 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Performance of Analog Training for Transfer Learning
May 16, 2025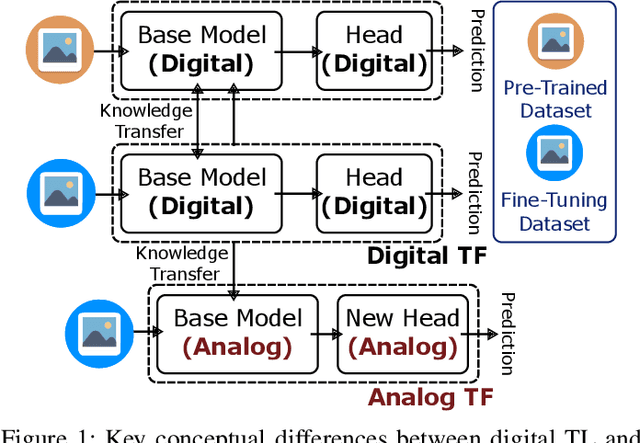
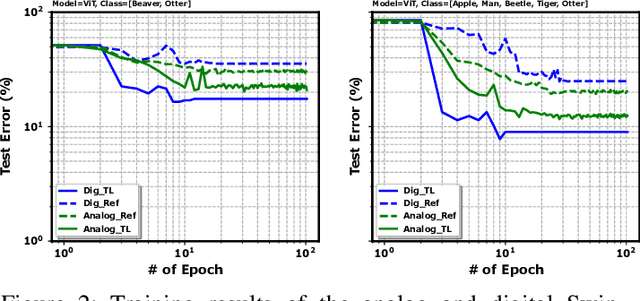
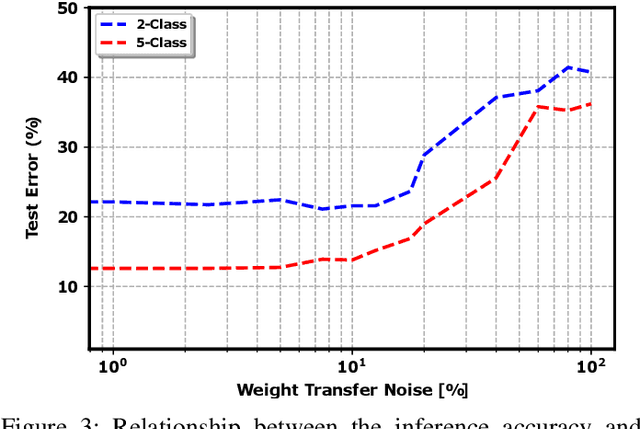
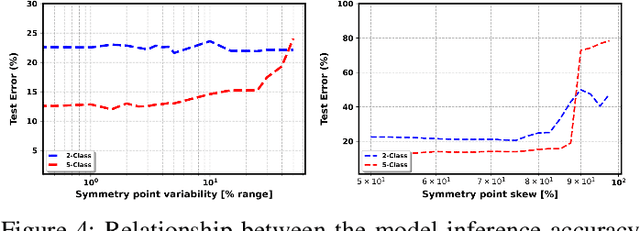
Analog in-memory computing is a next-generation computing paradigm that promises fast, parallel, and energy-efficient deep learning training and transfer learning (TL). However, achieving this promise has remained elusive due to a lack of suitable training algorithms. Analog memory devices exhibit asymmetric and non-linear switching behavior in addition to device-to-device variation, meaning that most, if not all, of the current off-the-shelf training algorithms cannot achieve good training outcomes. Also, recently introduced algorithms have enjoyed limited attention, as they require bi-directionally switching devices of unrealistically high symmetry and precision and are highly sensitive. A new algorithm chopped TTv2 (c-TTv2), has been introduced, which leverages the chopped technique to address many of the challenges mentioned above. In this paper, we assess the performance of the c-TTv2 algorithm for analog TL using a Swin-ViT model on a subset of the CIFAR100 dataset. We also investigate the robustness of our algorithm to changes in some device specifications, including weight transfer noise, symmetry point skew, and symmetry point variability
Analog Foundation Models
May 14, 2025Analog in-memory computing (AIMC) is a promising compute paradigm to improve speed and power efficiency of neural network inference beyond the limits of conventional von Neumann-based architectures. However, AIMC introduces fundamental challenges such as noisy computations and strict constraints on input and output quantization. Because of these constraints and imprecisions, off-the-shelf LLMs are not able to achieve 4-bit-level performance when deployed on AIMC-based hardware. While researchers previously investigated recovering this accuracy gap on small, mostly vision-based models, a generic method applicable to LLMs pre-trained on trillions of tokens does not yet exist. In this work, we introduce a general and scalable method to robustly adapt LLMs for execution on noisy, low-precision analog hardware. Our approach enables state-of-the-art models $\unicode{x2013}$ including Phi-3-mini-4k-instruct and Llama-3.2-1B-Instruct $\unicode{x2013}$ to retain performance comparable to 4-bit weight, 8-bit activation baselines, despite the presence of analog noise and quantization constraints. Additionally, we show that as a byproduct of our training methodology, analog foundation models can be quantized for inference on low-precision digital hardware. Finally, we show that our models also benefit from test-time compute scaling, showing better scaling behavior than models trained with 4-bit weight and 8-bit static input quantization. Our work bridges the gap between high-capacity LLMs and efficient analog hardware, offering a path toward energy-efficient foundation models. Code is available at https://github.com/IBM/analog-foundation-models .
