 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Data-driven Joint-level Calibration of Cable-driven Surgical Robots
Aug 02, 2024Knowing accurate joint positions is crucial for safe and precise control of laparoscopic surgical robots, especially for the automation of surgical sub-tasks. These robots have often been designed with cable-driven arms and tools because cables allow for larger motors to be placed at the base of the robot, further from the operating area where space is at a premium. However, by connecting the joint to its motor with a cable, any stretch in the cable can lead to errors in kinematic estimation from encoders at the motor, which can result in difficulties for accurate control of the surgical tool. In this work, we propose an efficient data-driven calibration of positioning joints of such robots, in this case the RAVEN-II surgical robotics research platform. While the calibration takes only 8-21 minutes, the accuracy of the calibrated joints remains high during a 6-hour heavily loaded operation, suggesting desirable feasibility in real practice. The calibration models take original robot states as input and are trained using zig-zag trajectories within a desired sparsity, requiring no additional sensors after training. Compared to fixed offset compensation, the Deep Neural Network calibration model can further reduce 76 percent of error and achieve accuracy of 0.104 deg, 0.120 deg, and 0.118 mm in joints 1, 2, and 3, respectively. In contrast to end-to-end models, experiments suggest that the DNN model achieves better accuracy and faster convergence when outputting the error to correct original inaccurate joint positions. Furthermore, a linear regression model is shown to have 160 times faster inference speed than DNN models for application within the 1000 Hz servo control loop, with slightly compromised accuracy.
Optimization of Trajectories for Machine Learning Training in Robot Accuracy Modeling
Jun 21, 2024Recently, machine learning (ML) methods have been developed for increasing the accuracy of robot mechanisms. Complex mechanical issues such as non-linear friction, backlash, flexibility of structure transmission elements can cause these errors and they are hard to model. ML requires training data and the above mechanical phenomena are highly dependent on position of the robot in the workspace and also on its velocity, especially near zero velocity in both directions where non-linearities such as Streibek and Coulomb friction are most pronounced. It is well known that success of ML methods depends on amount of training data and it is expensive/time consuming to collect data from physical robot motion. We therefore address the problem of searching for trajectories in the 6D space of positions and velocities which collect the most information in the least amount of time. This reduces to a special case of the traveling-salesman problem in that the robot must be programmed to visit sampled points in the position-velocity phase space most efficiently. Two goals of this work are 1) Computationally study the difficulty of the TSP in this application by applying it to X, Y, Z motion in 3D space (6D phase space) and 2) assess the effectiveness of an extremely simple Nearest Neighbor search algorithm compared to random sampling of the search space. Results confirm that Nearest Neighbor heuristic searching produces significantly better trajectories than random sampling in this application.
Ablation Study on Features in Learning-based Joints Calibration of Cable-driven Surgical Robots
Feb 14, 2023



With worldwide implementation, millions of surgeries are assisted by surgical robots. The cable-drive mechanism on many surgical robots allows flexible, light, and compact arms and tools. However, the slack and stretch of the cables and the backlash of the gears introduce inevitable errors from motor poses to joint poses, and thus forwarded to the pose and orientation of the end-effector. In this paper, a learning-based calibration using a deep neural network is proposed, which reduces the unloaded pose RMSE of joints 1, 2, 3 to 0.3003 deg, 0.2888 deg, 0.1565 mm, and loaded pose RMSE of joints 1, 2, 3 to 0.4456 deg, 0.3052 deg, 0.1900 mm, respectively. Then, removal ablation and inaccurate ablation are performed to study which features of the DNN model contribute to the calibration accuracy. The results suggest that raw joint poses and motor torques are the most important features. For joint poses, the removal ablation shows that DNN model can derive this information from end-effector pose and orientation. For motor torques, the direction is much more important than amplitude.
