 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-frame Feature Aggregation for Real-time Instrument Segmentation in Endoscopic Video
Paper and Code
Nov 17, 2020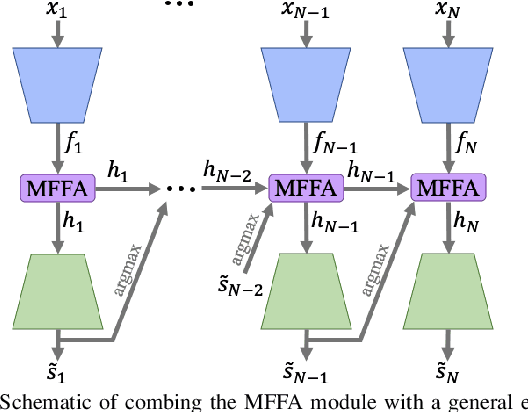
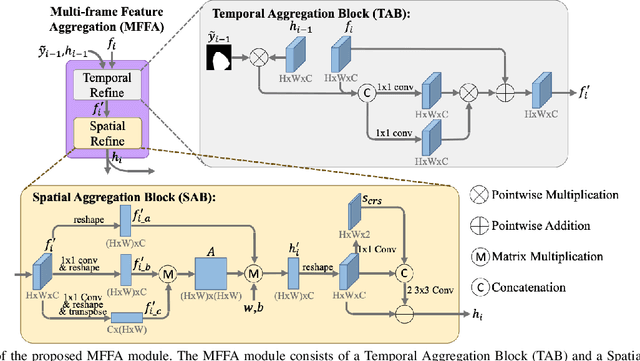
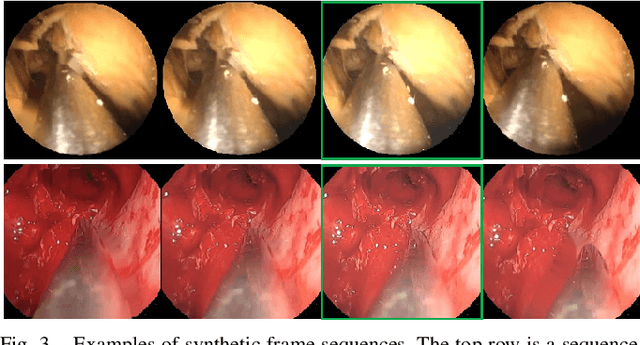
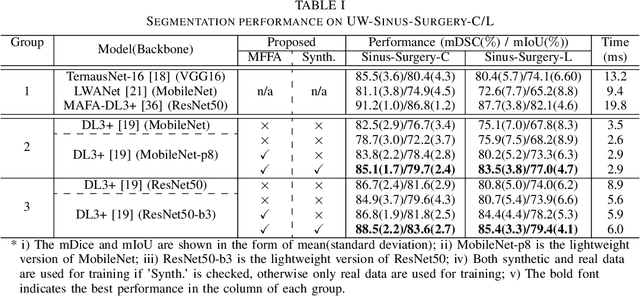
Deep learning-based methods have achieved promising results on surgical instrument segmentation. However, the high computation cost may limit the applications of deep models to time-sensitive tasks such as online surgical video analysis for robotic-assisted surgery. Also, current performance may still suffer from challenging conditions in surgical images such as various lighting conditions and the presence of blood. We propose a novel Multi-frame Feature Aggregation (MFFA) module that leverages information of neighboring frames for segmentation while reducing the influence of spatial misalignment between frames. The MFFA module also further aggregates features spatially based on the spatial self-attention mechanism. Neighboring frames usually have similar appearances, so we consider feature aggregation over a frame sequence as an iterative feature aggregation procedure. By distributing the computational workload of deep feature extraction over each frame in a sequence, we can use a lightweight encoder to reduce the computation costs. Moreover, public surgical videos usually are not labeled by frame, so we develop a method that can randomly synthesize a surgical frame sequence from a labeled frame to assist network training. We demonstrate that our approach achieves superior performance to corresponding deeper segmentation models on a public endoscopic sinus surgery dataset.