 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDJCM: A Deep Joint Cascade Model for Singing Voice Separation and Vocal Pitch Estimation
Paper and Code
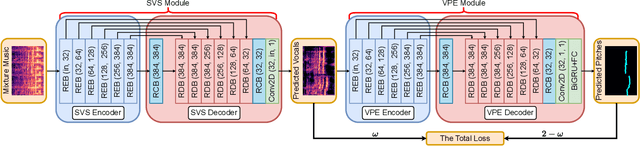



Singing voice separation and vocal pitch estimation are pivotal tasks in music information retrieval. Existing methods for simultaneous extraction of clean vocals and vocal pitches can be classified into two categories: pipeline methods and naive joint learning methods. However, the efficacy of these methods is limited by the following problems: On the one hand, pipeline methods train models for each task independently, resulting a mismatch between the data distributions at the training and testing time. On the other hand, naive joint learning methods simply add the losses of both tasks, possibly leading to a misalignment between the distinct objectives of each task. To solve these problems, we propose a Deep Joint Cascade Model (DJCM) for singing voice separation and vocal pitch estimation. DJCM employs a novel joint cascade model structure to concurrently train both tasks. Moreover, task-specific weights are used to align different objectives of both tasks. Experimental results show that DJCM achieves state-of-the-art performance on both tasks, with great improvements of 0.45 in terms of Signal-to-Distortion Ratio (SDR) for singing voice separation and 2.86% in terms of Overall Accuracy (OA) for vocal pitch estimation. Furthermore, extensive ablation studies validate the effectiveness of each design of our proposed model. The code of DJCM is available at https://github.com/Dream-High/DJCM .