 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLC-GAN: Image-to-image Translation Based on Generative Adversarial Network for Endoscopic Images
Paper and Code
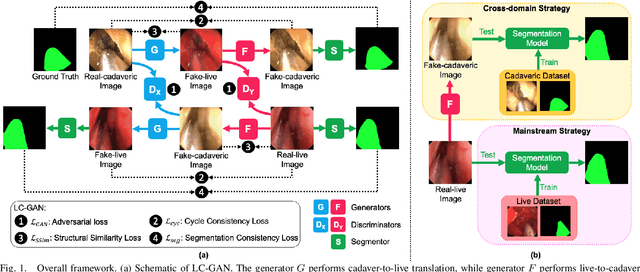
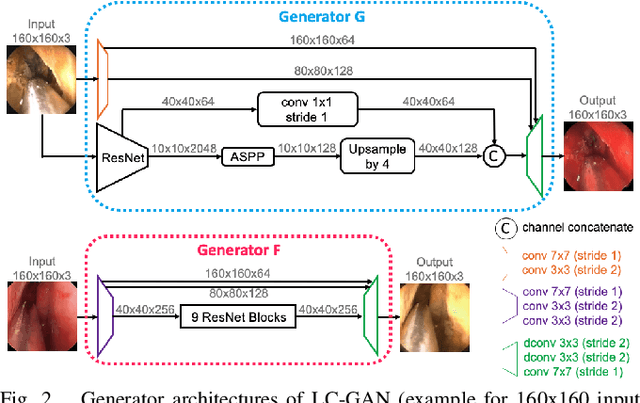

The intelligent perception of endoscopic vision is appealing in many computer-assisted and robotic surgeries. Achieving good vision-based analysis with deep learning techniques requires large labeled datasets, but manual data labeling is expensive and time-consuming in medical problems. When applying a trained model to a different but relevant dataset, a new labeled dataset may be required for training to avoid performance degradation. In this work, we investigate a novel cross-domain strategy to reduce the need for manual data labeling by proposing an image-to-image translation model called live-cadaver GAN (LC-GAN) based on generative adversarial networks (GANs). More specifically, we consider a situation when a labeled cadaveric surgery dataset is available while the task is instrument segmentation on a live surgery dataset. We train LC-GAN to learn the mappings between the cadaveric and live datasets. To achieve instrument segmentation on live images, we can first translate the live images to fake-cadaveric images with LC-GAN, and then perform segmentation on the fake-cadaveric images with models trained on the real cadaveric dataset. With this cross-domain strategy, we fully leverage the labeled cadaveric dataset for segmentation on live images without the need to label the live dataset again. Two generators with different architectures are designed for LC-GAN to make use of the deep feature representation learned from the cadaveric image based instrument segmentation task. Moreover, we propose structural similarity loss and segmentation consistency loss to improve the semantic consistency during translation. The results demonstrate that LC-GAN achieves better image-to-image translation results, and leads to improved segmentation performance in the proposed cross-domain segmentation task.