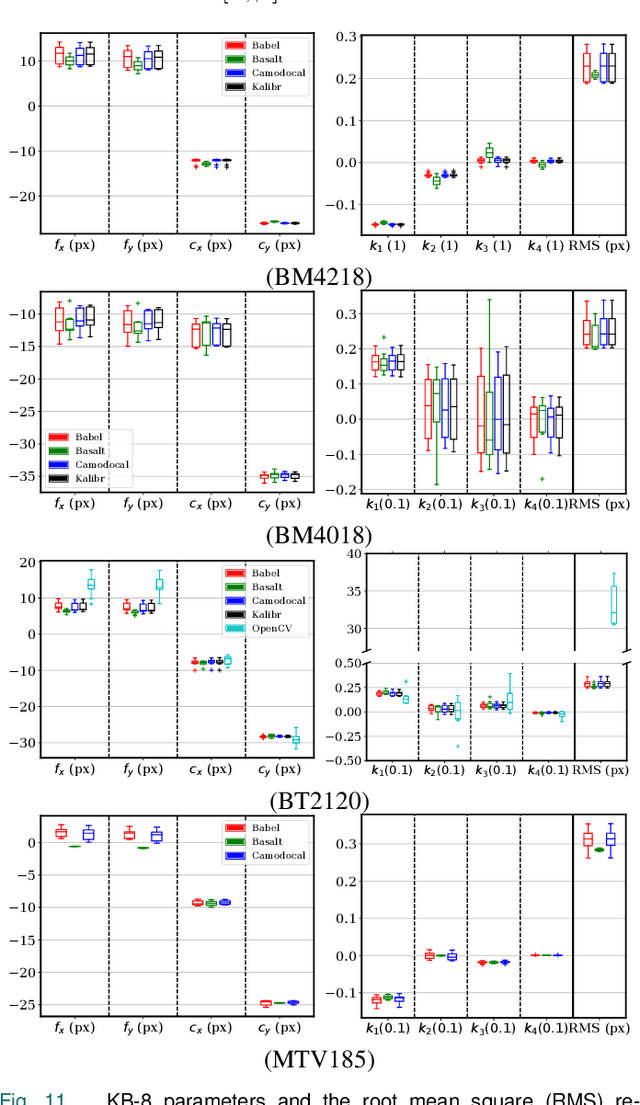
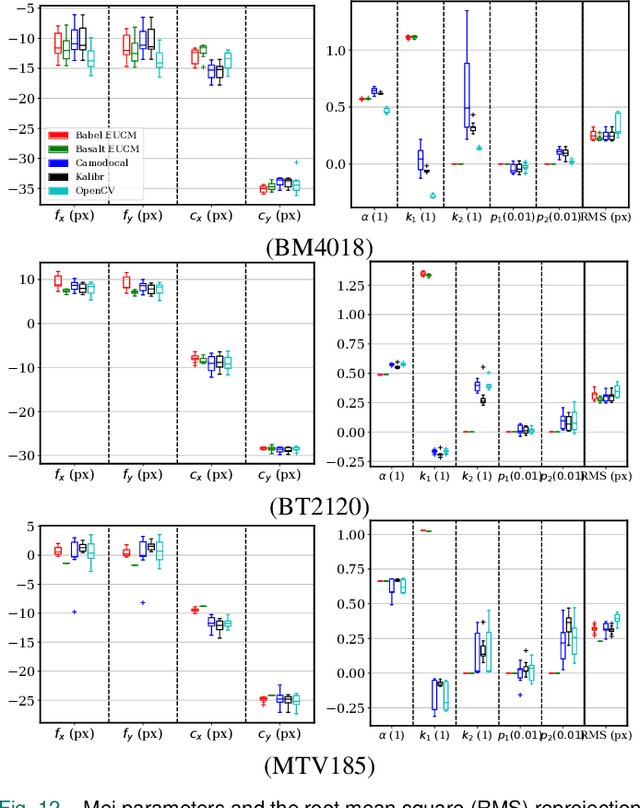
In many camera-based applications, it is necessary to find the geometric relationship between incoming rays and image pixels, i.e., the projection model, through the geometric camera calibration (GCC). Aiming to provide practical calibration guidelines, this work surveys and evaluates the existing GCC tools. The survey covers camera models, calibration targets, and algorithms used in these tools, highlighting their properties and the trends in GCC development. The evaluation compares six target-based GCC tools, namely, BabelCalib, Basalt, Camodocal, Kalibr, the MATLAB calibrator, and the OpenCV-based ROS calibrator, with simulated and real data for cameras of wide-angle and fisheye lenses described by three traditional projection models. These tests reveal the strengths and weaknesses of these camera models, as well as the repeatability of these GCC tools. In view of the survey and evaluation, future research directions of GCC are also discussed.
MVSTER: Epipolar Transformer for Efficient Multi-View Stereo
Apr 15, 2022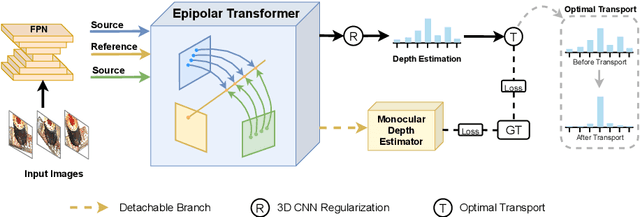



