 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSufficient Conditions for Unique Optimizer of Two-Dimensional Atomic Norm Minimization Under Multiple Frequencies
May 04, 2026Atomic norm minimization (ANM) has been extensively applied for gridless angle estimation. However, with the increase of the number of antennas and the communication frequencies in massive MIMO systems, the accompanying beam squint effect significantly degrades angle estimation accuracy. Existing solutions either address this issue only in the one-dimensional (1D) SIMO case, or decouple the two-dimensional (2D) angle estimation into two separate 1D problems, which fails to achieve the optimal solution. In this paper, we employ the multi-frequency model to characterize the beam squint effect in MIMO channels and propose a multi-frequency version of the ANM objective for corresponding 2D angle estimation. To efficiently retrieve the angle parameters, we prove the existence of the equivalent semi-definite program formulation of the ANM objective and develop an algorithm based on the alternating direction method of multipliers for its solutions. Moreover, we derive the certification conditions of this objective to guarantee the existence of a unique optimal solution.
Unifying Block-wise PTQ and Distillation-based QAT for Progressive Quantization toward 2-bit Instruction-Tuned LLMs
Jun 10, 2025As the rapid scaling of large language models (LLMs) poses significant challenges for deployment on resource-constrained devices, there is growing interest in extremely low-bit quantization, such as 2-bit. Although prior works have shown that 2-bit large models are pareto-optimal over their 4-bit smaller counterparts in both accuracy and latency, these advancements have been limited to pre-trained LLMs and have not yet been extended to instruction-tuned models. To bridge this gap, we propose Unified Progressive Quantization (UPQ)$-$a novel progressive quantization framework (FP16$\rightarrow$INT4$\rightarrow$INT2) that unifies block-wise post-training quantization (PTQ) with distillation-based quantization-aware training (Distill-QAT) for INT2 instruction-tuned LLM quantization. UPQ first quantizes FP16 instruction-tuned models to INT4 using block-wise PTQ to significantly reduce the quantization error introduced by subsequent INT2 quantization. Next, UPQ applies Distill-QAT to enable INT2 instruction-tuned LLMs to generate responses consistent with their original FP16 counterparts by minimizing the generalized Jensen-Shannon divergence (JSD) between the two. To the best of our knowledge, we are the first to demonstrate that UPQ can quantize open-source instruction-tuned LLMs to INT2 without relying on proprietary post-training data, while achieving state-of-the-art performances on MMLU and IFEval$-$two of the most representative benchmarks for evaluating instruction-tuned LLMs.
Analog Foundation Models
May 14, 2025Analog in-memory computing (AIMC) is a promising compute paradigm to improve speed and power efficiency of neural network inference beyond the limits of conventional von Neumann-based architectures. However, AIMC introduces fundamental challenges such as noisy computations and strict constraints on input and output quantization. Because of these constraints and imprecisions, off-the-shelf LLMs are not able to achieve 4-bit-level performance when deployed on AIMC-based hardware. While researchers previously investigated recovering this accuracy gap on small, mostly vision-based models, a generic method applicable to LLMs pre-trained on trillions of tokens does not yet exist. In this work, we introduce a general and scalable method to robustly adapt LLMs for execution on noisy, low-precision analog hardware. Our approach enables state-of-the-art models $\unicode{x2013}$ including Phi-3-mini-4k-instruct and Llama-3.2-1B-Instruct $\unicode{x2013}$ to retain performance comparable to 4-bit weight, 8-bit activation baselines, despite the presence of analog noise and quantization constraints. Additionally, we show that as a byproduct of our training methodology, analog foundation models can be quantized for inference on low-precision digital hardware. Finally, we show that our models also benefit from test-time compute scaling, showing better scaling behavior than models trained with 4-bit weight and 8-bit static input quantization. Our work bridges the gap between high-capacity LLMs and efficient analog hardware, offering a path toward energy-efficient foundation models. Code is available at https://github.com/IBM/analog-foundation-models .