Real-time Virtual Intraoperative CT for Image Guided Surgery
Dec 05, 2021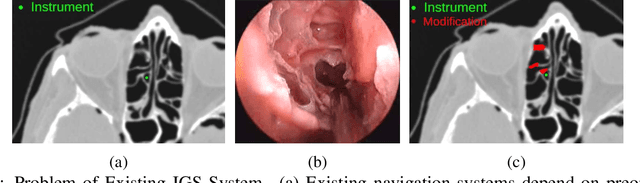
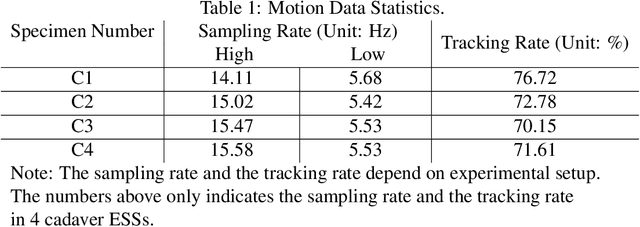
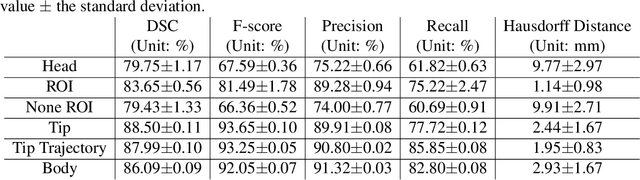
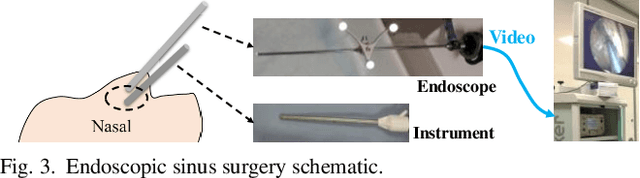
Abstract. Purpose: This paper presents a scheme for generating virtual intraoperative CT scans in order to improve surgical completeness in Endoscopic Sinus Surgeries (ESS). Approach: The work presents three methods, the tip motion-based, the tip trajectory-based, and the instrument based, along with non-parametric smoothing and Gaussian Process Regression, for virtual intraoperative CT generation. Results: The proposed methods studied and compared on ESS performed on cadavers. Surgical results show all three methods improve the Dice Similarity Coefficients > 86%, with F-score > 92% and precision > 89.91%. The tip trajectory-based method was found to have best performance and reached 96.87% precision in surgical completeness evaluation. Conclusions: This work demonstrated that virtual intraoperative CT scans improves the consistency between the actual surgical scene and the reference model, and improves surgical completeness in ESS. Comparing with actual intraoperative CT scans, the proposed scheme has no impact on existing surgical protocols, does not require extra hardware other than the one is already available in most ESS overcome the high costs, the repeated radiation, and the elongated anesthesia caused by actual intraoperative CTs, and is practical in ESS.
Real-time Informative Surgical Skill Assessment with Gaussian Process Learning
Dec 05, 2021
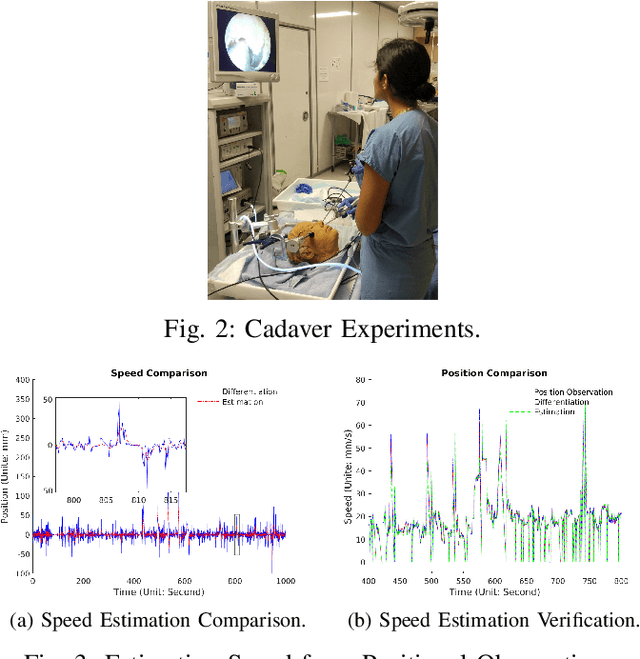
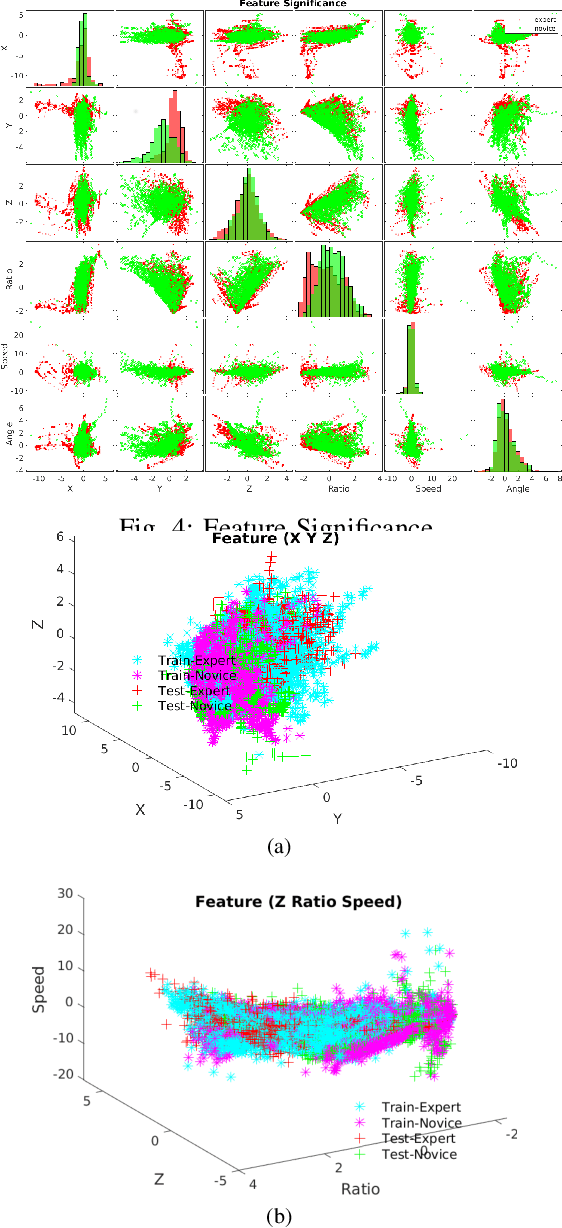
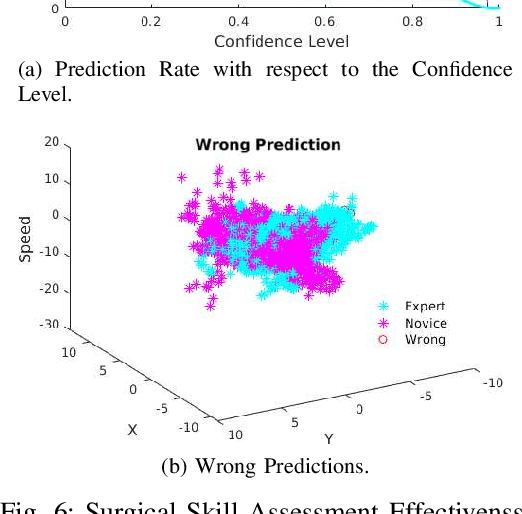
