 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Cross-image Encoding for Few-shot Segmentation
Aug 22, 2023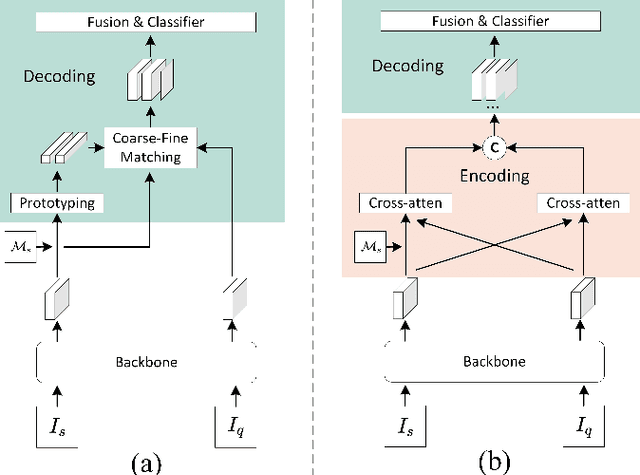
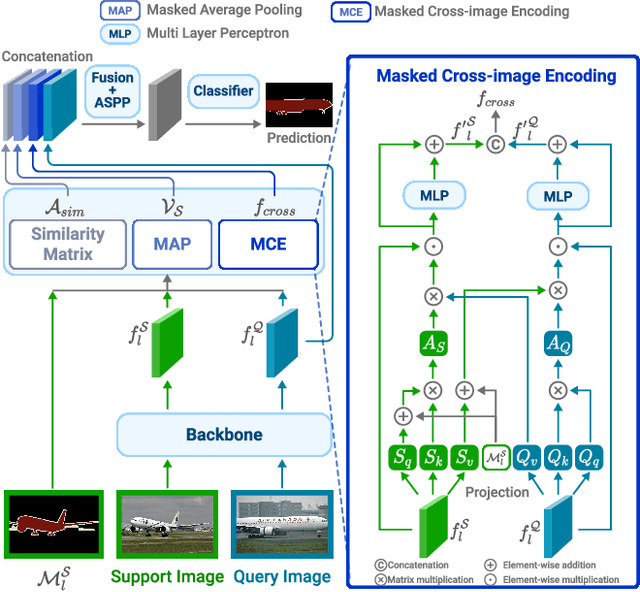

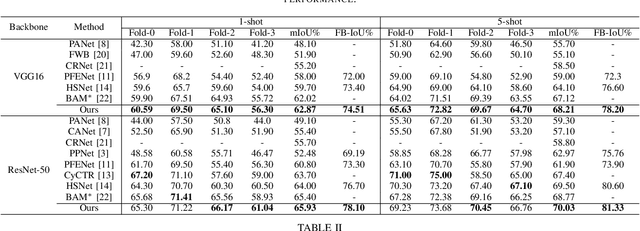
Few-shot segmentation (FSS) is a dense prediction task that aims to infer the pixel-wise labels of unseen classes using only a limited number of annotated images. The key challenge in FSS is to classify the labels of query pixels using class prototypes learned from the few labeled support exemplars. Prior approaches to FSS have typically focused on learning class-wise descriptors independently from support images, thereby ignoring the rich contextual information and mutual dependencies among support-query features. To address this limitation, we propose a joint learning method termed Masked Cross-Image Encoding (MCE), which is designed to capture common visual properties that describe object details and to learn bidirectional inter-image dependencies that enhance feature interaction. MCE is more than a visual representation enrichment module; it also considers cross-image mutual dependencies and implicit guidance. Experiments on FSS benchmarks PASCAL-$5^i$ and COCO-$20^i$ demonstrate the advanced meta-learning ability of the proposed method.
