 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Generative Flow Network for Solving Vehicle Routing Problems
Mar 03, 2025Recent research into solving vehicle routing problems (VRPs) has gained significant traction, particularly through the application of deep (reinforcement) learning for end-to-end solution construction. However, many current construction-based neural solvers predominantly utilize Transformer architectures, which can face scalability challenges and struggle to produce diverse solutions. To address these limitations, we introduce a novel framework beyond Transformer-based approaches, i.e., Adversarial Generative Flow Networks (AGFN). This framework integrates the generative flow network (GFlowNet)-a probabilistic model inherently adept at generating diverse solutions (routes)-with a complementary model for discriminating (or evaluating) the solutions. These models are trained alternately in an adversarial manner to improve the overall solution quality, followed by a proposed hybrid decoding method to construct the solution. We apply the AGFN framework to solve the capacitated vehicle routing problem (CVRP) and travelling salesman problem (TSP), and our experimental results demonstrate that AGFN surpasses the popular construction-based neural solvers, showcasing strong generalization capabilities on synthetic and real-world benchmark instances.
Randomized Smoothing with Masked Inference for Adversarially Robust Text Classifications
May 11, 2023



Large-scale pre-trained language models have shown outstanding performance in a variety of NLP tasks. However, they are also known to be significantly brittle against specifically crafted adversarial examples, leading to increasing interest in probing the adversarial robustness of NLP systems. We introduce RSMI, a novel two-stage framework that combines randomized smoothing (RS) with masked inference (MI) to improve the adversarial robustness of NLP systems. RS transforms a classifier into a smoothed classifier to obtain robust representations, whereas MI forces a model to exploit the surrounding context of a masked token in an input sequence. RSMI improves adversarial robustness by 2 to 3 times over existing state-of-the-art methods on benchmark datasets. We also perform in-depth qualitative analysis to validate the effectiveness of the different stages of RSMI and probe the impact of its components through extensive ablations. By empirically proving the stability of RSMI, we put it forward as a practical method to robustly train large-scale NLP models. Our code and datasets are available at https://github.com/Han8931/rsmi_nlp
OpenOccupancy: A Large Scale Benchmark for Surrounding Semantic Occupancy Perception
Mar 07, 2023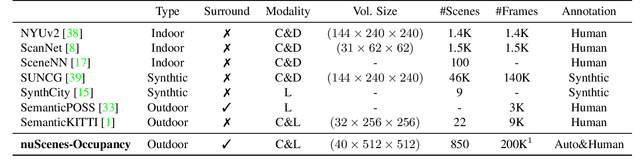
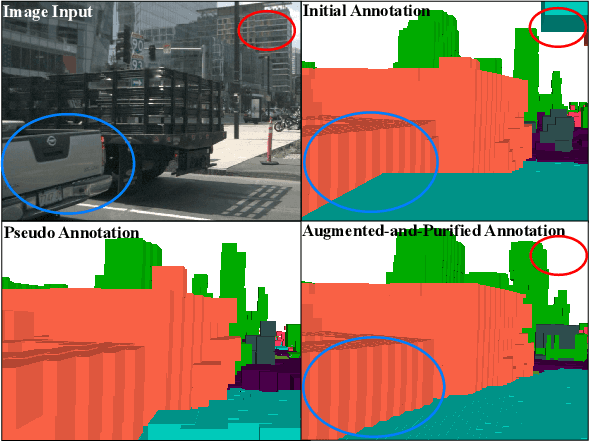
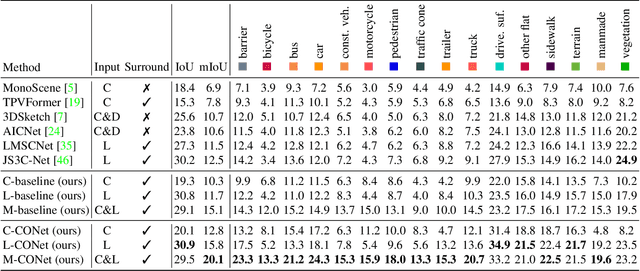