Analog In-memory Training on General Non-ideal Resistive Elements: The Impact of Response Functions
Feb 10, 2025



As the economic and environmental costs of training and deploying large vision or language models increase dramatically, analog in-memory computing (AIMC) emerges as a promising energy-efficient solution. However, the training perspective, especially its training dynamic, is underexplored. In AIMC hardware, the trainable weights are represented by the conductance of resistive elements and updated using consecutive electrical pulses. Among all the physical properties of resistive elements, the response to the pulses directly affects the training dynamics. This paper first provides a theoretical foundation for gradient-based training on AIMC hardware and studies the impact of response functions. We demonstrate that noisy update and asymmetric response functions negatively impact Analog SGD by imposing an implicit penalty term on the objective. To overcome the issue, Tiki-Taka, a residual learning algorithm, converges exactly to a critical point by optimizing a main array and a residual array bilevelly. The conclusion is supported by simulations validating our theoretical insights.
Using the IBM Analog In-Memory Hardware Acceleration Kit for Neural Network Training and Inference
Jul 18, 2023

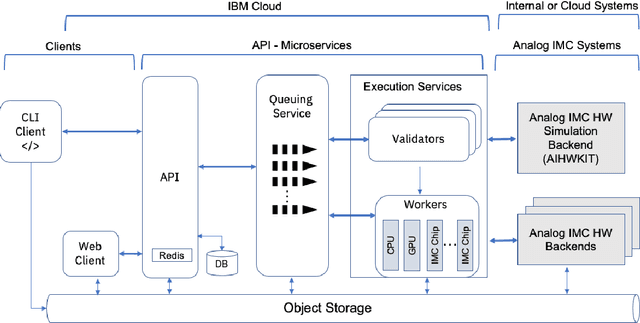

Analog In-Memory Computing (AIMC) is a promising approach to reduce the latency and energy consumption of Deep Neural Network (DNN) inference and training. However, the noisy and non-linear device characteristics, and the non-ideal peripheral circuitry in AIMC chips, require adapting DNNs to be deployed on such hardware to achieve equivalent accuracy to digital computing. In this tutorial, we provide a deep dive into how such adaptations can be achieved and evaluated using the recently released IBM Analog Hardware Acceleration Kit (AIHWKit), freely available at https://github.com/IBM/aihwkit. The AIHWKit is a Python library that simulates inference and training of DNNs using AIMC. We present an in-depth description of the AIHWKit design, functionality, and best practices to properly perform inference and training. We also present an overview of the Analog AI Cloud Composer, that provides the benefits of using the AIHWKit simulation platform in a fully managed cloud setting. Finally, we show examples on how users can expand and customize AIHWKit for their own needs. This tutorial is accompanied by comprehensive Jupyter Notebook code examples that can be run using AIHWKit, which can be downloaded from https://github.com/IBM/aihwkit/tree/master/notebooks/tutorial.