FedX: Adaptive Model Decomposition and Quantization for IoT Federated Learning
Apr 19, 2025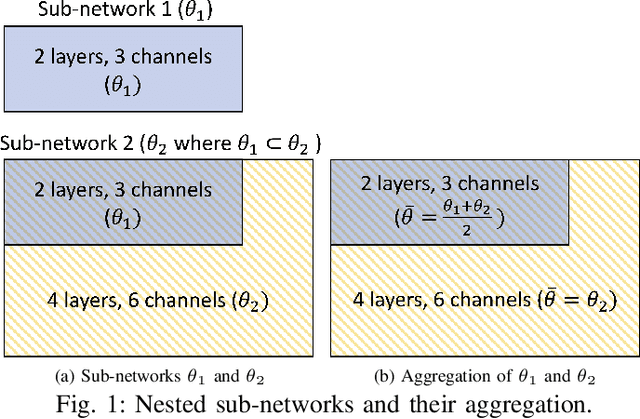
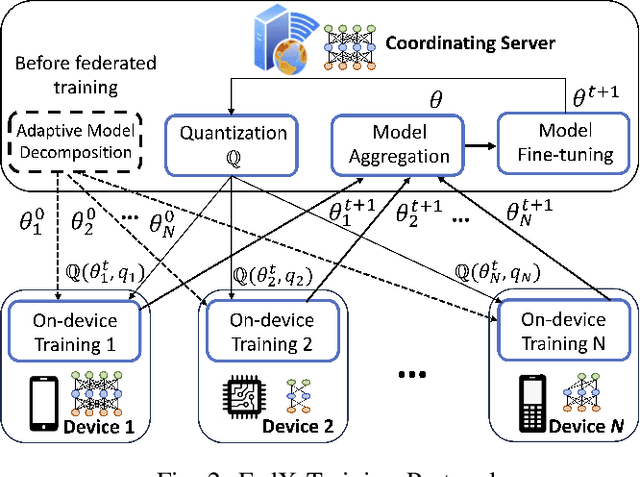
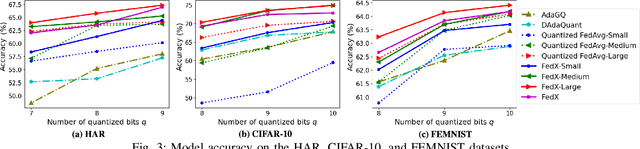
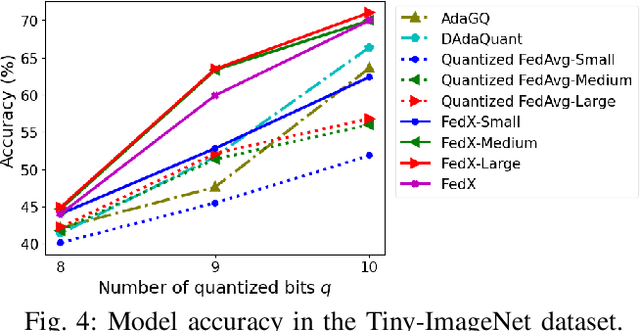
Federated Learning (FL) allows collaborative training among multiple devices without data sharing, thus enabling privacy-sensitive applications on mobile or Internet of Things (IoT) devices, such as mobile health and asset tracking. However, designing an FL system with good model utility that works with low computation/communication overhead on heterogeneous, resource-constrained mobile/IoT devices is challenging. To address this problem, this paper proposes FedX, a novel adaptive model decomposition and quantization FL system for IoT. To balance utility with resource constraints on IoT devices, FedX decomposes a global FL model into different sub-networks with adaptive numbers of quantized bits for different devices. The key idea is that a device with fewer resources receives a smaller sub-network for lower overhead but utilizes a larger number of quantized bits for higher model utility, and vice versa. The quantization operations in FedX are done at the server to reduce the computational load on devices. FedX iteratively minimizes the losses in the devices' local data and in the server's public data using quantized sub-networks under a regularization term, and thus it maximizes the benefits of combining FL with model quantization through knowledge sharing among the server and devices in a cost-effective training process. Extensive experiments show that FedX significantly improves quantization times by up to 8.43X, on-device computation time by 1.5X, and total end-to-end training time by 1.36X, compared with baseline FL systems. We guarantee the global model convergence theoretically and validate local model convergence empirically, highlighting FedX's optimization efficiency.