Spatial-temporal Analysis for Automated Concrete Workability Estimation
Jul 26, 2022

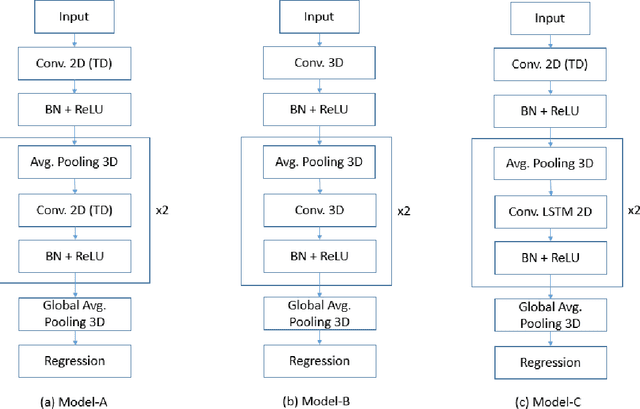
Concrete workability measure is mostly determined based on subjective assessment of a certified assessor with visual inspections. The potential human error in measuring the workability and the resulting unnecessary adjustments for the workability is a major challenge faced by the construction industry, leading to significant costs, material waste and delay. In this paper, we try to apply computer vision techniques to observe the concrete mixing process and estimate the workability. Specifically, we collected the video data and then built three different deep neural networks for spatial-temporal regression. The pilot study demonstrates a practical application with computer vision techniques to estimate the concrete workability during the mixing process.
Self-attention on Multi-Shifted Windows for Scene Segmentation
Jul 10, 2022
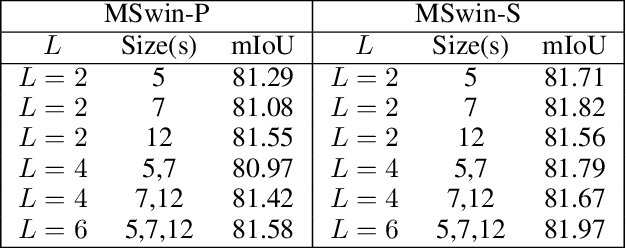
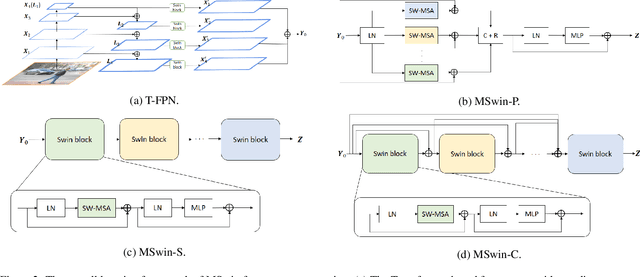
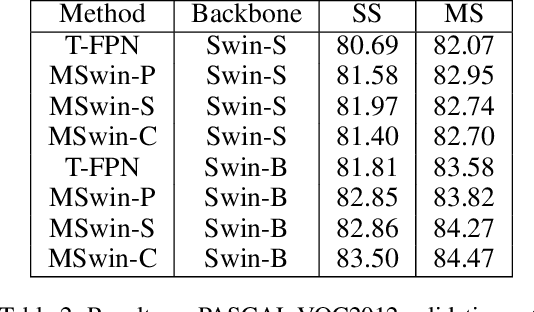
Scene segmentation in images is a fundamental yet challenging problem in visual content understanding, which is to learn a model to assign every image pixel to a categorical label. One of the challenges for this learning task is to consider the spatial and semantic relationships to obtain descriptive feature representations, so learning the feature maps from multiple scales is a common practice in scene segmentation. In this paper, we explore the effective use of self-attention within multi-scale image windows to learn descriptive visual features, then propose three different strategies to aggregate these feature maps to decode the feature representation for dense prediction. Our design is based on the recently proposed Swin Transformer models, which totally discards convolution operations. With the simple yet effective multi-scale feature learning and aggregation, our models achieve very promising performance on four public scene segmentation datasets, PASCAL VOC2012, COCO-Stuff 10K, ADE20K and Cityscapes.