Effect of Batch Normalization on Noise Resistant Property of Deep Learning Models
May 15, 2022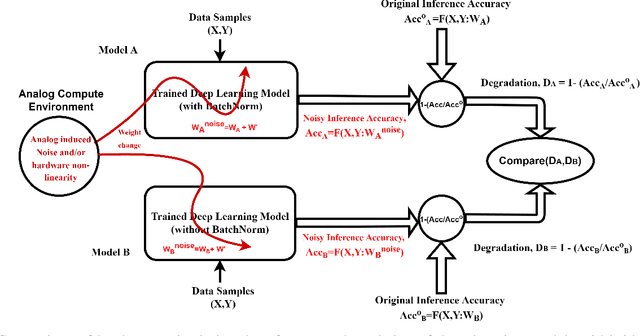
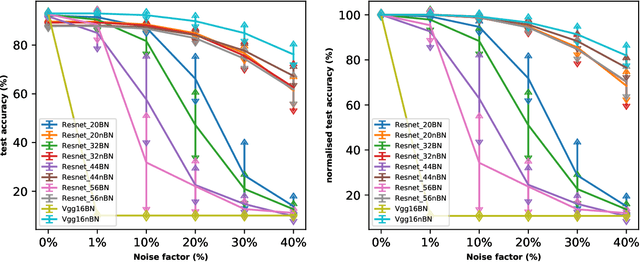
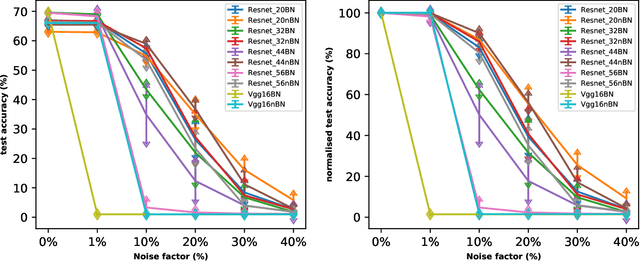
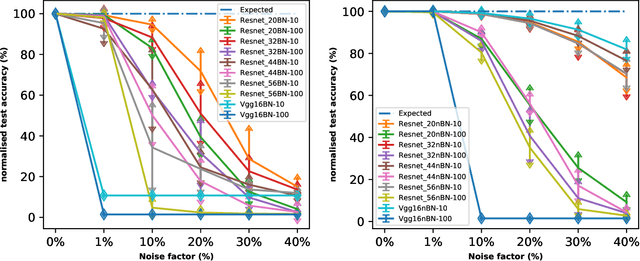
The fast execution speed and energy efficiency of analog hardware has made them a strong contender for deployment of deep learning model at the edge. However, there are concerns about the presence of analog noise which causes changes to the weight of the models, leading to performance degradation of deep learning model, despite their inherent noise resistant characteristics. The effect of the popular batch normalization layer on the noise resistant ability of deep learning model is investigated in this work. This systematic study has been carried out by first training different models with and without batch normalization layer on CIFAR10 and CIFAR100 dataset. The weights of the resulting models are then injected with analog noise and the performance of the models on the test dataset is obtained and compared. The results show that the presence of batch normalization layer negatively impacts noise resistant property of deep learning model and the impact grows with the increase of the number of batch normalization layers.