Learning-based Multi-View Stereo (MVS) methods warp source images into the reference camera frustum to form 3D volumes, which are fused as a cost volume to be regularized by subsequent networks. The fusing step plays a vital role in bridging 2D semantics and 3D spatial associations. However, previous methods utilize extra networks to learn 2D information as fusing cues, underusing 3D spatial correlations and bringing additional computation costs. Therefore, we present MVSTER, which leverages the proposed epipolar Transformer to learn both 2D semantics and 3D spatial associations efficiently. Specifically, the epipolar Transformer utilizes a detachable monocular depth estimator to enhance 2D semantics and uses cross-attention to construct data-dependent 3D associations along epipolar line. Additionally, MVSTER is built in a cascade structure, where entropy-regularized optimal transport is leveraged to propagate finer depth estimations in each stage. Extensive experiments show MVSTER achieves state-of-the-art reconstruction performance with significantly higher efficiency: Compared with MVSNet and CasMVSNet, our MVSTER achieves 34% and 14% relative improvements on the DTU benchmark, with 80% and 51% relative reductions in running time. MVSTER also ranks first on Tanks&Temples-Advanced among all published works. Code is released at https://github.com/JeffWang987.
Leveraging Structural Information to Improve Point Line Visual-Inertial Odometry
May 10, 2021
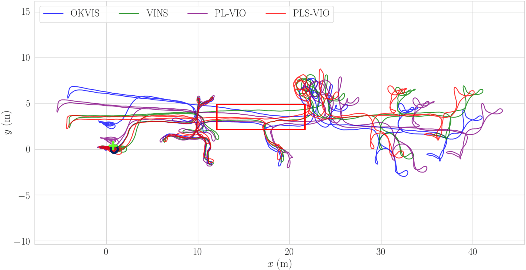


Leveraging line features can help to improve the localization accuracy of point-based monocular Visual-Inertial Odometry (VIO) system, as lines provide additional constraints. Moreover, in an artificial environment, some straight lines are parallel to each other. In this paper, we designed a VIO system based on points and straight lines, which divides straight lines into structural straight lines (that is, straight lines parallel to each other) and non-structural straight lines. In addition, unlike the orthogonal representation using four parameters to represent the 3D straight line, we only used two parameters to minimize the representation of the structural straight line and the non-structural straight line. Furthermore, we designed a straight line matching strategy based on sampling points to improve the efficiency and success rate of straight line matching. The effectiveness of our method is verified on both public datasets of EuRoc and TUM VI benchmark and compared with other state-of-the-art algorithms.
ELSD: Efficient Line Segment Detector and Descriptor
Apr 29, 2021



