 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSufficient Conditions for Unique Optimizer of Two-Dimensional Atomic Norm Minimization Under Multiple Frequencies
May 04, 2026Atomic norm minimization (ANM) has been extensively applied for gridless angle estimation. However, with the increase of the number of antennas and the communication frequencies in massive MIMO systems, the accompanying beam squint effect significantly degrades angle estimation accuracy. Existing solutions either address this issue only in the one-dimensional (1D) SIMO case, or decouple the two-dimensional (2D) angle estimation into two separate 1D problems, which fails to achieve the optimal solution. In this paper, we employ the multi-frequency model to characterize the beam squint effect in MIMO channels and propose a multi-frequency version of the ANM objective for corresponding 2D angle estimation. To efficiently retrieve the angle parameters, we prove the existence of the equivalent semi-definite program formulation of the ANM objective and develop an algorithm based on the alternating direction method of multipliers for its solutions. Moreover, we derive the certification conditions of this objective to guarantee the existence of a unique optimal solution.
Geometry-Aware Localized Watermarking for Copyright Protection in Embedding-as-a-Service
Apr 13, 2026Embedding-as-a-Service (EaaS) has become an important semantic infrastructure for natural language and multimedia applications, but it is highly vulnerable to model stealing and copyright infringement. Existing EaaS watermarking methods face a fundamental robustness--utility--verifiability tension: trigger-based methods are fragile to paraphrasing, transformation-based methods are sensitive to dimensional perturbation, and region-based methods may incur false positives due to coincidental geometric affinity. To address this problem, we propose GeoMark, a geometry-aware localized watermarking framework for EaaS copyright protection. GeoMark uses a natural in-manifold embedding as a shared watermark target, constructs geometry-separated anchors with explicit target--anchor margins, and activates watermark injection only within adaptive local neighborhoods. This design decouples where watermarking is triggered from what ownership is attributed to, achieving localized triggering and centralized attribution. Experiments on four benchmark datasets show that GeoMark preserves downstream utility and geometric fidelity while maintaining robust copyright verification under paraphrasing, dimensional perturbation, and CSE (Clustering, Selection, Elimination) attacks, with improved verification stability and low false-positive risk.
A Knowledge-Informed Pretrained Model for Causal Discovery
Mar 21, 2026Causal discovery has been widely studied, yet many existing methods rely on strong assumptions or fall into two extremes: either depending on costly interventional signals or partial ground truth as strong priors, or adopting purely data driven paradigms with limited guidance, which hinders practical deployment. Motivated by real-world scenarios where only coarse domain knowledge is available, we propose a knowledge-informed pretrained model for causal discovery that integrates weak prior knowledge as a principled middle ground. Our model adopts a dual source encoder-decoder architecture to process observational data in a knowledge-informed way. We design a diverse pretraining dataset and a curriculum learning strategy that smoothly adapts the model to varying prior strengths across mechanisms, graph densities, and variable scales. Extensive experiments on in-distribution, out-of distribution, and real-world datasets demonstrate consistent improvements over existing baselines, with strong robustness and practical applicability.
MARE: Multimodal Alignment and Reinforcement for Explainable Deepfake Detection via Vision-Language Models
Jan 29, 2026Deepfake detection is a widely researched topic that is crucial for combating the spread of malicious content, with existing methods mainly modeling the problem as classification or spatial localization. The rapid advancements in generative models impose new demands on Deepfake detection. In this paper, we propose multimodal alignment and reinforcement for explainable Deepfake detection via vision-language models, termed MARE, which aims to enhance the accuracy and reliability of Vision-Language Models (VLMs) in Deepfake detection and reasoning. Specifically, MARE designs comprehensive reward functions, incorporating reinforcement learning from human feedback (RLHF), to incentivize the generation of text-spatially aligned reasoning content that adheres to human preferences. Besides, MARE introduces a forgery disentanglement module to capture intrinsic forgery traces from high-level facial semantics, thereby improving its authenticity detection capability. We conduct thorough evaluations on the reasoning content generated by MARE. Both quantitative and qualitative experimental results demonstrate that MARE achieves state-of-the-art performance in terms of accuracy and reliability.
Hierarchically Block-Sparse Recovery With Prior Support Information
Nov 09, 2025We provide new recovery bounds for hierarchical compressed sensing (HCS) based on prior support information (PSI). A detailed PSI-enabled reconstruction model is formulated using various forms of PSI. The hierarchical block orthogonal matching pursuit with PSI (HiBOMP-P) algorithm is designed in a recursive form to reliably recover hierarchically block-sparse signals. We derive exact recovery conditions (ERCs) measured by the mutual incoherence property (MIP), wherein hierarchical MIP concepts are proposed, and further develop reconstructible sparsity levels to reveal sufficient conditions for ERCs. Leveraging these MIP analyses, we present several extended insights, including reliable recovery conditions in noisy scenarios and the optimal hierarchical structure for cases where sparsity is not equal to zero. Our results further confirm that HCS offers improved recovery performance even when the prior information does not overlap with the true support set, whereas existing methods heavily rely on this overlap, thereby compromising performance if it is absent.