Impact of Learning Rate on Noise Resistant Property of Deep Learning Models
May 08, 2022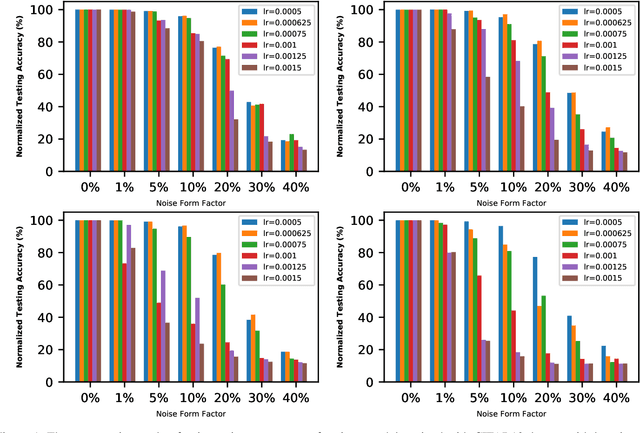
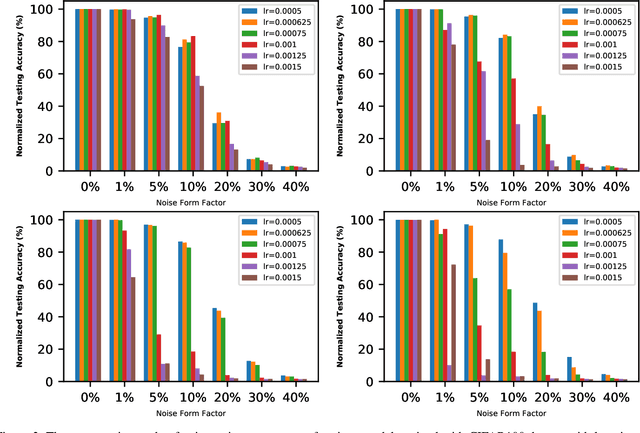
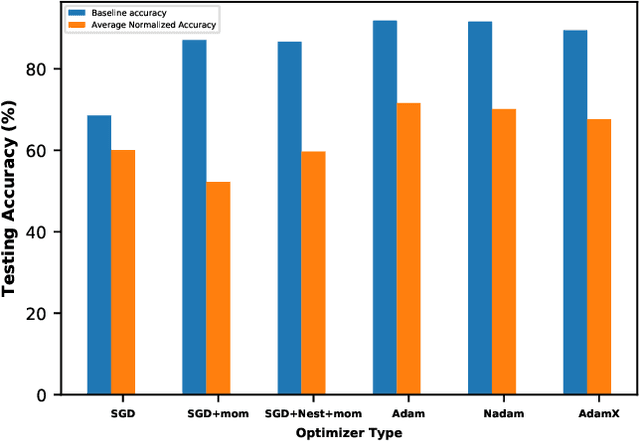
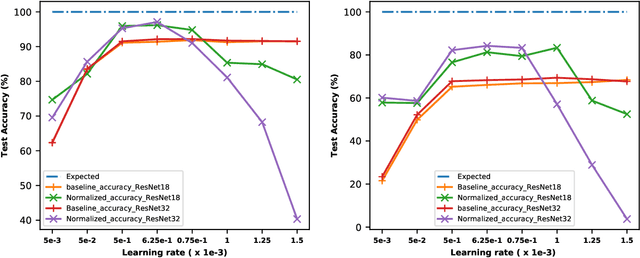
The interest in analog computation has grown tremendously in recent years due to its fast computation speed and excellent energy efficiency, which is very important for edge and IoT devices in the sub-watt power envelope for deep learning inferencing. However, significant performance degradation suffered by deep learning models due to the inherent noise present in the analog computation can limit their use in mission-critical applications. Hence, there is a need to understand the impact of critical model hyperparameters choice on the resulting model noise-resistant property. This need is critical as the insight obtained can be used to design deep learning models that are robust to analog noise. In this paper, the impact of the learning rate, a critical design choice, on the noise-resistant property is investigated. The study is achieved by first training deep learning models using different learning rates. Thereafter, the models are injected with analog noise and the noise-resistant property of the resulting models is examined by measuring the performance degradation due to the analog noise. The results showed there exists a sweet spot of learning rate values that achieves a good balance between model prediction performance and model noise-resistant property. Furthermore, the theoretical justification of the observed phenomenon is provided.
