 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyOKP: One-Shot and Instance-Aware Object Keypoint Extraction with Pretrained ViT
Sep 15, 2023



Towards flexible object-centric visual perception, we propose a one-shot instance-aware object keypoint (OKP) extraction approach, AnyOKP, which leverages the powerful representation ability of pretrained vision transformer (ViT), and can obtain keypoints on multiple object instances of arbitrary category after learning from a support image. An off-the-shelf petrained ViT is directly deployed for generalizable and transferable feature extraction, which is followed by training-free feature enhancement. The best-prototype pairs (BPPs) are searched for in support and query images based on appearance similarity, to yield instance-unaware candidate keypoints.Then, the entire graph with all candidate keypoints as vertices are divided to sub-graphs according to the feature distributions on the graph edges. Finally, each sub-graph represents an object instance. AnyOKP is evaluated on real object images collected with the cameras of a robot arm, a mobile robot, and a surgical robot, which not only demonstrates the cross-category flexibility and instance awareness, but also show remarkable robustness to domain shift and viewpoint change.
MVSTER: Epipolar Transformer for Efficient Multi-View Stereo
Apr 15, 2022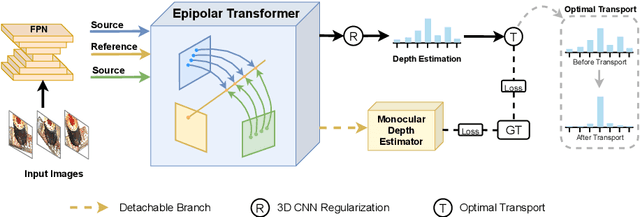



Learning-based Multi-View Stereo (MVS) methods warp source images into the reference camera frustum to form 3D volumes, which are fused as a cost volume to be regularized by subsequent networks. The fusing step plays a vital role in bridging 2D semantics and 3D spatial associations. However, previous methods utilize extra networks to learn 2D information as fusing cues, underusing 3D spatial correlations and bringing additional computation costs. Therefore, we present MVSTER, which leverages the proposed epipolar Transformer to learn both 2D semantics and 3D spatial associations efficiently. Specifically, the epipolar Transformer utilizes a detachable monocular depth estimator to enhance 2D semantics and uses cross-attention to construct data-dependent 3D associations along epipolar line. Additionally, MVSTER is built in a cascade structure, where entropy-regularized optimal transport is leveraged to propagate finer depth estimations in each stage. Extensive experiments show MVSTER achieves state-of-the-art reconstruction performance with significantly higher efficiency: Compared with MVSNet and CasMVSNet, our MVSTER achieves 34% and 14% relative improvements on the DTU benchmark, with 80% and 51% relative reductions in running time. MVSTER also ranks first on Tanks&Temples-Advanced among all published works. Code is released at https://github.com/JeffWang987.
ELSD: Efficient Line Segment Detector and Descriptor
Apr 29, 2021



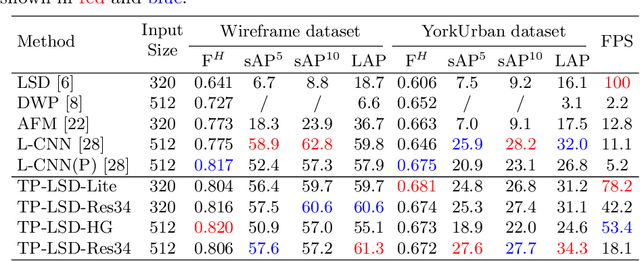
We present the novel Efficient Line Segment Detector and Descriptor (ELSD) to simultaneously detect line segments and extract their descriptors in an image. Unlike the traditional pipelines that conduct detection and description separately, ELSD utilizes a shared feature extractor for both detection and description, to provide the essential line features to the higher-level tasks like SLAM and image matching in real time. First, we design the one-stage compact model, and propose to use the mid-point, angle and length as the minimal representation of line segment, which also guarantees the center-symmetry. The non-centerness suppression is proposed to filter out the fragmented line segments caused by lines' intersections. The fine offset prediction is designed to refine the mid-point localization. Second, the line descriptor branch is integrated with the detector branch, and the two branches are jointly trained in an end-to-end manner. In the experiments, the proposed ELSD achieves the state-of-the-art performance on the Wireframe dataset and YorkUrban dataset, in both accuracy and efficiency. The line description ability of ELSD also outperforms the previous works on the line matching task.