A Multimodal Deviation Perceiving Framework for Weakly-Supervised Temporal Forgery Localization
Jul 22, 2025Current researches on Deepfake forensics often treat detection as a classification task or temporal forgery localization problem, which are usually restrictive, time-consuming, and challenging to scale for large datasets. To resolve these issues, we present a multimodal deviation perceiving framework for weakly-supervised temporal forgery localization (MDP), which aims to identify temporal partial forged segments using only video-level annotations. The MDP proposes a novel multimodal interaction mechanism (MI) and an extensible deviation perceiving loss to perceive multimodal deviation, which achieves the refined start and end timestamps localization of forged segments. Specifically, MI introduces a temporal property preserving cross-modal attention to measure the relevance between the visual and audio modalities in the probabilistic embedding space. It could identify the inter-modality deviation and construct comprehensive video features for temporal forgery localization. To explore further temporal deviation for weakly-supervised learning, an extensible deviation perceiving loss has been proposed, aiming at enlarging the deviation of adjacent segments of the forged samples and reducing that of genuine samples. Extensive experiments demonstrate the effectiveness of the proposed framework and achieve comparable results to fully-supervised approaches in several evaluation metrics.
FDBPL: Faster Distillation-Based Prompt Learning for Region-Aware Vision-Language Models Adaptation
May 23, 2025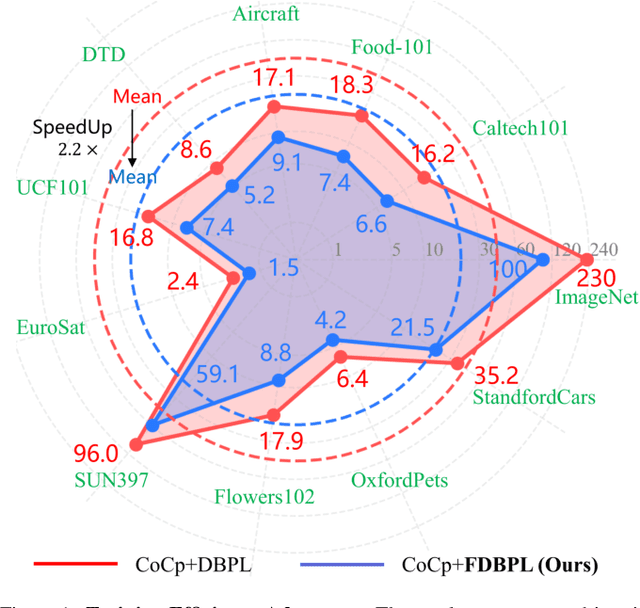
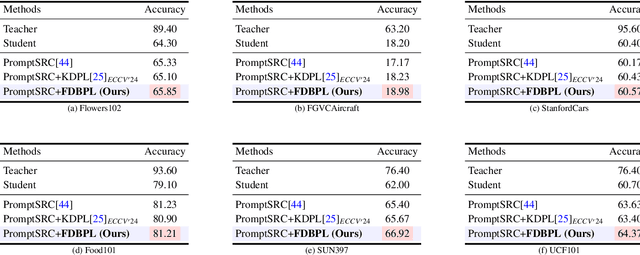
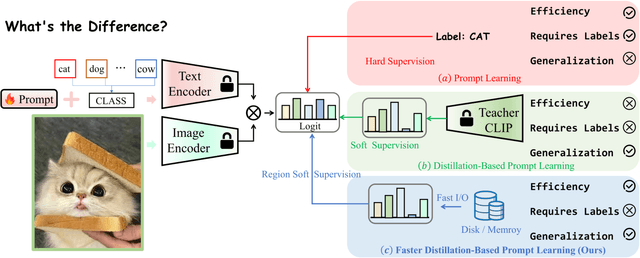
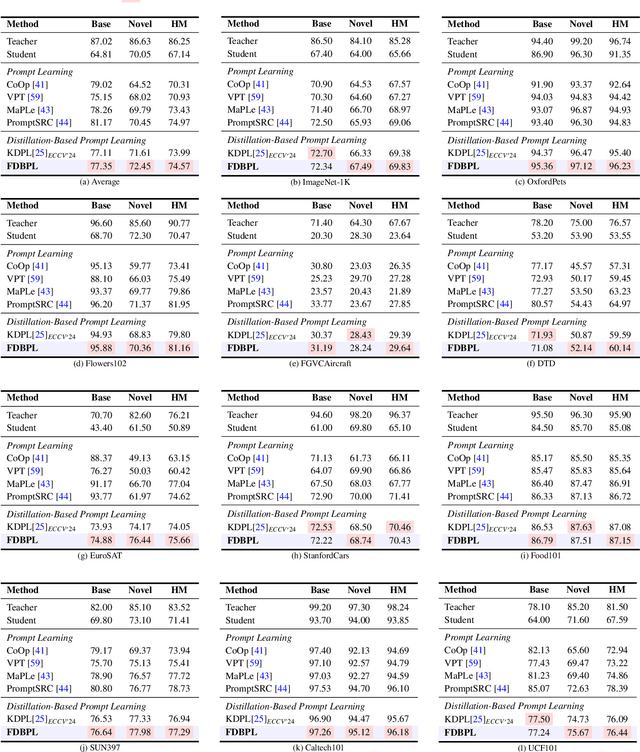
Prompt learning as a parameter-efficient method that has been widely adopted to adapt Vision-Language Models (VLMs) to downstream tasks. While hard-prompt design requires domain expertise and iterative optimization, soft-prompt methods rely heavily on task-specific hard labels, limiting their generalization to unseen categories. Recent popular distillation-based prompt learning methods improve generalization by exploiting larger teacher VLMs and unsupervised knowledge transfer, yet their repetitive teacher model online inference sacrifices the inherent training efficiency advantage of prompt learning. In this paper, we propose {{\large {\textbf{F}}}}aster {{\large {\textbf{D}}}}istillation-{{\large {\textbf{B}}}}ased {{\large {\textbf{P}}}}rompt {{\large {\textbf{L}}}}earning (\textbf{FDBPL}), which addresses these issues by sharing soft supervision contexts across multiple training stages and implementing accelerated I/O. Furthermore, FDBPL introduces a region-aware prompt learning paradigm with dual positive-negative prompt spaces to fully exploit randomly cropped regions that containing multi-level information. We propose a positive-negative space mutual learning mechanism based on similarity-difference learning, enabling student CLIP models to recognize correct semantics while learning to reject weakly related concepts, thereby improving zero-shot performance. Unlike existing distillation-based prompt learning methods that sacrifice parameter efficiency for generalization, FDBPL maintains dual advantages of parameter efficiency and strong downstream generalization. Comprehensive evaluations across 11 datasets demonstrate superior performance in base-to-new generalization, cross-dataset transfer, and robustness tests, achieving $2.2\times$ faster training speed.
Image Recognition with Online Lightweight Vision Transformer: A Survey