Endoscopic Sinus and Skull Base Surgeries (ESSBSs) is a challenging and potentially dangerous surgical procedure, and objective skill assessment is the key components to improve the effectiveness of surgical training, to re-validate surgeons' skills, and to decrease surgical trauma and the complication rate in operating rooms. Because of the complexity of surgical procedures, the variation of operation styles, and the fast development of new surgical skills, the surgical skill assessment remains a challenging problem. This work presents a novel Gaussian Process Learning-based heuristic automatic objective surgical skill assessment method for ESSBSs. Different with classical surgical skill assessment algorithms, the proposed method 1) utilizes the kinematic features in surgical instrument relative movements, instead of using specific surgical tasks or the statistics to assess skills in real-time; 2) provide informative feedback, instead of a summative scores; 3) has the ability to incrementally learn from new data, instead of depending on a fixed dataset. The proposed method projects the instrument movements into the endoscope coordinate to reduce the data dimensionality. It then extracts the kinematic features of the projected data and learns the relationship between surgical skill levels and the features with the Gaussian Process learning technique. The proposed method was verified in full endoscopic skull base and sinus surgeries on cadavers. These surgeries have different pathology, requires different treatment and has different complexities. The experimental results show that the proposed method reaches 100\% prediction precision for complete surgical procedures and 90\% precision for real-time prediction assessment.
