 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-attention on Multi-Shifted Windows for Scene Segmentation
Paper and Code

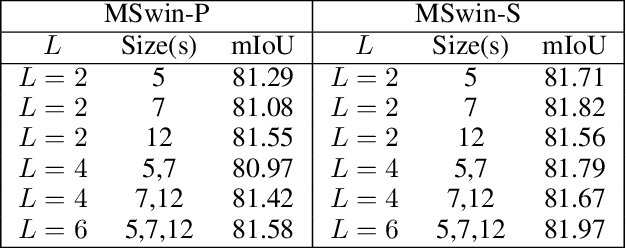
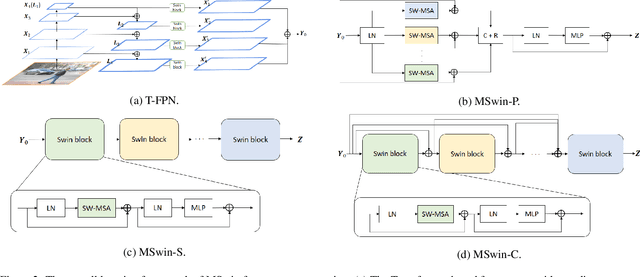
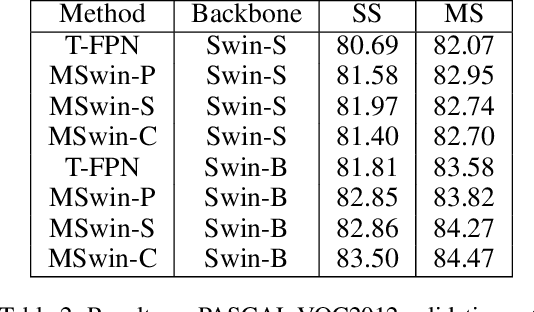
Scene segmentation in images is a fundamental yet challenging problem in visual content understanding, which is to learn a model to assign every image pixel to a categorical label. One of the challenges for this learning task is to consider the spatial and semantic relationships to obtain descriptive feature representations, so learning the feature maps from multiple scales is a common practice in scene segmentation. In this paper, we explore the effective use of self-attention within multi-scale image windows to learn descriptive visual features, then propose three different strategies to aggregate these feature maps to decode the feature representation for dense prediction. Our design is based on the recently proposed Swin Transformer models, which totally discards convolution operations. With the simple yet effective multi-scale feature learning and aggregation, our models achieve very promising performance on four public scene segmentation datasets, PASCAL VOC2012, COCO-Stuff 10K, ADE20K and Cityscapes.