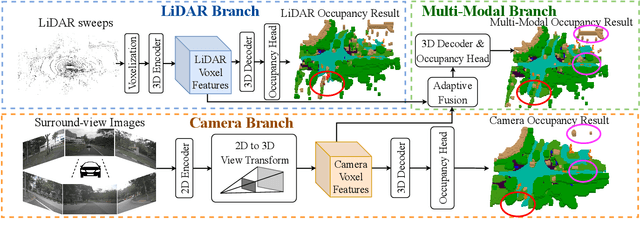
Semantic occupancy perception is essential for autonomous driving, as automated vehicles require a fine-grained perception of the 3D urban structures. However, existing relevant benchmarks lack diversity in urban scenes, and they only evaluate front-view predictions. Towards a comprehensive benchmarking of surrounding perception algorithms, we propose OpenOccupancy, which is the first surrounding semantic occupancy perception benchmark. In the OpenOccupancy benchmark, we extend the large-scale nuScenes dataset with dense semantic occupancy annotations. Previous annotations rely on LiDAR points superimposition, where some occupancy labels are missed due to sparse LiDAR channels. To mitigate the problem, we introduce the Augmenting And Purifying (AAP) pipeline to ~2x densify the annotations, where ~4000 human hours are involved in the labeling process. Besides, camera-based, LiDAR-based and multi-modal baselines are established for the OpenOccupancy benchmark. Furthermore, considering the complexity of surrounding occupancy perception lies in the computational burden of high-resolution 3D predictions, we propose the Cascade Occupancy Network (CONet) to refine the coarse prediction, which relatively enhances the performance by ~30% than the baseline. We hope the OpenOccupancy benchmark will boost the development of surrounding occupancy perception algorithms.
Crafting Monocular Cues and Velocity Guidance for Self-Supervised Multi-Frame Depth Learning
Aug 19, 2022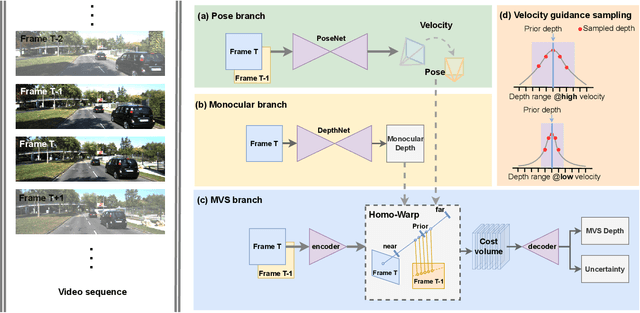
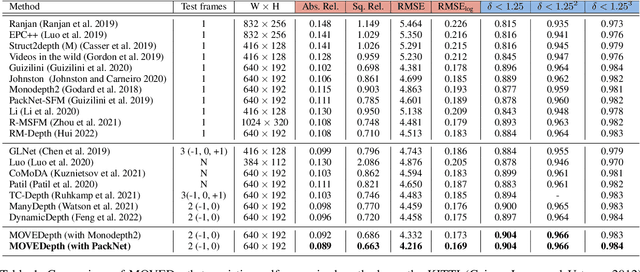
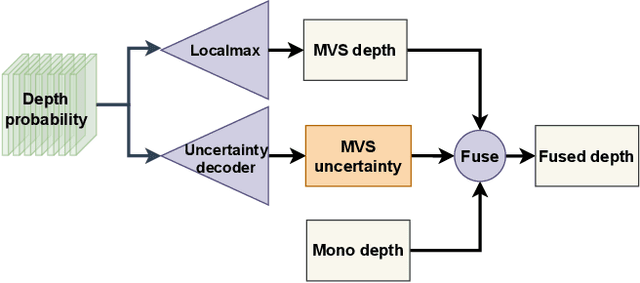
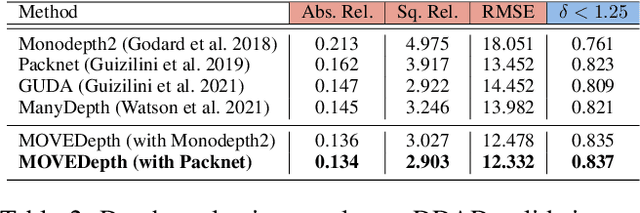
Self-supervised monocular methods can efficiently learn depth information of weakly textured surfaces or reflective objects. However, the depth accuracy is limited due to the inherent ambiguity in monocular geometric modeling. In contrast, multi-frame depth estimation methods improve the depth accuracy thanks to the success of Multi-View Stereo (MVS), which directly makes use of geometric constraints. Unfortunately, MVS often suffers from texture-less regions, non-Lambertian surfaces, and moving objects, especially in real-world video sequences without known camera motion and depth supervision. Therefore, we propose MOVEDepth, which exploits the MOnocular cues and VElocity guidance to improve multi-frame Depth learning. Unlike existing methods that enforce consistency between MVS depth and monocular depth, MOVEDepth boosts multi-frame depth learning by directly addressing the inherent problems of MVS. The key of our approach is to utilize monocular depth as a geometric priority to construct MVS cost volume, and adjust depth candidates of cost volume under the guidance of predicted camera velocity. We further fuse monocular depth and MVS depth by