 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVSTER: Epipolar Transformer for Efficient Multi-View Stereo
Paper and Code
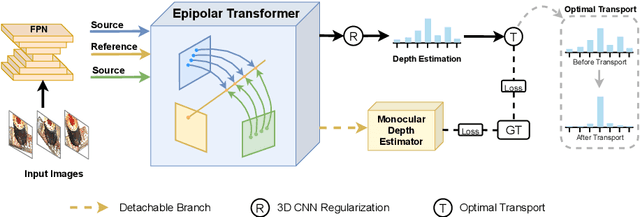



Learning-based Multi-View Stereo (MVS) methods warp source images into the reference camera frustum to form 3D volumes, which are fused as a cost volume to be regularized by subsequent networks. The fusing step plays a vital role in bridging 2D semantics and 3D spatial associations. However, previous methods utilize extra networks to learn 2D information as fusing cues, underusing 3D spatial correlations and bringing additional computation costs. Therefore, we present MVSTER, which leverages the proposed epipolar Transformer to learn both 2D semantics and 3D spatial associations efficiently. Specifically, the epipolar Transformer utilizes a detachable monocular depth estimator to enhance 2D semantics and uses cross-attention to construct data-dependent 3D associations along epipolar line. Additionally, MVSTER is built in a cascade structure, where entropy-regularized optimal transport is leveraged to propagate finer depth estimations in each stage. Extensive experiments show MVSTER achieves state-of-the-art reconstruction performance with significantly higher efficiency: Compared with MVSNet and CasMVSNet, our MVSTER achieves 34% and 14% relative improvements on the DTU benchmark, with 80% and 51% relative reductions in running time. MVSTER also ranks first on Tanks&Temples-Advanced among all published works. Code is released at https://github.com/JeffWang987.