Horizontal and Vertical Attention in Transformers
Jul 10, 2022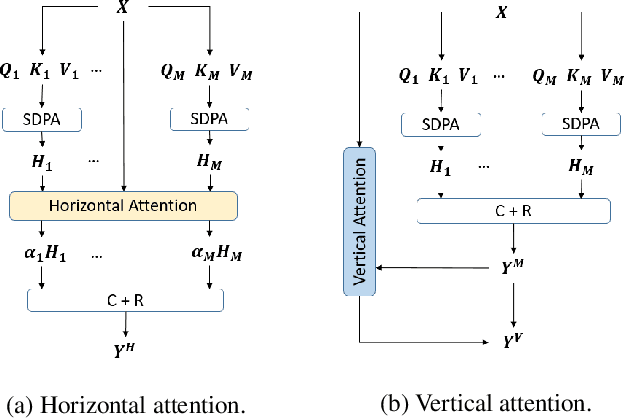

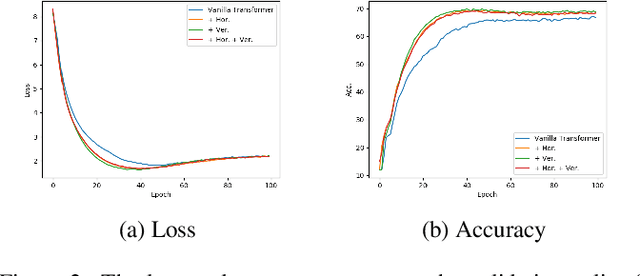
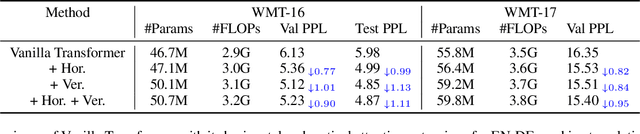
Transformers are built upon multi-head scaled dot-product attention and positional encoding, which aim to learn the feature representations and token dependencies. In this work, we focus on enhancing the distinctive representation by learning to augment the feature maps with the self-attention mechanism in Transformers. Specifically, we propose the horizontal attention to re-weight the multi-head output of the scaled dot-product attention before dimensionality reduction, and propose the vertical attention to adaptively re-calibrate channel-wise feature responses by explicitly modelling inter-dependencies among different channels. We demonstrate the Transformer models equipped with the two attentions have a high generalization capability across different supervised learning tasks, with a very minor additional computational cost overhead. The proposed horizontal and vertical attentions are highly modular, which can be inserted into various Transformer models to further improve the performance. Our code is available in the supplementary material.
Unsupervised Learning on 3D Point Clouds by Clustering and Contrasting
Feb 14, 2022
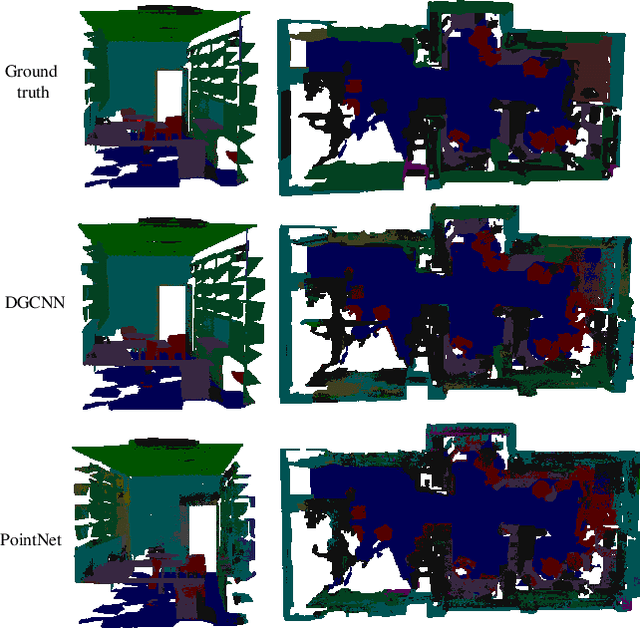
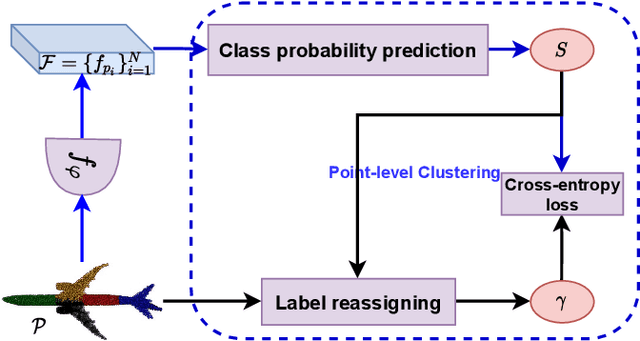
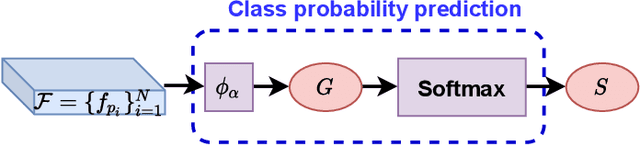
Learning from unlabeled or partially labeled data to alleviate human labeling remains a challenging research topic in 3D modeling. Along this line, unsupervised representation learning is a promising direction to auto-extract features without human intervention. This paper proposes a general unsupervised approach, named \textbf{ConClu}, to perform the learning of point-wise and global features by jointly leveraging point-level clustering and instance-level contrasting. Specifically, for one thing, we design an Expectation-Maximization (EM) like soft clustering algorithm that provides local supervision to extract discriminating local features based on optimal transport. We show that this criterion extends standard cross-entropy minimization to an optimal transport problem, which we solve efficiently using a fast variant of the Sinkhorn-Knopp algorithm. For another, we provide an instance-level contrasting method to learn the global geometry, which is formulated by maximizing the similarity between two augmentations of one point cloud. Experimental evaluations on downstream applications such as 3D object classification and semantic segmentation demonstrate the effectiveness of our framework and show that it can outperform state-of-the-art techniques.
COTReg:Coupled Optimal Transport based Point Cloud Registration
Dec 29, 2021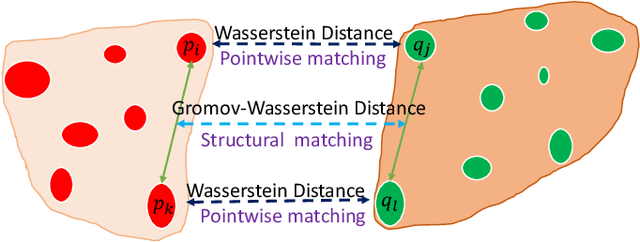

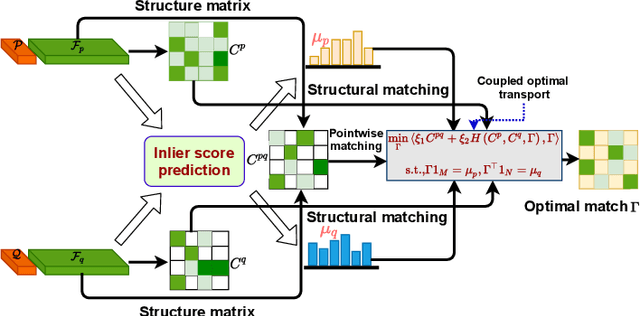
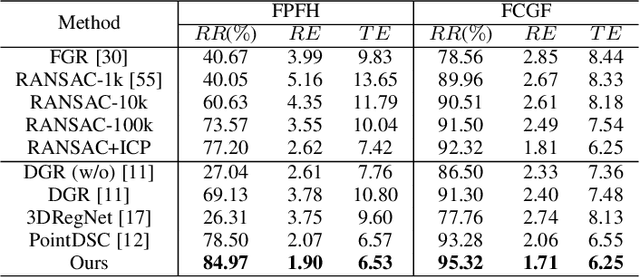
Generating a set of high-quality correspondences or matches is one of the most critical steps in point cloud registration. This paper proposes a learning framework COTReg by jointly considering the pointwise and structural matchings to predict correspondences of 3D point cloud registration. Specifically, we transform the two matchings into a Wasserstein distance-based and a Gromov-Wasserstein distance-based optimizations, respectively. Thus the task of establishing the correspondences can be naturally reshaped to a coupled optimal transport problem. Furthermore, we design a network to predict the confidence score of being an inlier for each point of the point clouds, which provides the overlap region information to generate correspondences. Our correspondence prediction pipeline can be easily integrated into either learning-based features like FCGF or traditional descriptors like FPFH. We conducted comprehensive experiments on 3DMatch, KITTI, 3DCSR, and ModelNet40 benchmarks, showing the state-of-art performance of the proposed method.