Impact of L1 Batch Normalization on Analog Noise Resistant Property of Deep Learning Models
May 07, 2022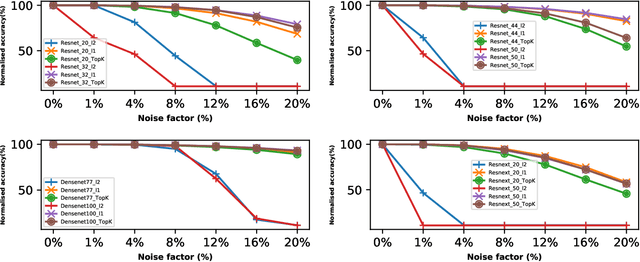
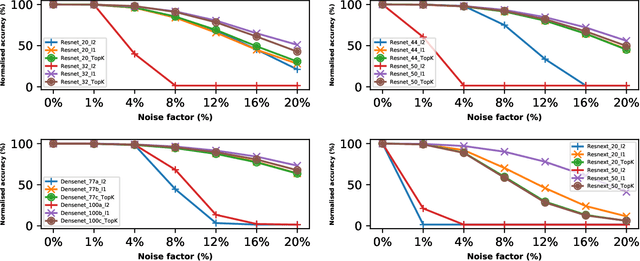

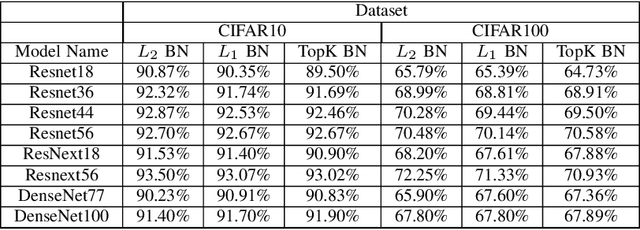
Analog hardware has become a popular choice for machine learning on resource-constrained devices recently due to its fast execution and energy efficiency. However, the inherent presence of noise in analog hardware and the negative impact of the noise on deployed deep neural network (DNN) models limit their usage. The degradation in performance due to the noise calls for the novel design of DNN models that have excellent noiseresistant property, leveraging the properties of the fundamental building block of DNN models. In this work, the use of L1 or TopK BatchNorm type, a fundamental DNN model building block, in designing DNN models with excellent noise-resistant property is proposed. Specifically, a systematic study has been carried out by training DNN models with L1/TopK BatchNorm type, and the performance is compared with DNN models with L2 BatchNorm types. The resulting model noise-resistant property is tested by injecting additive noise to the model weights and evaluating the new model inference accuracy due to the noise. The results show that L1 and TopK BatchNorm type has excellent noise-resistant property, and there is no sacrifice in performance due to the change in the BatchNorm type from L2 to L1/TopK BatchNorm type.
A Joint Energy and Latency Framework for Transfer Learning over 5G Industrial Edge Networks
Apr 19, 2021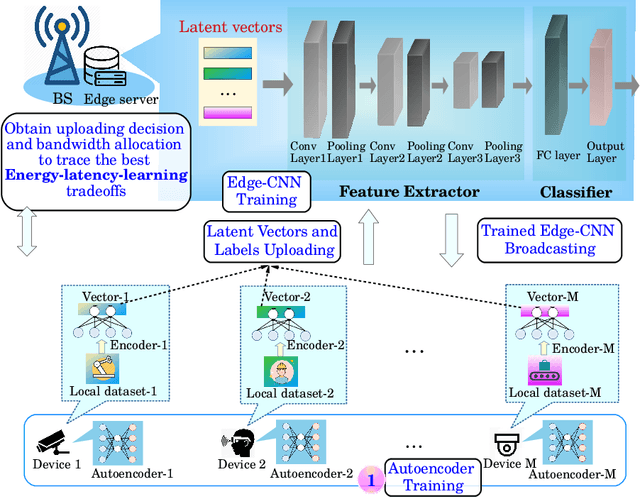
In this paper, we propose a transfer learning (TL)-enabled edge-CNN framework for 5G industrial edge networks with privacy-preserving characteristic. In particular, the edge server can use the existing image dataset to train the CNN in advance, which is further fine-tuned based on the limited datasets uploaded from the devices. With the aid of TL, the devices that are not participating in the training only need to fine-tune the trained edge-CNN model without training from scratch. Due to the energy budget of the devices and the limited communication bandwidth, a joint energy and latency problem is formulated, which is solved by decomposing the original problem into an uploading decision subproblem and a wireless bandwidth allocation subproblem. Experiments using ImageNet demonstrate that the proposed TL-enabled edge-CNN framework can achieve almost 85% prediction accuracy of the baseline by uploading only about 1% model parameters, for a compression ratio of 32 of the autoencoder.