Reducing Annotating Load: Active Learning with Synthetic Images in Surgical Instrument Segmentation
Aug 07, 2021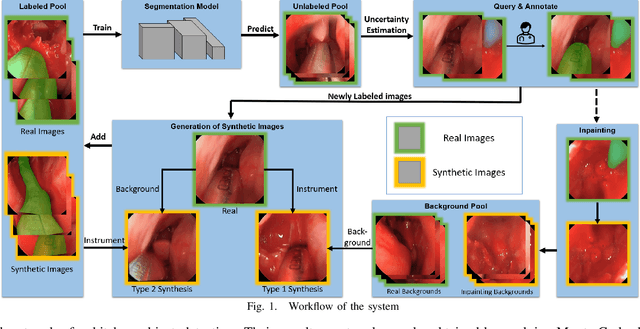
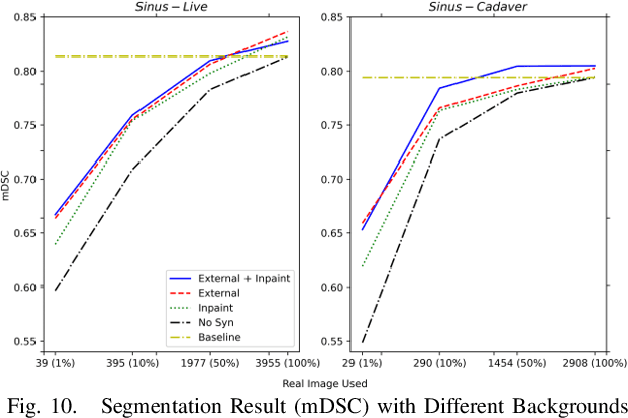
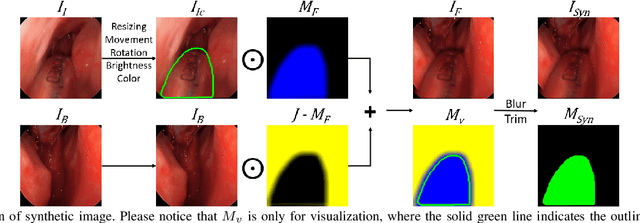
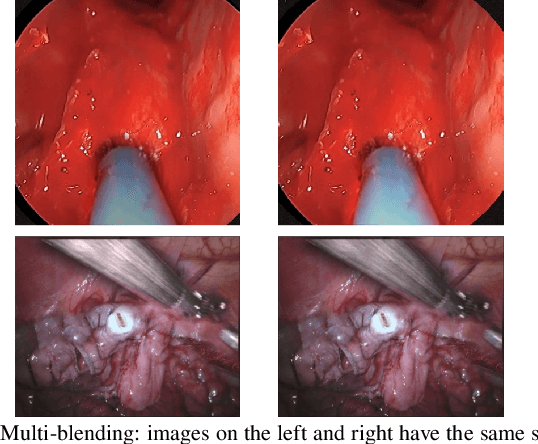
Accurate instrument segmentation in endoscopic vision of robot-assisted surgery is challenging due to reflection on the instruments and frequent contacts with tissue. Deep neural networks (DNN) show competitive performance and are in favor in recent years. However, the hunger of DNN for labeled data poses a huge workload of annotation. Motivated by alleviating this workload, we propose a general embeddable method to decrease the usage of labeled real images, using active generated synthetic images. In each active learning iteration, the most informative unlabeled images are first queried by active learning and then labeled. Next, synthetic images are generated based on these selected images. The instruments and backgrounds are cropped out and randomly combined with each other with blending and fusion near the boundary. The effectiveness of the proposed method is validated on 2 sinus surgery datasets and 1 intraabdominal surgery dataset. The results indicate a considerable improvement in performance, especially when the budget for annotation is small. The effectiveness of different types of synthetic images, blending methods, and external background are also studied. All the code is open-sourced at: https://github.com/HaonanPeng/active_syn_generator.