Distribution-aware Margin Calibration for Semantic Segmentation in Images
Dec 21, 2021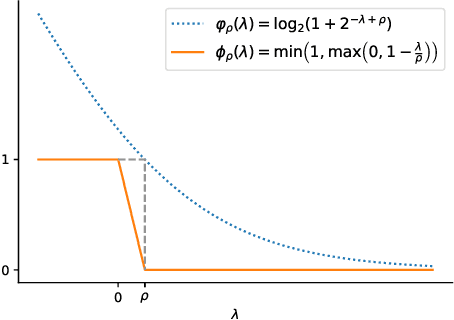
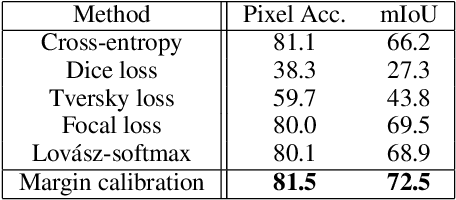
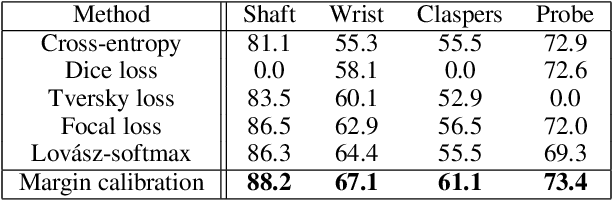
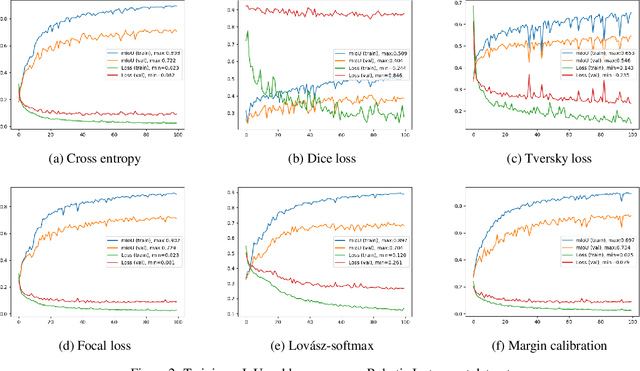
The Jaccard index, also known as Intersection-over-Union (IoU), is one of the most critical evaluation metrics in image semantic segmentation. However, direct optimization of IoU score is very difficult because the learning objective is neither differentiable nor decomposable. Although some algorithms have been proposed to optimize its surrogates, there is no guarantee provided for the generalization ability. In this paper, we propose a margin calibration method, which can be directly used as a learning objective, for an improved generalization of IoU over the data-distribution, underpinned by a rigid lower bound. This scheme theoretically ensures a better segmentation performance in terms of IoU score. We evaluated the effectiveness of the proposed margin calibration method on seven image datasets, showing substantial improvements in IoU score over other learning objectives using deep segmentation models.
Multi-layer Feature Aggregation for Deep Scene Parsing Models
Nov 04, 2020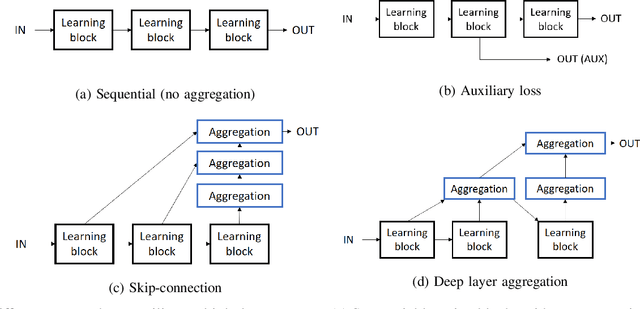
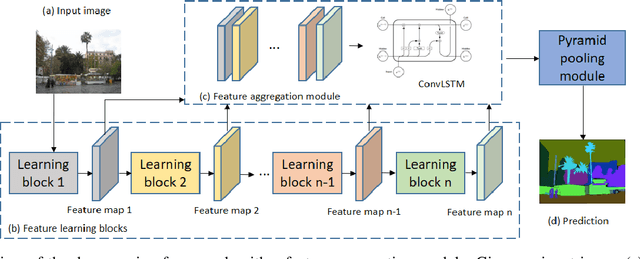
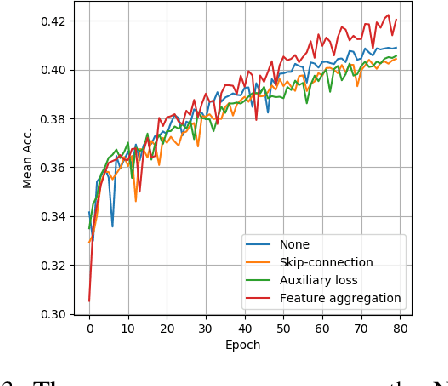
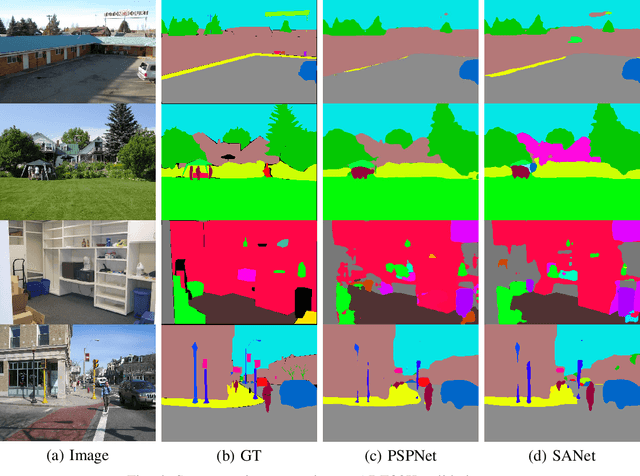
Scene parsing from images is a fundamental yet challenging problem in visual content understanding. In this dense prediction task, the parsing model assigns every pixel to a categorical label, which requires the contextual information of adjacent image patches. So the challenge for this learning task is to simultaneously describe the geometric and semantic properties of objects or