Multi-frame Feature Aggregation for Real-time Instrument Segmentation in Endoscopic Video
Nov 17, 2020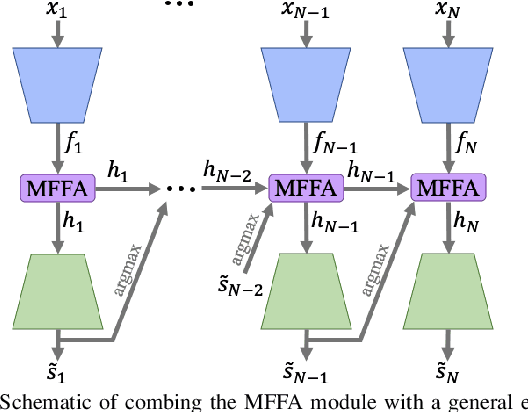
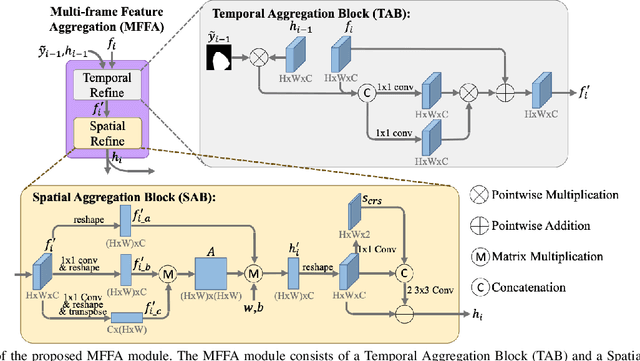
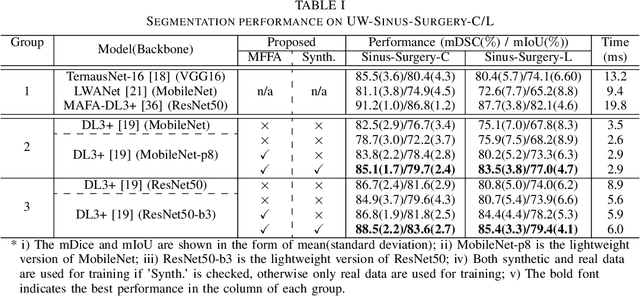
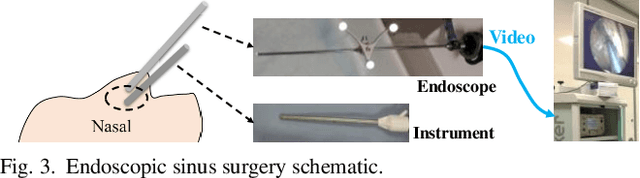
Deep learning-based methods have achieved promising results on surgical instrument segmentation. However, the high computation cost may limit the applications of deep models to time-sensitive tasks such as online surgical video analysis for robotic-assisted surgery. Also, current performance may still suffer from challenging conditions in surgical images such as various lighting conditions and the presence of blood. We propose a novel Multi-frame Feature Aggregation (MFFA) module that leverages information of neighboring frames for segmentation while reducing the influence of spatial misalignment between frames. The MFFA module also further aggregates features spatially based on the spatial self-attention mechanism. Neighboring frames usually have similar appearances, so we consider feature aggregation over a frame sequence as an iterative feature aggregation procedure. By distributing the computational workload of deep feature extraction over each frame in a sequence, we can use a lightweight encoder to reduce the computation costs. Moreover, public surgical videos usually are not labeled by frame, so we develop a method that can randomly synthesize a surgical frame sequence from a labeled frame to assist network training. We demonstrate that our approach achieves superior performance to corresponding deeper segmentation models on a public endoscopic sinus surgery dataset.