May 06, 2025The Transformer architecture has achieved significant success in natural language processing, motivating its adaptation to computer vision tasks. Unlike convolutional neural networks, vision transformers inherently capture long-range dependencies and enable parallel processing, yet lack inductive biases and efficiency benefits, facing significant computational and memory challenges that limit its real-world applicability. This paper surveys various online strategies for generating lightweight vision transformers for image recognition, focusing on three key areas: Efficient Component Design, Dynamic Network, and Knowledge Distillation. We evaluate the relevant exploration for each topic on the ImageNet-1K benchmark, analyzing trade-offs among precision, parameters, throughput, and more to highlight their respective advantages, disadvantages, and flexibility. Finally, we propose future research directions and potential challenges in the lightweighting of vision transformers with the aim of inspiring further exploration and providing practical guidance for the community. Project Page: https://github.com/ajxklo/Lightweight-VIT
Weakly-supervised Audio Temporal Forgery Localization via Progressive Audio-language Co-learning Network
May 03, 2025Audio temporal forgery localization (ATFL) aims to find the precise forgery regions of the partial spoof audio that is purposefully modified. Existing ATFL methods rely on training efficient networks using fine-grained annotations, which are obtained costly and challenging in real-world scenarios. To meet this challenge, in this paper, we propose a progressive audio-language co-learning network (LOCO) that adopts co-learning and self-supervision manners to prompt localization performance under weak supervision scenarios. Specifically, an audio-language co-learning module is first designed to capture forgery consensus features by aligning semantics from temporal and global perspectives. In this module, forgery-aware prompts are constructed by using utterance-level annotations together with learnable prompts, which can incorporate semantic priors into temporal content features dynamically. In addition, a forgery localization module is applied to produce forgery proposals based on fused forgery-class activation sequences. Finally, a progressive refinement strategy is introduced to generate pseudo frame-level labels and leverage supervised semantic contrastive learning to amplify the semantic distinction between real and fake content, thereby continuously optimizing forgery-aware features. Extensive experiments show that the proposed LOCO achieves SOTA performance on three public benchmarks.
Task Consistent Prototype Learning for Incremental Few-shot Semantic Segmentation
Oct 16, 2024



Incremental Few-Shot Semantic Segmentation (iFSS) tackles a task that requires a model to continually expand its segmentation capability on novel classes using only a few annotated examples. Typical incremental approaches encounter a challenge that the objective of the base training phase (fitting base classes with sufficient instances) does not align with the incremental learning phase (rapidly adapting to new classes with less forgetting). This disconnect can result in suboptimal performance in the incremental setting. This study introduces a meta-learning-based prototype approach that encourages the model to learn how to adapt quickly while preserving previous knowledge. Concretely, we mimic the incremental evaluation protocol during the base training session by sampling a sequence of pseudo-incremental tasks. Each task in the simulated sequence is trained using a meta-objective to enable rapid adaptation without forgetting. To enhance discrimination among class prototypes, we introduce prototype space redistribution learning, which dynamically updates class prototypes to establish optimal inter-prototype boundaries within the prototype space. Extensive experiments on iFSS datasets built upon PASCAL and COCO benchmarks show the advanced performance of the proposed approach, offering valuable insights for addressing iFSS challenges.