a scene. In this paper, we explore the effective use of multi-layer feature outputs of the deep parsing networks for spatial-semantic consistency by designing a novel feature aggregation module to generate the appropriate global representation prior, to improve the discriminative power of features. The proposed module can auto-select the intermediate visual features to correlate the spatial and semantic information. At the same time, the multiple skip connections form a strong supervision, making the deep parsing network easy to train. Extensive experiments on four public scene parsing datasets prove that the deep parsing network equipped with the proposed feature aggregation module can achieve very promising results.
Distribution-aware Margin Calibration for Medical Image Segmentation
Nov 03, 2020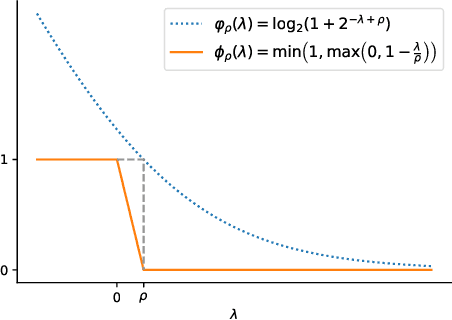


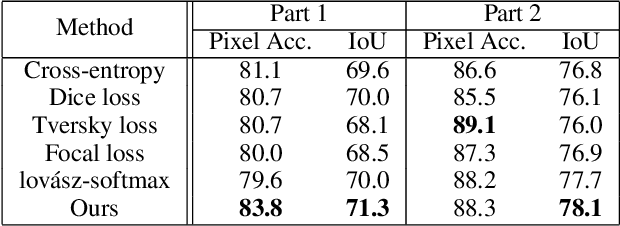
The Jaccard index, also known as Intersection-over-Union (IoU score), is one of the most critical evaluation metrics in medical image segmentation. However, directly optimizing the mean IoU (mIoU) score over multiple objective classes is an open problem. Although some algorithms have been proposed to optimize its surrogates, there is no guarantee provided for their generalization ability. In this paper, we present a novel data-distribution-aware margin calibration method for a better generalization of the mIoU over the whole data-distribution, underpinned by a rigid lower bound. This scheme ensures a better segmentation performance in terms of IoU scores in practice. We evaluate the effectiveness of the proposed margin calibration method on two medical image segmentation datasets, showing substantial improvements of IoU scores over other learning schemes using deep segmentation models.