Benchmarking Inference Performance of Deep Learning Models on Analog Devices
Dec 16, 2020
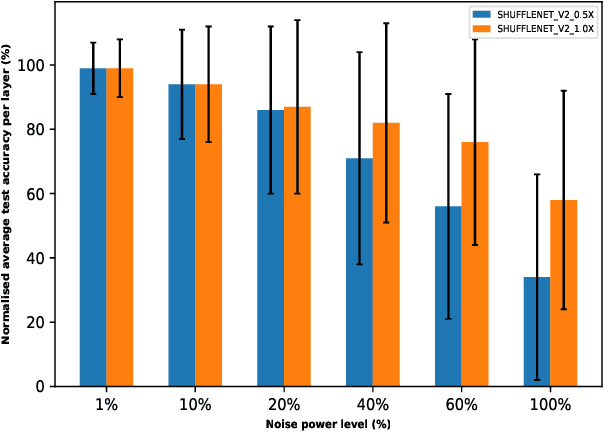
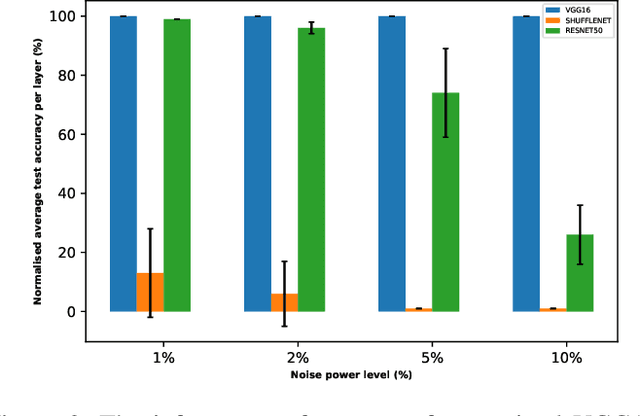
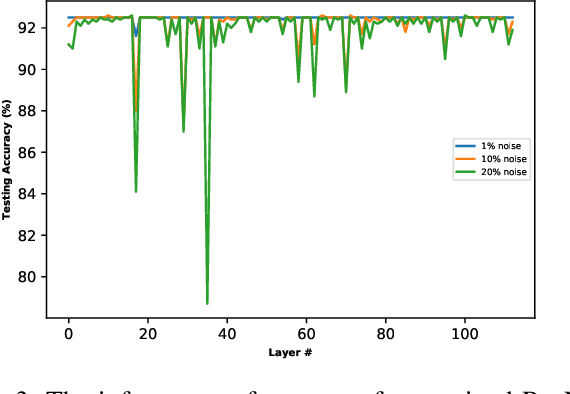
Analog hardware implemented deep learning models are promising for computation and energy constrained systems such as edge computing devices. However, the analog nature of the device and the associated many noise sources will cause changes to the value of the weights in the trained deep learning models deployed on such devices. In this study, systematic evaluation of the inference performance of trained popular deep learning models for image classification deployed on analog devices has been carried out, where additive white Gaussian noise has been added to the weights of the trained models during inference. It is observed that deeper models and models with more redundancy in design such as VGG are more robust to the noise in general. However, the performance is also affected by the design philosophy of the model, the detailed structure of the model, the exact machine learning task, as well as the datasets.