We present the novel Efficient Line Segment Detector and Descriptor (ELSD) to simultaneously detect line segments and extract their descriptors in an image. Unlike the traditional pipelines that conduct detection and description separately, ELSD utilizes a shared feature extractor for both detection and description, to provide the essential line features to the higher-level tasks like SLAM and image matching in real time. First, we design the one-stage compact model, and propose to use the mid-point, angle and length as the minimal representation of line segment, which also guarantees the center-symmetry. The non-centerness suppression is proposed to filter out the fragmented line segments caused by lines' intersections. The fine offset prediction is designed to refine the mid-point localization. Second, the line descriptor branch is integrated with the detector branch, and the two branches are jointly trained in an end-to-end manner. In the experiments, the proposed ELSD achieves the state-of-the-art performance on the Wireframe dataset and YorkUrban dataset, in both accuracy and efficiency. The line description ability of ELSD also outperforms the previous works on the line matching task.
Improved Signed Distance Function for 2D Real-time SLAM and Accurate Localization
Jan 20, 2021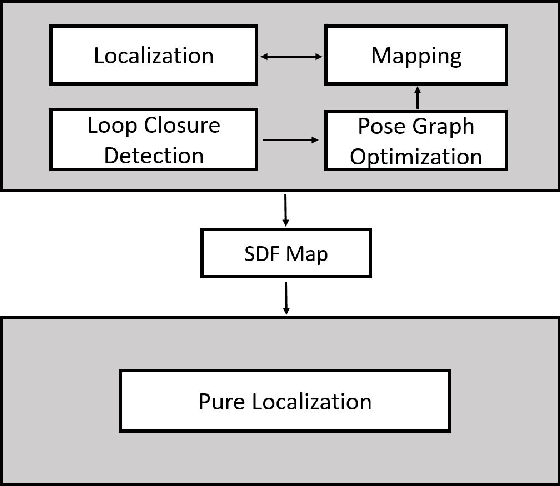



Accurate mapping and localization are very important for many industrial robotics applications. In this paper, we propose an improved Signed Distance Function (SDF) for both 2D SLAM and pure localization to improve the accuracy of mapping and localization. To achieve this goal, firstly we improved the back-end mapping to build a more accurate SDF map by extending the update range and building free space, etc. Secondly, to get more accurate pose estimation for the front-end, we proposed a new iterative registration method to align the current scan to the SDF submap by removing random outliers of laser scanners. Thirdly, we merged all the SDF submaps to produce an integrated SDF map for highly accurate pure localization. Experimental results show that based on the merged SDF map, a localization accuracy of a few millimeters (5mm) can be achieved globally within the map. We believe that this method is important for mobile robots working in scenarios where high localization accuracy matters.
PL-VINS: Real-Time Monocular Visual-Inertial SLAM with Point and Line Features
Oct 11, 2020
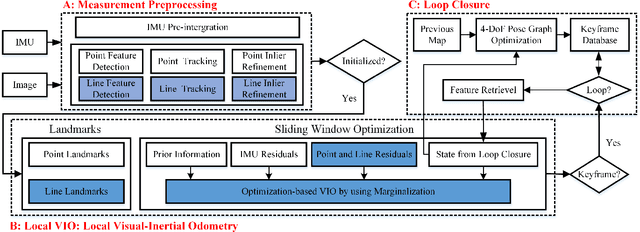

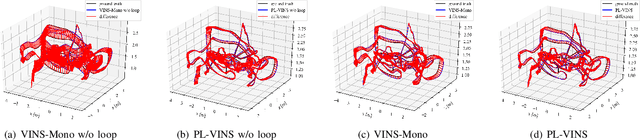
Leveraging line features to improve localization accuracy of point-based visual-inertial SLAM (VINS) is gaining interest as they provide additional constraints on scene structure. However, real-time performance when incorporating line features in VINS has not been addressed. This paper presents PL-VINS, a real-time optimization-based monocular VINS method with point and line features, developed based on the state-of-the-art point-based VINS-Mono \cite{vins}. We observe that current works use the LSD \cite{lsd} algorithm to extract line features; however, LSD is designed for scene shape representation instead of the pose estimation problem, which becomes the bottleneck for the real-time performance due to its high computational cost. In this paper, a modified LSD algorithm is presented by studying a hidden parameter tuning and length rejection strategy. The modified LSD can run at least three times as fast as LSD. Further, by representing space lines with the Pl\"{u}cker coordinates, the residual error in line estimation is modeled in terms of the point-to-line distance, which is then minimized by iteratively updating the minimum four-parameter orthonormal representation of the Pl\"{u}cker coordinates. Experiments in a public benchmark dataset show that the localization error of our method is 12-16\% less than that of VINS-Mono at the same pose update frequency. %For the benefit of the community, The source code of our method is available at: https://github.com/cnqiangfu/PL-VINS.