Evaluation of an Inflated Beam Model Applied to Everted Tubes
Jul 12, 2021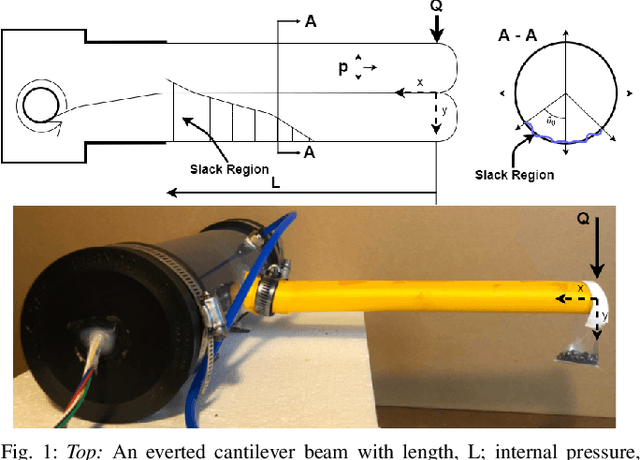
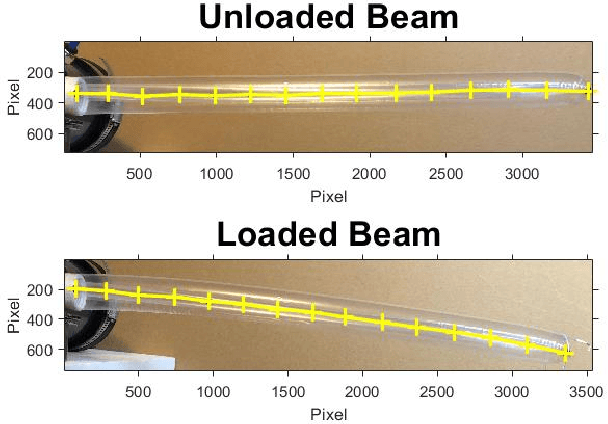
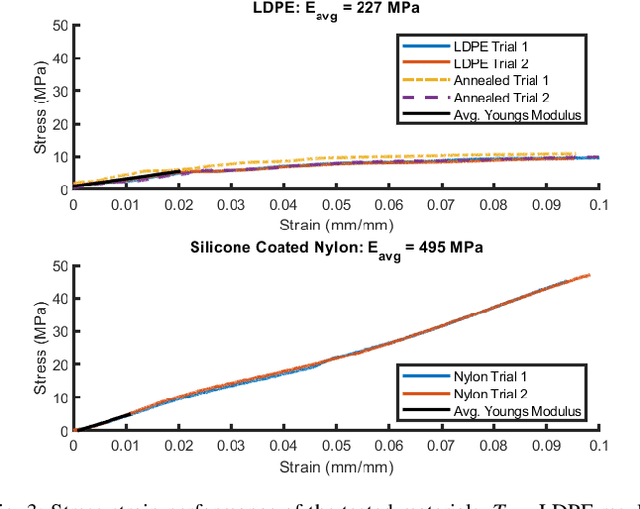
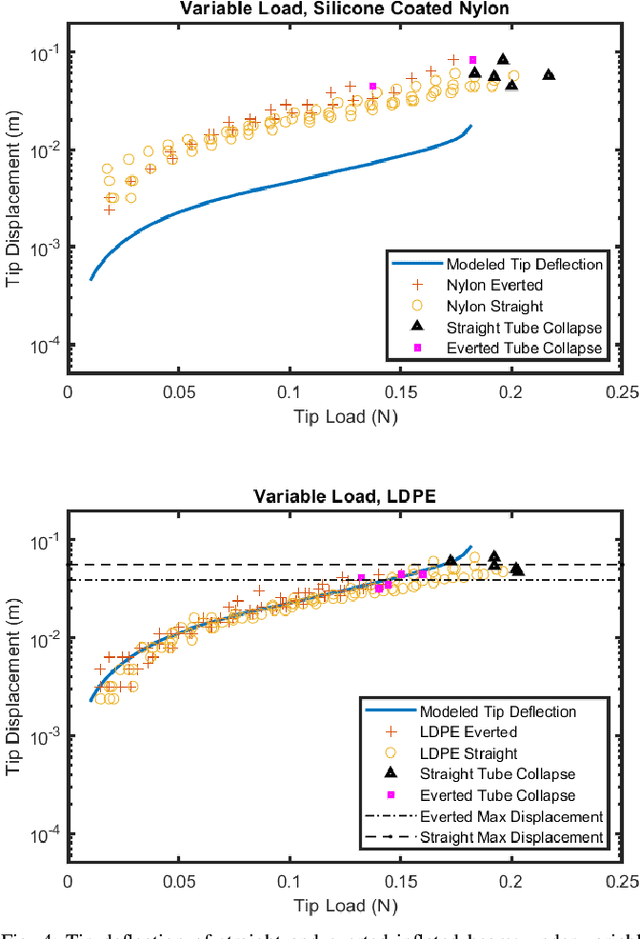
Everted tubes have often been modeled as inflated beams to determine transverse and axial buckling conditions. This paper seeks to validate the assumption that an everted tube can be modeled in this way. The tip deflections of everted and uneverted beams under transverse cantilever loads are compared with a tip deflection model that was first developed for aerospace applications. LDPE and silicone coated nylon beams were tested; everted and uneverted beams showed similar tip deflection. The literature model best fit the tip deflection of LDPE tubes with an average tip deflection error of 6 mm, while the nylon tubes had an average tip deflection error of 16.4 mm. Everted beams of both materials buckled at 83% of the theoretical buckling condition while straight beams collapsed at 109% of the theoretical buckling condition. The curvature of everted beams was estimated from a tip load and a known displacement showing relative errors of 14.2% and 17.3% for LDPE and nylon beams respectively. This paper shows a numerical method for determining inflated beam deflection. It also provides an iterative method for computing static tip pose and applied wall forces in a known environment.
Multi-frame Feature Aggregation for Real-time Instrument Segmentation in Endoscopic Video
Nov 17, 2020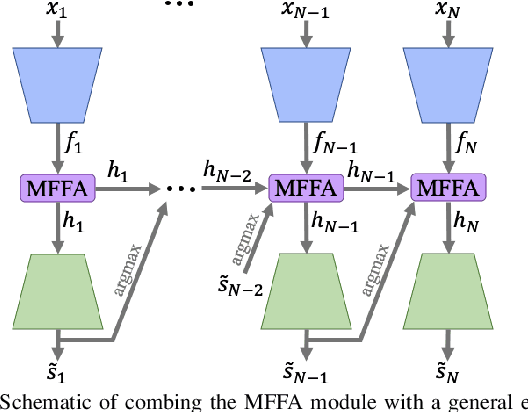
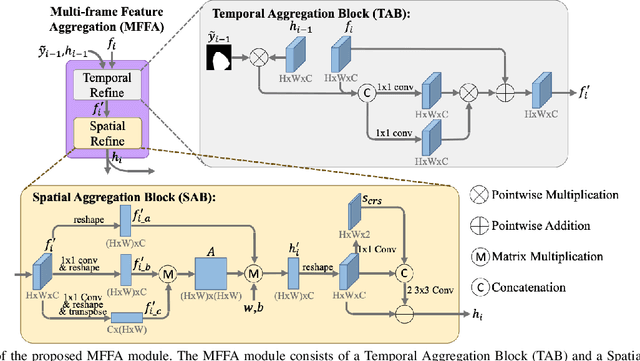
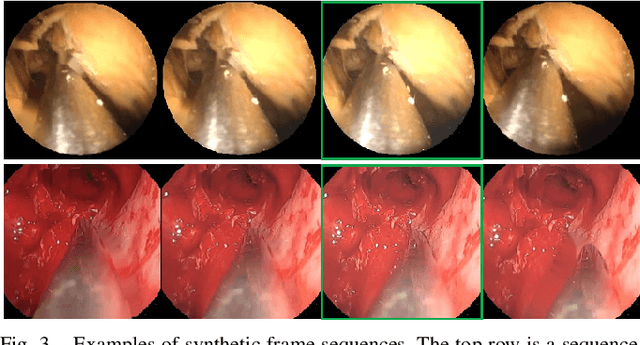
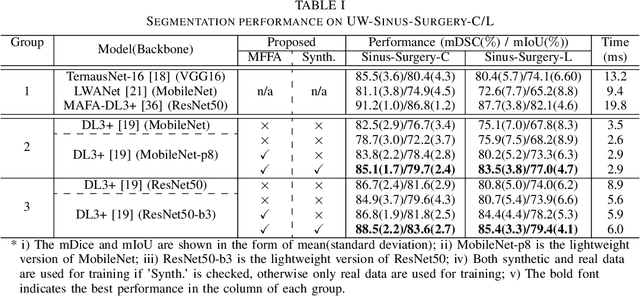
