 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Performance of Analog Training for Transfer Learning
May 16, 2025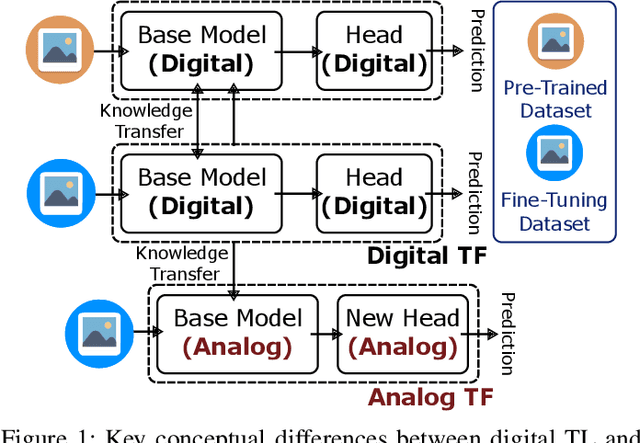
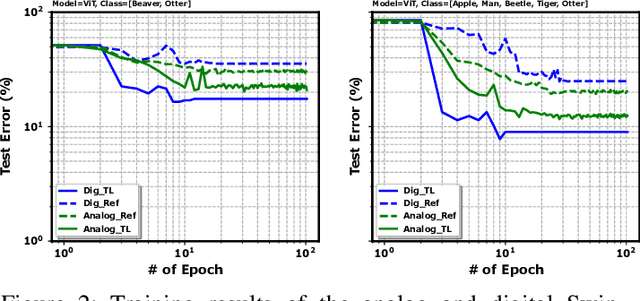
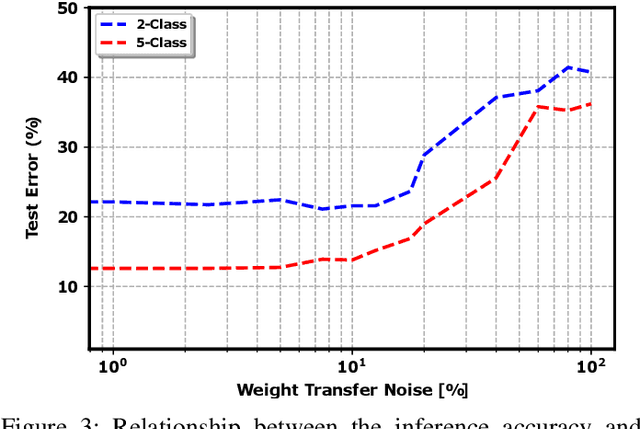
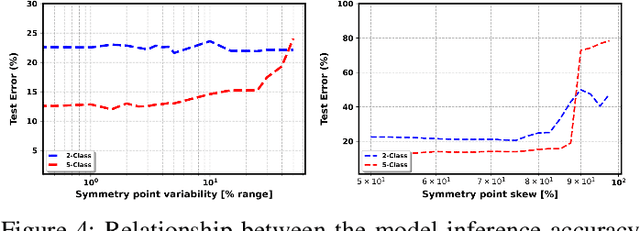
Analog in-memory computing is a next-generation computing paradigm that promises fast, parallel, and energy-efficient deep learning training and transfer learning (TL). However, achieving this promise has remained elusive due to a lack of suitable training algorithms. Analog memory devices exhibit asymmetric and non-linear switching behavior in addition to device-to-device variation, meaning that most, if not all, of the current off-the-shelf training algorithms cannot achieve good training outcomes. Also, recently introduced algorithms have enjoyed limited attention, as they require bi-directionally switching devices of unrealistically high symmetry and precision and are highly sensitive. A new algorithm chopped TTv2 (c-TTv2), has been introduced, which leverages the chopped technique to address many of the challenges mentioned above. In this paper, we assess the performance of the c-TTv2 algorithm for analog TL using a Swin-ViT model on a subset of the CIFAR100 dataset. We also investigate the robustness of our algorithm to changes in some device specifications, including weight transfer noise, symmetry point skew, and symmetry point variability
Using the IBM Analog In-Memory Hardware Acceleration Kit for Neural Network Training and Inference
Jul 18, 2023

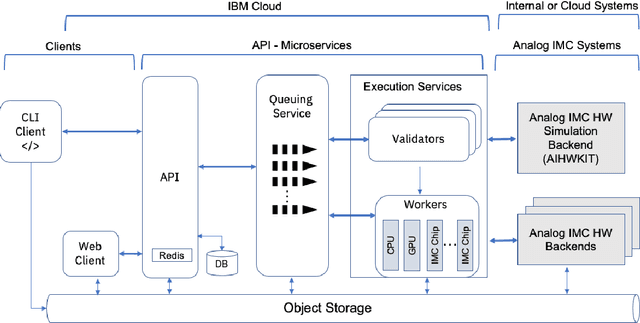

Analog In-Memory Computing (AIMC) is a promising approach to reduce the latency and energy consumption of Deep Neural Network (DNN) inference and training. However, the noisy and non-linear device characteristics, and the non-ideal peripheral circuitry in AIMC chips, require adapting DNNs to be deployed on such hardware to achieve equivalent accuracy to digital computing. In this tutorial, we provide a deep dive into how such adaptations