Contour Primitive of Interest Extraction Network Based on One-shot Learning for Object-Agnostic Vision Measurement
Oct 07, 2020
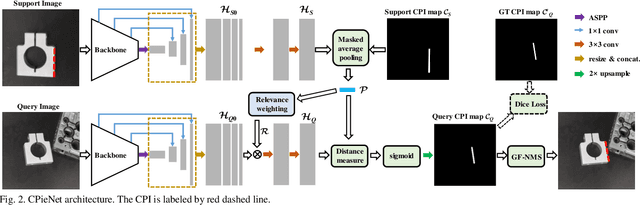
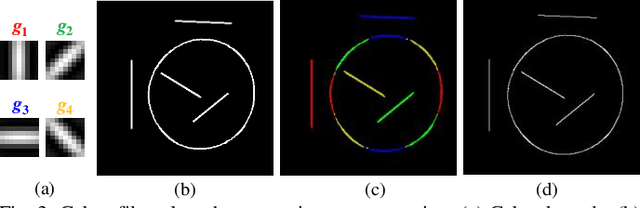

Image contour based vision measurement is widely applied in robot manipulation and industrial automation. It is appealing to realize object-agnostic vision system, which can be conveniently reused for various types of objects. We propose the contour primitive of interest extraction network (CPieNet) based on the one-shot learning framework. First, CPieNet is featured by that its contour primitive of interest (CPI) output, a designated regular contour part lying on a specified object, provides the essential geometric information for vision measurement. Second, CPieNet has the one-shot learning ability, utilizing a support sample to assist the perception of the novel object. To realize lower-cost training, we generate support-query sample pairs from unpaired online public images, which cover a wide range of object categories. To obtain single-pixel wide contour for precise measurement, the Gabor-filters based non-maximum suppression is designed to thin the raw contour. For the novel CPI extraction task, we built the Object Contour Primitives dataset using online public images, and the Robotic Object Contour Measurement dataset using a camera mounted on a robot. The effectiveness of the proposed methods is validated by a series of experiments.
TP-LSD: Tri-Points Based Line Segment Detector
Sep 11, 2020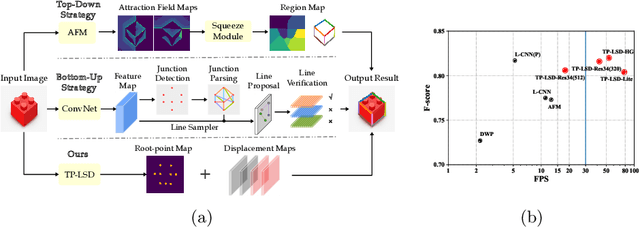
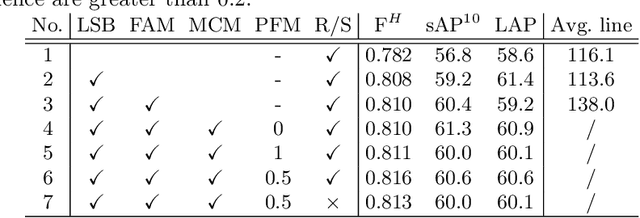

This paper proposes a novel deep convolutional model, Tri-Points Based Line Segment Detector (TP-LSD), to detect line segments in an image at real-time speed. The previous related methods typically use the two-step strategy, relying on either heuristic post-process or extra classifier. To realize one-step detection with a faster and more compact model, we introduce the tri-points representation, converting the line segment detection to the end-to-end prediction of a root-point and two endpoints for each line segment. TP-LSD has two branches: tri-points extraction branch and line segmentation branch. The former predicts the heat map of root-points and the two displacement maps of endpoints. The latter segments the pixels on straight lines out from background. Moreover, the line segmentation map is reused in the first branch as structural prior. We propose an additional novel evaluation metric and evaluate our method on Wireframe and YorkUrban datasets, demonstrating not only the competitive accuracy compared to the most recent methods, but also the real-time run speed up to 78 FPS with the $320\times 320$ input.
* Accepted by ECCV 2020
LC-GAN: Image-to-image Translation Based on Generative Adversarial Network for Endoscopic Images
Mar 10, 2020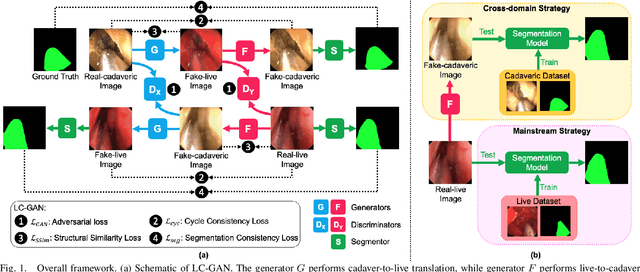
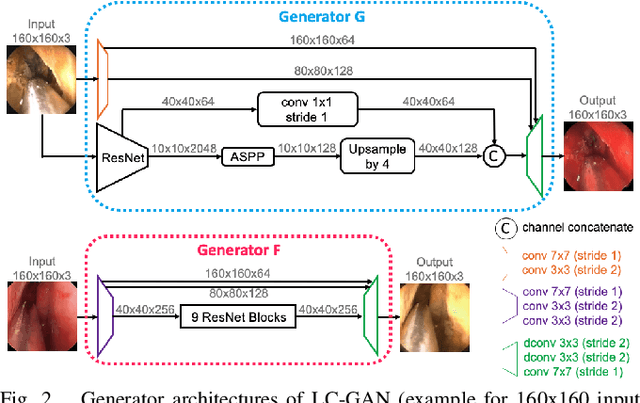