Deep learning-based methods have achieved promising results on surgical instrument segmentation. However, the high computation cost may limit the applications of deep models to time-sensitive tasks such as online surgical video analysis for robotic-assisted surgery. Also, current performance may still suffer from challenging conditions in surgical images such as various lighting conditions and the presence of blood. We propose a novel Multi-frame Feature Aggregation (MFFA) module that leverages information of neighboring frames for segmentation while reducing the influence of spatial misalignment between frames. The MFFA module also further aggregates features spatially based on the spatial self-attention mechanism. Neighboring frames usually have similar appearances, so we consider feature aggregation over a frame sequence as an iterative feature aggregation procedure. By distributing the computational workload of deep feature extraction over each frame in a sequence, we can use a lightweight encoder to reduce the computation costs. Moreover, public surgical videos usually are not labeled by frame, so we develop a method that can randomly synthesize a surgical frame sequence from a labeled frame to assist network training. We demonstrate that our approach achieves superior performance to corresponding deeper segmentation models on a public endoscopic sinus surgery dataset.
LC-GAN: Image-to-image Translation Based on Generative Adversarial Network for Endoscopic Images
Mar 10, 2020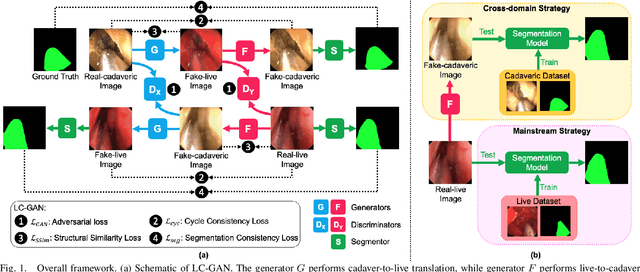
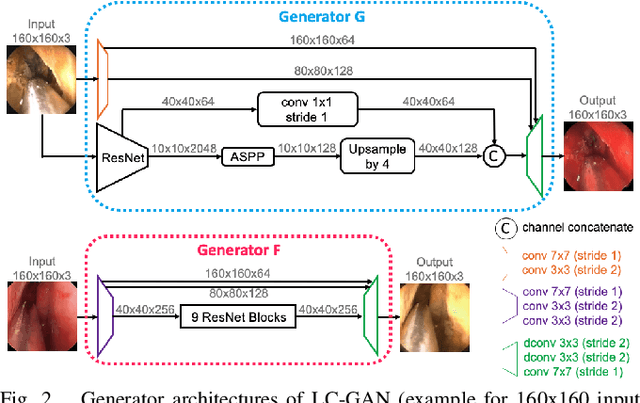