Parameter Efficient Deep Neural Networks with Bilinear Projections
Nov 03, 2020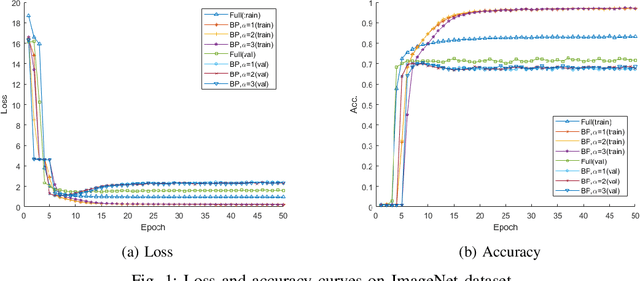
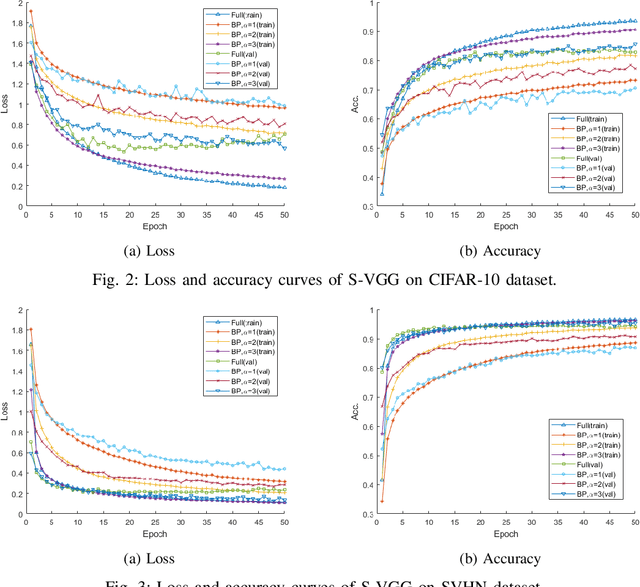
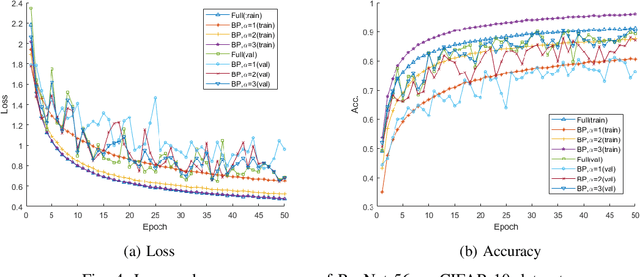
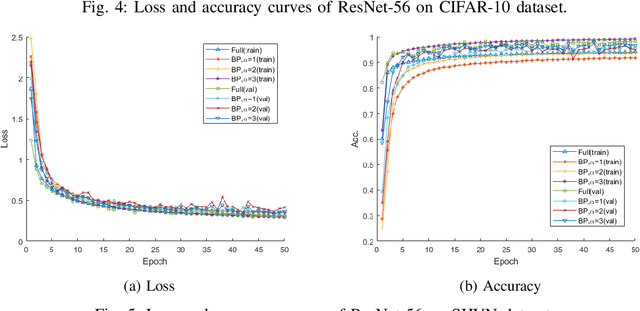
Recent research on deep neural networks (DNNs) has primarily focused on improving the model accuracy. Given a proper deep learning framework, it is generally possible to increase the depth or layer width to achieve a higher level of accuracy. However, the huge number of model parameters imposes more computational and memory usage overhead and leads to the parameter redundancy. In this paper, we address the parameter redundancy problem in DNNs by replacing conventional full projections with bilinear projections. For a fully-connected layer with $D$ input nodes and $D$ output nodes, applying bilinear projection can reduce the model space complexity from $\mathcal{O}(D^2)$ to $\mathcal{O}(2D)$, achieving a deep model with a sub-linear layer size. However, structured projection has a lower freedom of degree compared to the full projection, causing the under-fitting problem. So we simply scale up the mapping size by increasing the number of output channels, which can keep and even boosts the model accuracy. This makes it very parameter-efficient and handy to deploy such deep models on mobile systems with memory limitations. Experiments on four benchmark datasets show that applying the proposed bilinear projection to deep neural networks can achieve even higher accuracies than conventional full DNNs, while significantly reduces the model size.