can be achieved and evaluated using the recently released IBM Analog Hardware Acceleration Kit (AIHWKit), freely available at https://github.com/IBM/aihwkit. The AIHWKit is a Python library that simulates inference and training of DNNs using AIMC. We present an in-depth description of the AIHWKit design, functionality, and best practices to properly perform inference and training. We also present an overview of the Analog AI Cloud Composer, that provides the benefits of using the AIHWKit simulation platform in a fully managed cloud setting. Finally, we show examples on how users can expand and customize AIHWKit for their own needs. This tutorial is accompanied by comprehensive Jupyter Notebook code examples that can be run using AIHWKit, which can be downloaded from https://github.com/IBM/aihwkit/tree/master/notebooks/tutorial.
AnalogNAS: A Neural Network Design Framework for Accurate Inference with Analog In-Memory Computing
May 17, 2023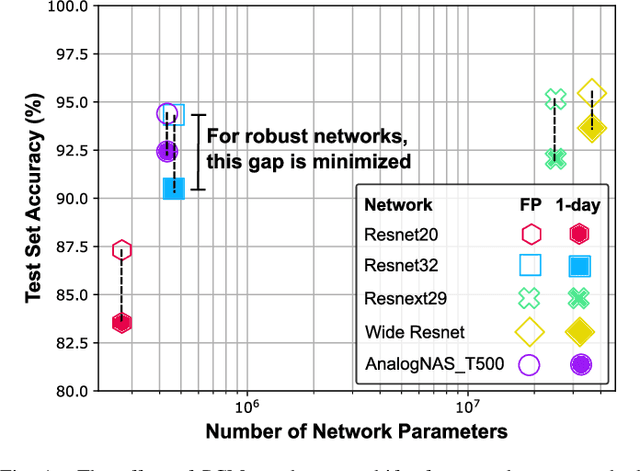
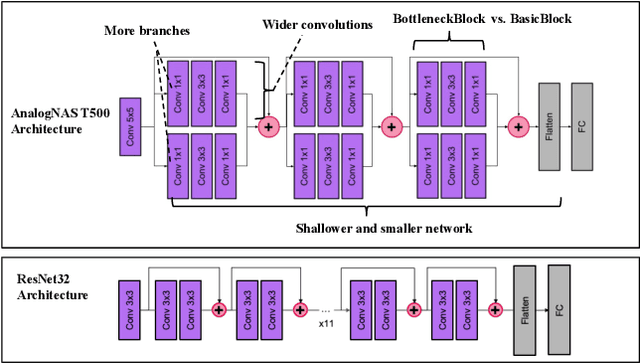
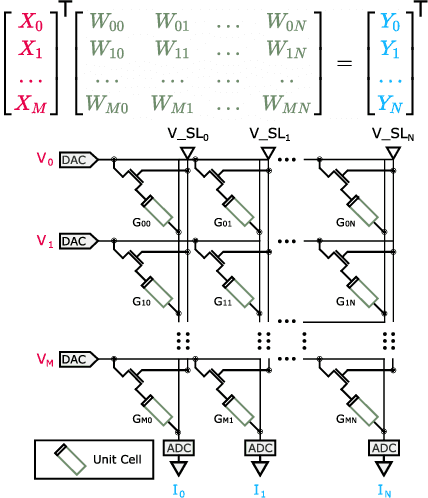
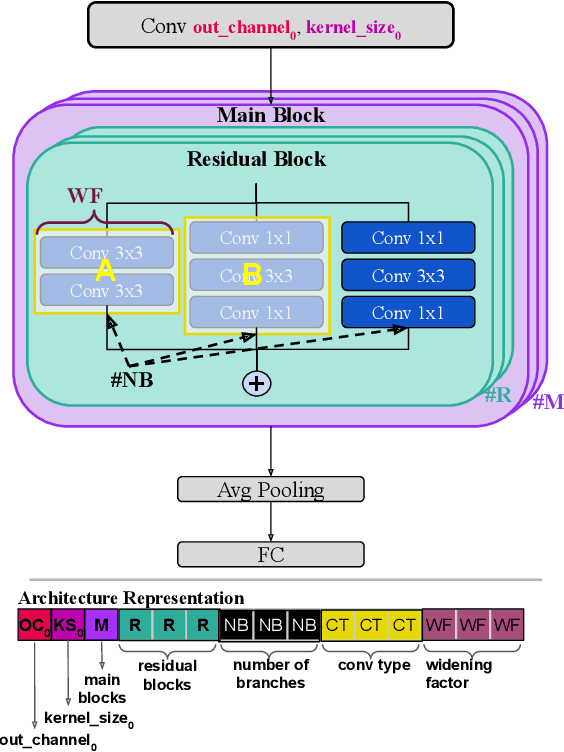
The advancement of Deep Learning (DL) is driven by efficient Deep Neural Network (DNN) design and new hardware accelerators. Current DNN design is primarily tailored for general-purpose use and deployment on commercially viable platforms. Inference at the edge requires low latency, compact and power-efficient models, and must be cost-effective. Digital processors based on typical von Neumann architectures are not conducive to edge AI given the large amounts of required data movement in and out of memory. Conversely, analog/mixed signal in-memory computing hardware accelerators can easily transcend the memory wall of von Neuman architectures when accelerating inference workloads. They offer increased area and power efficiency, which are paramount in edge resource-constrained environments. In this paper, we propose AnalogNAS, a framework for automated DNN design targeting deployment on analog In-Memory Computing (IMC) inference accelerators. We conduct extensive hardware simulations to demonstrate the performance of AnalogNAS on State-Of-The-Art (SOTA) models in terms of accuracy and deployment efficiency on various Tiny Machine Learning (TinyML) tasks. We also present experimental results that show AnalogNAS models achieving higher accuracy than SOTA models when implemented on a 64-core IMC chip based on Phase Change Memory (PCM). The AnalogNAS search code is released: https://github.com/IBM/analog-nas
Hardware-aware training for large-scale and diverse deep learning inference workloads using in-memory computing-based accelerators
Feb 16, 2023Analog in-memory computing (AIMC) -- a promising approach for energy-efficient acceleration of deep learning workloads -- computes matrix-vector multiplications (MVMs) but only approximately, due to nonidealities that often are non-deterministic or nonlinear. This can adversely impact the achievable deep neural network (DNN) inference accuracy as compared to a conventional floating point (FP) implementation. While retraining has previously been suggested to improve robustness, prior work has explored only a few DNN topologies, using disparate and overly simplified AIMC hardware models. Here, we use hardware-aware (HWA) training to systematically examine the accuracy of AIMC for multiple common artificial intelligence (AI) workloads across multiple DNN topologies, and investigate sensitivity and robustness to a broad set of nonidealities. By introducing a new and highly realistic AIMC crossbar-model, we improve significantly on earlier retraining approaches. We show that many large-scale DNNs of various topologies, including convolutional neural networks (CNNs), recurrent neural networks (RNNs), and transformers, can in fact be successfully retrained to show iso-accuracy on AIMC. Our results further suggest that AIMC nonidealities that add noise to the inputs or outputs, not the weights, have the largest impact on DNN accuracy, and that RNNs are particularly robust to all nonidealities.