Sparsity-Based Channel Estimation Exploiting Deep Unrolling for Downlink Massive MIMO
Sep 24, 2023



Massive multiple-input multiple-output (MIMO) enjoys great advantage in 5G wireless communication systems owing to its spectrum and energy efficiency. However, hundreds of antennas require large volumes of pilot overhead to guarantee reliable channel estimation in FDD massive MIMO system. Compressive sensing (CS) has been applied for channel estimation by exploiting the inherent sparse structure of massive MIMO channel but suffer from high complexity. To overcome this challenge, this paper develops a hybrid channel estimation scheme by integrating the model-driven CS and data-driven deep unrolling technique. The proposed scheme consists of a coarse estimation part and a fine correction part to respectively exploit the inter- and intraframe sparsities of channels to greatly reduce the pilot overhead. Theoretical result is provided to indicate the convergence of the fine correction and coarse estimation net. Simulation results are provided to verify that our scheme can estimate MIMO channels with low pilot overhead while guaranteeing estimation accuracy with relatively low complexity.
Zone-based Federated Learning for Mobile Sensing Data
Mar 10, 2023

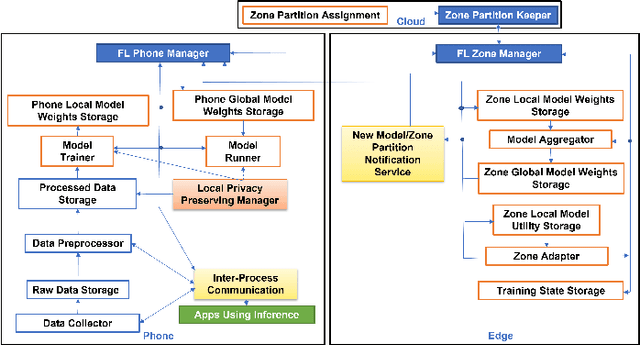

Mobile apps, such as mHealth and wellness applications, can benefit from deep learning (DL) models trained with mobile sensing data collected by smart phones or wearable devices. However, currently there is no mobile sensing DL system that simultaneously achieves good model accuracy while adapting to user mobility behavior, scales well as the number of users increases, and protects user data privacy. We propose Zone-based Federated Learning (ZoneFL) to address these requirements. ZoneFL divides the physical space into geographical zones mapped to a mobile-edge-cloud system architecture for good model accuracy and scalability. Each zone has a federated training model, called a zone model, which adapts well to data and behaviors of users in that zone. Benefiting from the FL design, the user data privacy is protected during the ZoneFL training. We propose two novel zone-based federated training algorithms to optimize zone models to user mobility behavior: Zone Merge and Split (ZMS) and Zone Gradient Diffusion (ZGD). ZMS optimizes zone models by adapting the zone geographical partitions through merging of neighboring zones or splitting of large zones into smaller ones. Different from ZMS, ZGD maintains fixed zones and optimizes a zone model by incorporating the gradients derived from neighboring zones' data. ZGD uses a self-attention mechanism to dynamically control the impact of one zone on its neighbors. Extensive analysis and experimental results demonstrate that ZoneFL significantly outperforms traditional FL in two models for heart rate prediction and human activity recognition. In addition, we developed a ZoneFL system using Android phones and AWS cloud. The system was used in a heart rate prediction field study with 63 users for 4 months, and we demonstrated the feasibility of ZoneFL in real-life.