The intelligent perception of endoscopic vision is appealing in many computer-assisted and robotic surgeries. Achieving good vision-based analysis with deep learning techniques requires large labeled datasets, but manual data labeling is expensive and time-consuming in medical problems. When applying a trained model to a different but relevant dataset, a new labeled dataset may be required for training to avoid performance degradation. In this work, we investigate a novel cross-domain strategy to reduce the need for manual data labeling by proposing an image-to-image translation model called live-cadaver GAN (LC-GAN) based on generative adversarial networks (GANs). More specifically, we consider a situation when a labeled cadaveric surgery dataset is available while the task is instrument segmentation on a live surgery dataset. We train LC-GAN to learn the mappings between the cadaveric and live datasets. To achieve instrument segmentation on live images, we can first translate the live images to fake-cadaveric images with LC-GAN, and then perform segmentation on the fake-cadaveric images with models trained on the real cadaveric dataset. With this cross-domain strategy, we fully leverage the labeled cadaveric dataset for segmentation on live images without the need to label the live dataset again. Two generators with different architectures are designed for LC-GAN to make use of the deep feature representation learned from the cadaveric image based instrument segmentation task. Moreover, we propose structural similarity loss and segmentation consistency loss to improve the semantic consistency during translation. The results demonstrate that LC-GAN achieves better image-to-image translation results, and leads to improved segmentation performance in the proposed cross-domain segmentation task.
Towards Better Surgical Instrument Segmentation in Endoscopic Vision: Multi-Angle Feature Aggregation and Contour Supervision
Feb 25, 2020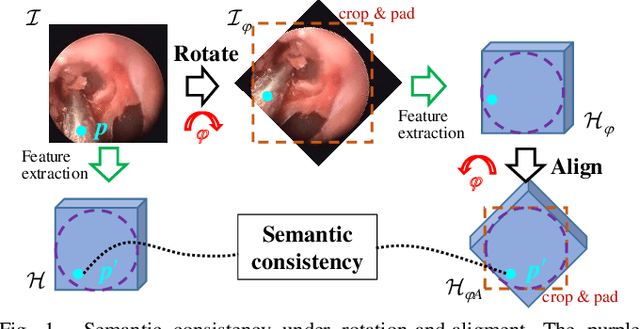
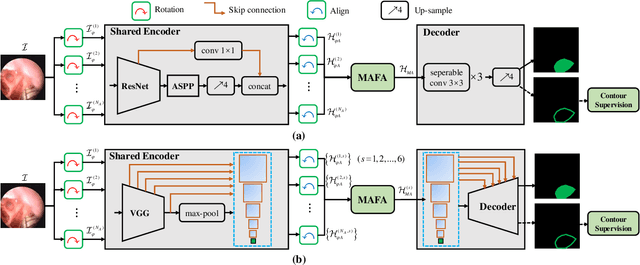
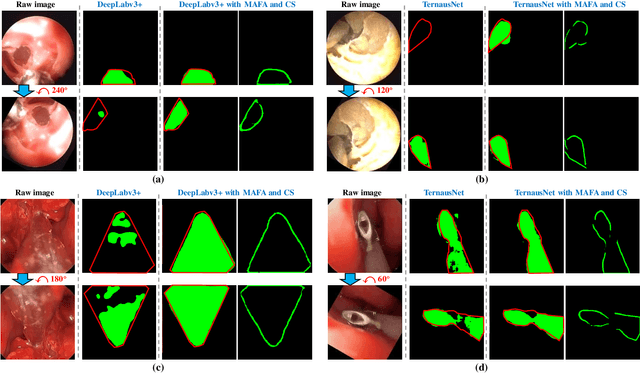
Accurate and real-time surgical instrument segmentation is important in the endoscopic vision of robot-assisted surgery, and significant challenges are posed by frequent instrument-tissue contacts and continuous change of observation perspective. For these challenging tasks more and more deep neural networks (DNN) models are designed in recent years. We are motivated to propose a general embeddable approach to improve these current DNN segmentation models without increasing the model parameter number. Firstly, observing the limited rotation-invariance performance of DNN, we proposed the Multi-Angle Feature Aggregation (MAFA) method, lever-aging active image rotation to gain richer visual cues and make the prediction more robust to instrument orientation changes. Secondly, in the end-to-end training stage, the auxiliary contour supervision is utilized to guide the model to learn the boundary awareness, so that the contour shape of segmentation mask is more precise. The effectiveness of the proposed methods is validated with ablation experiments con-ducted on novel Sinus-Surgery datasets.