Efficient Privacy Preserving Edge Computing Framework for Image Classification
May 10, 2020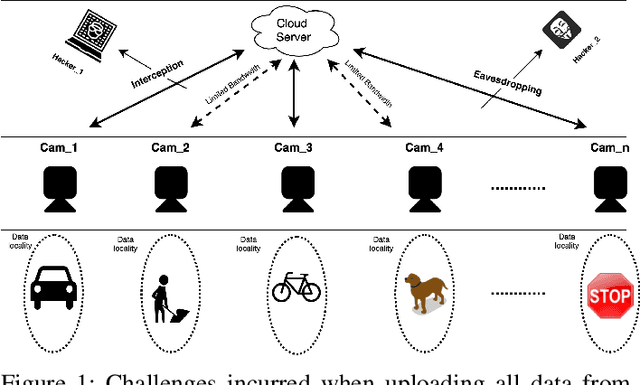
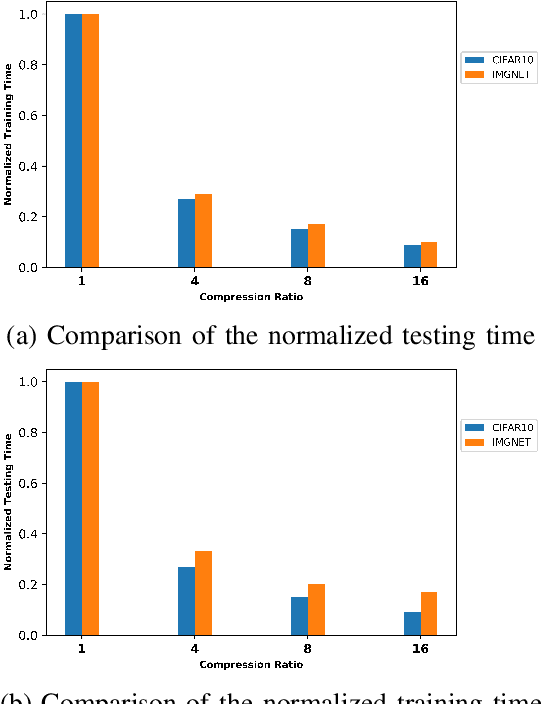
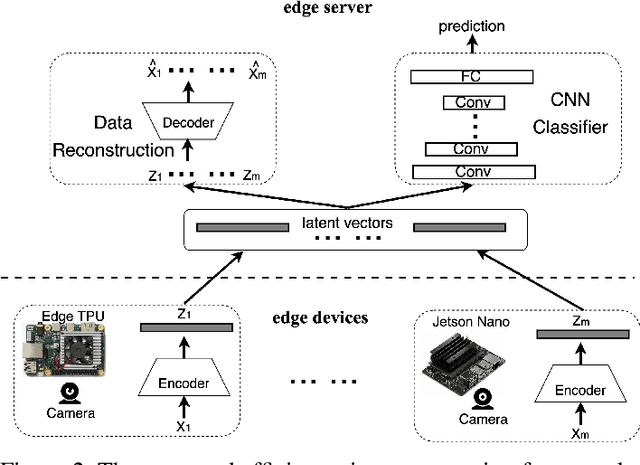
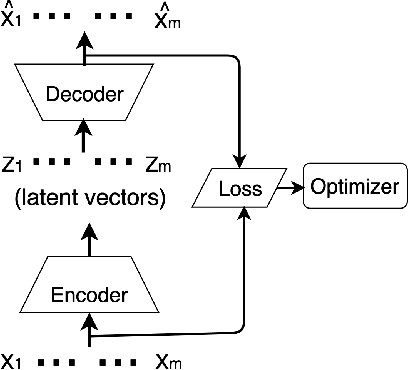
In order to extract knowledge from the large data collected by edge devices, traditional cloud based approach that requires data upload may not be feasible due to communication bandwidth limitation as well as privacy and security concerns of end users. To address these challenges, a novel privacy preserving edge computing framework is proposed in this paper for image classification. Specifically, autoencoder will be trained unsupervised at each edge device individually, then the obtained latent vectors will be transmitted to the edge server for the training of a classifier. This framework would reduce the communications overhead and protect the data of the end users. Comparing to federated learning, the training of the classifier in the proposed framework does not subject to the constraints of the edge devices, and the autoencoder can be trained independently at each edge device without any server involvement. Furthermore, the privacy of the end users' data is protected by transmitting latent vectors without additional cost of encryption. Experimental results provide insights on the image classification performance vs. various design parameters such as the data compression ratio of the autoencoder and the model complexity.