A Surrogate-Assisted Highly Cooperative Coevolutionary Algorithm for Hyperparameter Optimization in Deep Convolutional Neural Network
Feb 25, 2023
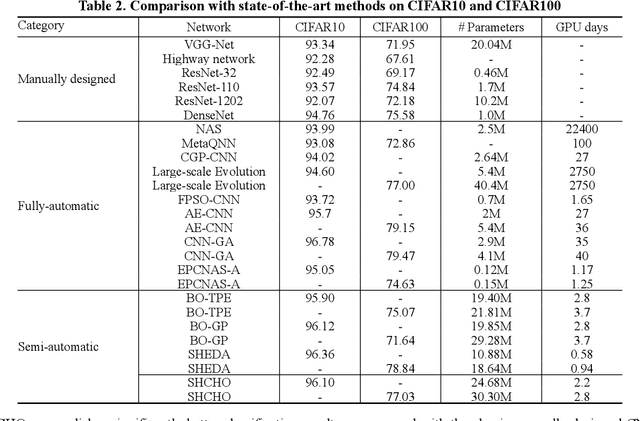

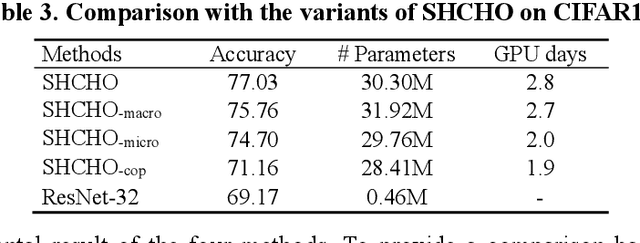
Convolutional neural networks (CNNs) have gained remarkable success in recent years. However, their performance highly relies on the architecture hyperparameters, and finding proper hyperparameters for a deep CNN is a challenging optimization problem owing to its high-dimensional and computationally expensive characteristics. Given these difficulties, this study proposes a surrogate-assisted highly cooperative hyperparameter optimization (SHCHO) algorithm for chain-styled CNNs. To narrow the large search space, SHCHO first decomposes the whole CNN into several overlapping sub-CNNs in accordance with the overlapping hyperparameter interaction structure and then cooperatively optimizes these hyperparameter subsets. Two cooperation mechanisms are designed during this process. One coordinates all the sub-CNNs to reproduce the information flow in the whole CNN and achieve macro cooperation among them, and the other tackles the overlapping components by simultaneously considering the involved two sub-CNNs and facilitates micro cooperation between them. As a result, a proper hyperparameter configuration can be effectively located for the whole CNN. Besides, SHCHO also employs the well-performing surrogate technique to assist in the hyperparameter optimization of each sub-CNN, thereby greatly reducing the expensive computational cost. Extensive experimental results on two widely-used image classification datasets indicate that SHCHO can significantly improve the performance of CNNs.
Hardware-aware training for large-scale and diverse deep learning inference workloads using in-memory computing-based accelerators
Feb 16, 2023Analog in-memory computing (AIMC) -- a promising approach for energy-efficient acceleration of deep learning workloads -- computes matrix-vector multiplications (MVMs) but only approximately, due to nonidealities that often are non-deterministic or nonlinear. This can adversely impact the achievable deep neural network (DNN) inference accuracy as compared to a conventional floating point (FP) implementation. While retraining has previously been suggested to improve robustness, prior work has explored only a few DNN topologies, using disparate and overly simplified AIMC hardware models. Here, we use hardware-aware (HWA) training to systematically examine the accuracy of AIMC for multiple common artificial intelligence (AI) workloads across multiple DNN topologies, and investigate sensitivity and robustness to a broad set of nonidealities. By introducing a new and highly realistic AIMC crossbar-model, we improve significantly on earlier retraining approaches. We show that many large-scale DNNs of various topologies, including convolutional neural networks (CNNs), recurrent neural networks (RNNs), and transformers, can in fact be successfully retrained to show iso-accuracy on AIMC. Our results further suggest that AIMC nonidealities that add noise to the inputs or outputs, not the weights, have the largest impact on DNN accuracy, and that RNNs are particularly robust to all nonidealities.
Downlink Massive MIMO Channel Estimation via Deep Unrolling : Sparsity Exploitations in Angular Domain
Oct 31, 2022In frequency division duplex (FDD) massive MIMO systems, reliable downlink channel estimation is essential for the subsequent data transmission but is realized at the cost of massive pilot overhead due to hundreds of antennas at base station (BS). In order to reduce the pilot overhead without compromising the estimation, compressive sensing (CS) based methods have been widely applied for channel estimation by exploiting the inherent sparse structure of massive MIMO channel in angular domain. However, they still suffer from high complexity during optimization process and the requirement of prior knowledge on sparsity information. To overcome these challenges, this paper develops a novel hybrid channel estimation framework by integrating the model-driven CS and data-driven deep unrolling techniques. The proposed framework is composed of a coarse estimation part and a fine correction part, which is implemented in a two-stage manner to exploit both inter- and intra-frame sparsities of channels in angular domain. Then, two estimation schemes are designed depending on whether priori sparsity information is required, where the second scheme designs a new thresholding function to eliminate such requirement. Numerical results are provided to verify that our schemes can achieve high accuracy with low pilot overhead and low complexity.