The intelligent perception of endoscopic vision is appealing in many computer-assisted and robotic surgeries. Achieving good vision-based analysis with deep learning techniques requires large labeled datasets, but manual data labeling is expensive and time-consuming in medical problems. When applying a trained model to a different but relevant dataset, a new labeled dataset may be required for training to avoid performance degradation. In this work, we investigate a novel cross-domain strategy to reduce the need for manual data labeling by proposing an image-to-image translation model called live-cadaver GAN (LC-GAN) based on generative adversarial networks (GANs). More specifically, we consider a situation when a labeled cadaveric surgery dataset is available while the task is instrument segmentation on a live surgery dataset. We train LC-GAN to learn the mappings between the cadaveric and live datasets. To achieve instrument segmentation on live images, we can first translate the live images to fake-cadaveric images with LC-GAN, and then perform segmentation on the fake-cadaveric images with models trained on the real cadaveric dataset. With this cross-domain strategy, we fully leverage the labeled cadaveric dataset for segmentation on live images without the need to label the live dataset again. Two generators with different architectures are designed for LC-GAN to make use of the deep feature representation learned from the cadaveric image based instrument segmentation task. Moreover, we propose structural similarity loss and segmentation consistency loss to improve the semantic consistency during translation. The results demonstrate that LC-GAN achieves better image-to-image translation results, and leads to improved segmentation performance in the proposed cross-domain segmentation task.