learning uncertainty in the cost volume, which results in a robust depth estimation against ambiguity in multi-view geometry. Extensive experiments show MOVEDepth achieves state-of-the-art performance: Compared with Monodepth2 and PackNet, our method relatively improves the depth accuracy by 20\% and 19.8\% on the KITTI benchmark. MOVEDepth also generalizes to the more challenging DDAD benchmark, relatively outperforming ManyDepth by 7.2\%. The code is available at https://github.com/JeffWang987/MOVEDepth.
MVSTER: Epipolar Transformer for Efficient Multi-View Stereo
Apr 15, 2022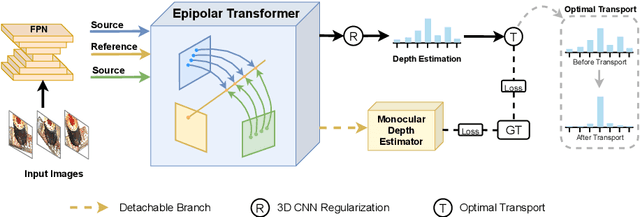



Learning-based Multi-View Stereo (MVS) methods warp source images into the reference camera frustum to form 3D volumes, which are fused as a cost volume to be regularized by subsequent networks. The fusing step plays a vital role in bridging 2D semantics and 3D spatial associations. However, previous methods utilize extra networks to learn 2D information as fusing cues, underusing 3D spatial correlations and bringing additional computation costs. Therefore, we present MVSTER, which leverages the proposed epipolar Transformer to learn both 2D semantics and 3D spatial associations efficiently. Specifically, the epipolar Transformer utilizes a detachable monocular depth estimator to enhance 2D semantics and uses cross-attention to construct data-dependent 3D associations along epipolar line. Additionally, MVSTER is built in a cascade structure, where entropy-regularized optimal transport is leveraged to propagate finer depth estimations in each stage. Extensive experiments show MVSTER achieves state-of-the-art reconstruction performance with significantly higher efficiency: Compared with MVSNet and CasMVSNet, our MVSTER achieves 34% and 14% relative improvements on the DTU benchmark, with 80% and 51% relative reductions in running time. MVSTER also ranks first on Tanks&Temples-Advanced among all published works. Code is released at https://github.com/JeffWang987.
A Unified Neural Coherence Model
Sep 01, 2019
Recently, neural approaches to coherence modeling have achieved state-of-the-art results in several evaluation tasks. However, we show that most of these models often fail on harder tasks with more realistic application scenarios. In particular, the existing models underperform on tasks that require the model to be sensitive to local contexts such as candidate ranking in conversational dialogue and in machine translation. In this paper, we propose a unified coherence model that incorporates sentence grammar, inter-sentence coherence relations, and global coherence patterns into a common neural framework. With extensive experiments on local and global discrimination tasks, we demonstrate that our proposed model outperforms existing models by a good margin, and establish a new state-of-the-art.