FLSys: Toward an Open Ecosystem for Federated Learning Mobile Apps
Nov 21, 2021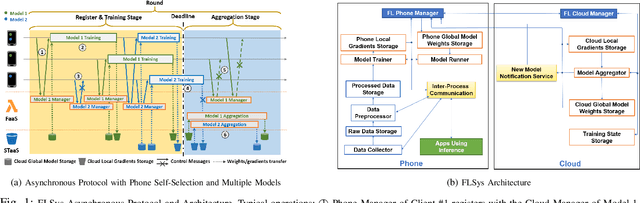
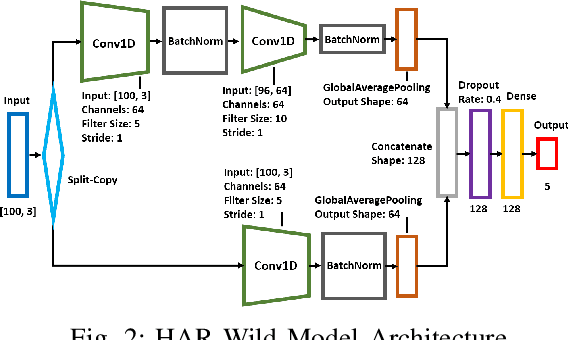
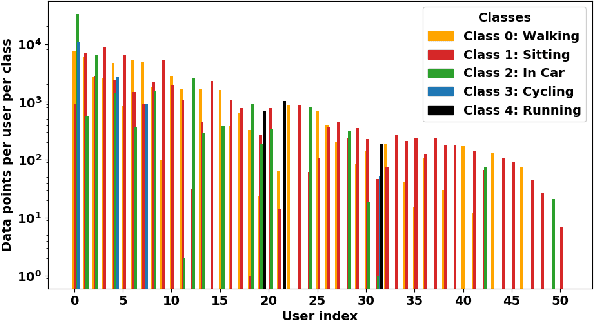
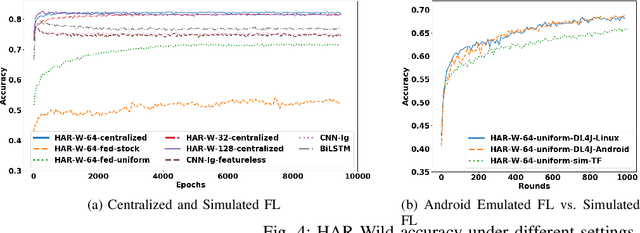
This paper presents the design, implementation, and evaluation of FLSys, a mobile-cloud federated learning (FL) system that supports deep learning models for mobile apps. FLSys is a key component toward creating an open ecosystem of FL models and apps that use these models. FLSys is designed to work with mobile sensing data collected on smart phones, balance model performance with resource consumption on the phones, tolerate phone communication failures, and achieve scalability in the cloud. In FLSys, different DL models with different FL aggregation methods in the cloud can be trained and accessed concurrently by different apps. Furthermore, FLSys provides a common API for third-party app developers to train FL models. FLSys is implemented in Android and AWS cloud. We co-designed FLSys with a human activity recognition (HAR) in the wild FL model. HAR sensing data was collected in two areas from the phones of 100+ college students during a five-month period. We implemented HAR-Wild, a CNN model tailored to mobile devices, with a data augmentation mechanism to mitigate the problem of non-Independent and Identically Distributed (non-IID) data that affects FL model training in the wild. A sentiment analysis (SA) model is used to demonstrate how FLSys effectively supports concurrent models, and it uses a dataset with 46,000+ tweets from 436 users. We conducted extensive experiments on Android phones and emulators showing that FLSys achieves good model utility and practical system performance.