Towards Better Surgical Instrument Segmentation in Endoscopic Vision: Multi-Angle Feature Aggregation and Contour Supervision
Feb 25, 2020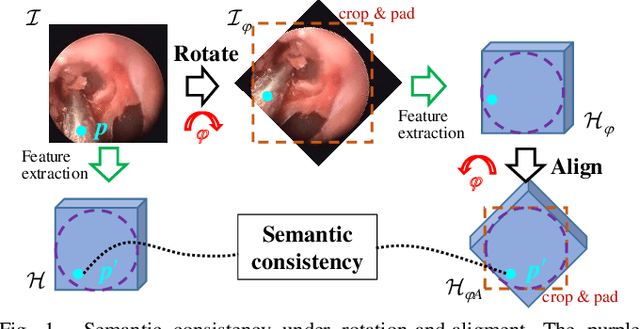
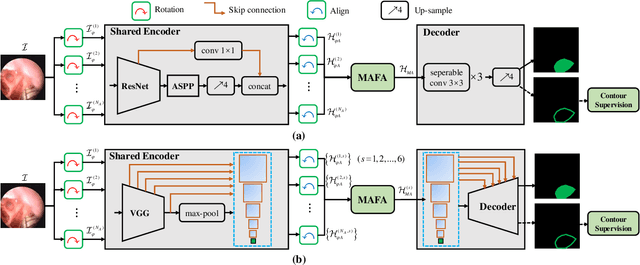
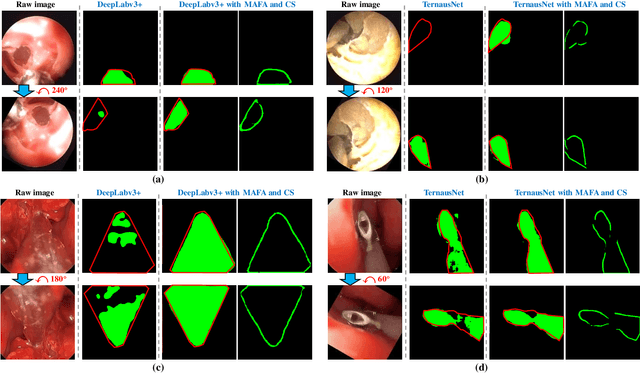
Accurate and real-time surgical instrument segmentation is important in the endoscopic vision of robot-assisted surgery, and significant challenges are posed by frequent instrument-tissue contacts and continuous change of observation perspective. For these challenging tasks more and more deep neural networks (DNN) models are designed in recent years. We are motivated to propose a general embeddable approach to improve these current DNN segmentation models without increasing the model parameter number. Firstly, observing the limited rotation-invariance performance of DNN, we proposed the Multi-Angle Feature Aggregation (MAFA) method, lever-aging active image rotation to gain richer visual cues and make the prediction more robust to instrument orientation changes. Secondly, in the end-to-end training stage, the auxiliary contour supervision is utilized to guide the model to learn the boundary awareness, so that the contour shape of segmentation mask is more precise. The effectiveness of the proposed methods is validated with ablation experiments con-ducted on novel Sinus-Surgery datasets.