 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing the IBM Analog In-Memory Hardware Acceleration Kit for Neural Network Training and Inference
Jul 18, 2023

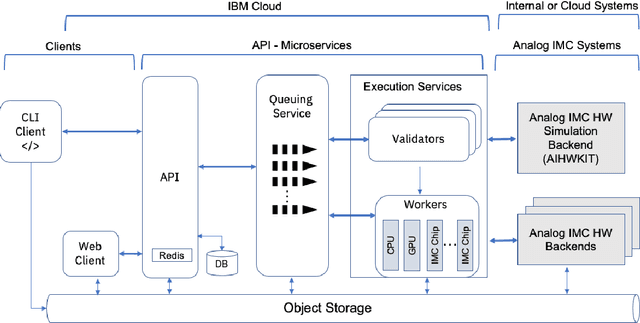

Analog In-Memory Computing (AIMC) is a promising approach to reduce the latency and energy consumption of Deep Neural Network (DNN) inference and training. However, the noisy and non-linear device characteristics, and the non-ideal peripheral circuitry in AIMC chips, require adapting DNNs to be deployed on such hardware to achieve equivalent accuracy to digital computing. In this tutorial, we provide a deep dive into how such adaptations can be achieved and evaluated using the recently released IBM Analog Hardware Acceleration Kit (AIHWKit), freely available at https://github.com/IBM/aihwkit. The AIHWKit is a Python library that simulates inference and training of DNNs using AIMC. We present an in-depth description of the AIHWKit design, functionality, and best practices to properly perform inference and training. We also present an overview of the Analog AI Cloud Composer, that provides the benefits of using the AIHWKit simulation platform in a fully managed cloud setting. Finally, we show examples on how users can expand and customize AIHWKit for their own needs. This tutorial is accompanied by comprehensive Jupyter Notebook code examples that can be run using AIHWKit, which can be downloaded from https://github.com/IBM/aihwkit/tree/master/notebooks/tutorial.
Fast offset corrected in-memory training
Mar 08, 2023In-memory computing with resistive crossbar arrays has been suggested to accelerate deep-learning workloads in highly efficient manner. To unleash the full potential of in-memory computing, it is desirable to accelerate the training as well as inference for large deep neural networks (DNNs). In the past, specialized in-memory training algorithms have been proposed that not only accelerate the forward and backward passes, but also establish tricks to update the weight in-memory and in parallel. However, the state-of-the-art algorithm (Tiki-Taka version 2 (TTv2)) still requires near perfect offset correction and suffers from potential biases that might occur due to programming and estimation inaccuracies, as well as longer-term instabilities of the device materials. Here we propose and describe two new and improved algorithms for in-memory computing (Chopped-TTv2 (c-TTv2) and Analog Gradient Accumulation with Dynamic reference (AGAD)), that retain the same runtime complexity but correct for any remaining offsets using choppers. These algorithms greatly relax the device requirements and thus expanding the scope of possible materials potentially employed for such fast in-memory DNN training.
A flexible and fast PyTorch toolkit for simulating training and inference on analog crossbar arrays
Apr 05, 2021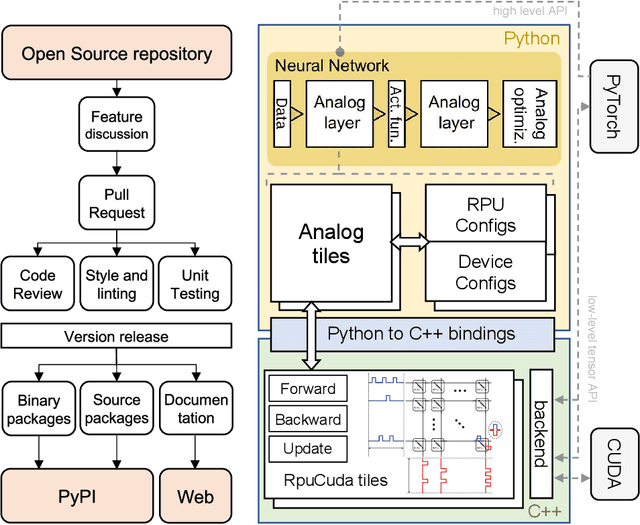

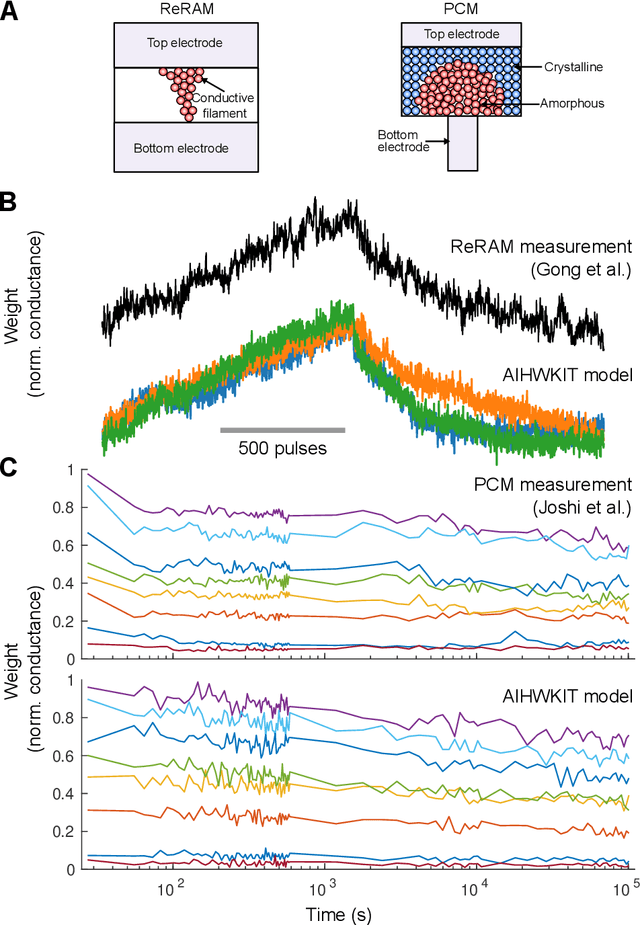

We introduce the IBM Analog Hardware Acceleration Kit, a new and first of a kind open source toolkit to simulate analog crossbar arrays in a convenient fashion from within PyTorch (freely available at https://github.com/IBM/aihwkit). The toolkit is under active development and is centered around the concept of an "analog tile" which captures the computations performed on a crossbar array. Analog tiles are building blocks that can be used to extend existing network modules with analog components and compose arbitrary artificial neural networks (ANNs) using the flexibility of the PyTorch framework. Analog tiles can be conveniently configured to emulate a plethora of different analog hardware characteristics and their non-idealities, such as device-to-device and cycle-to-cycle variations, resistive device response curves, and weight and output noise. Additionally, the toolkit makes it possible to design custom unit cell configurations and to use advanced analog optimization algorithms such as Tiki-Taka. Moreover, the backward and update behavior can be set to "ideal" to enable hardware-aware training features for chips that target inference acceleration only. To evaluate the inference accuracy of such chips over time, we provide statistical programming noise and drift models calibrated on phase-change memory hardware. Our new toolkit is fully GPU accelerated and can be used to conveniently estimate the impact of material properties and non-idealities of future analog technology on the accuracy for arbitrary ANNs.