 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHorizontal and Vertical Attention in Transformers
Paper and Code
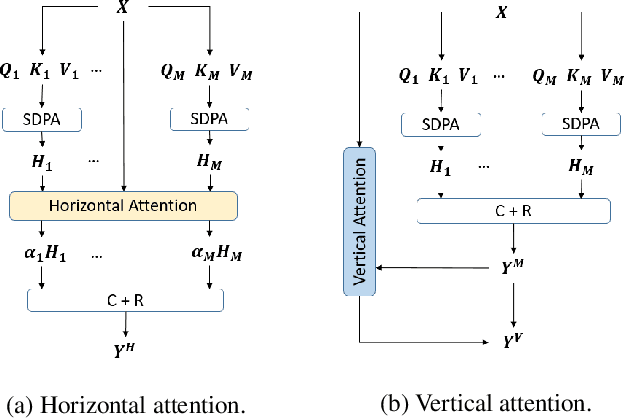

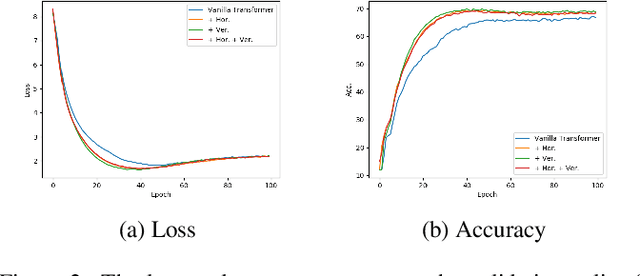
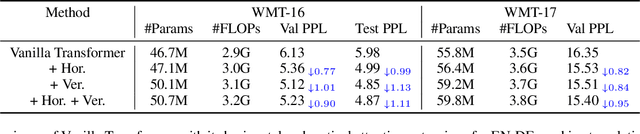
Transformers are built upon multi-head scaled dot-product attention and positional encoding, which aim to learn the feature representations and token dependencies. In this work, we focus on enhancing the distinctive representation by learning to augment the feature maps with the self-attention mechanism in Transformers. Specifically, we propose the horizontal attention to re-weight the multi-head output of the scaled dot-product attention before dimensionality reduction, and propose the vertical attention to adaptively re-calibrate channel-wise feature responses by explicitly modelling inter-dependencies among different channels. We demonstrate the Transformer models equipped with the two attentions have a high generalization capability across different supervised learning tasks, with a very minor additional computational cost overhead. The proposed horizontal and vertical attentions are highly modular, which can be inserted into various Transformer models to further improve the performance. Our code is available in the supplementary material.