In-memory Realization of In-situ Few-shot Continual Learning with a Dynamically Evolving Explicit Memory
Jul 14, 2022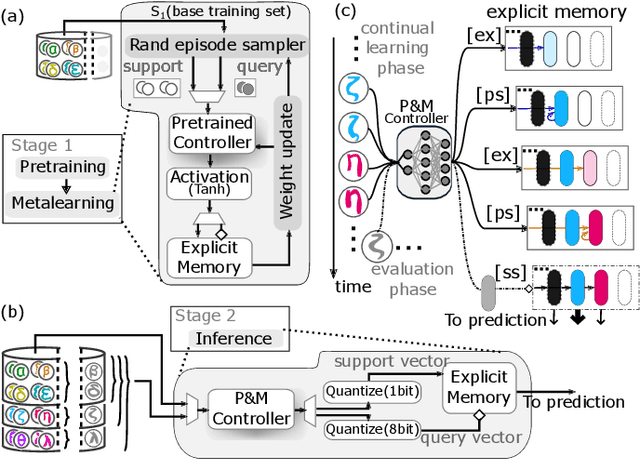
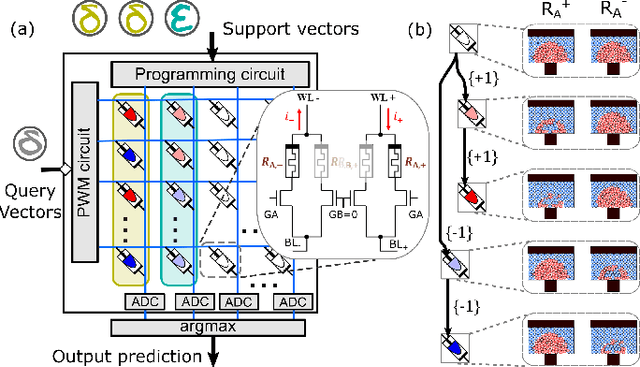
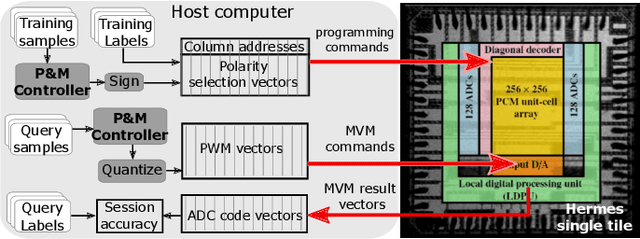
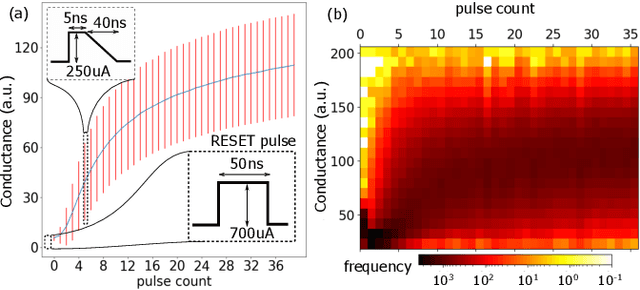
Continually learning new classes from a few training examples without forgetting previous old classes demands a flexible architecture with an inevitably growing portion of storage, in which new examples and classes can be incrementally stored and efficiently retrieved. One viable architectural solution is to tightly couple a stationary deep neural network to a dynamically evolving explicit memory (EM). As the centerpiece of this architecture, we propose an EM unit that leverages energy-efficient in-memory compute (IMC) cores during the course of continual learning operations. We demonstrate for the first time how the EM unit can physically superpose multiple training examples, expand to accommodate unseen classes, and perform similarity search during inference, using operations on an IMC core based on phase-change memory (PCM). Specifically, the physical superposition of a few encoded training examples is realized via in-situ progressive crystallization of PCM devices. The classification accuracy achieved on the IMC core remains within a range of 1.28%--2.5% compared to that of the state-of-the-art full-precision baseline software model on both the CIFAR-100 and miniImageNet datasets when continually learning 40 novel classes (from only five examples per class) on top of 60 old classes.
Joint Coreset Construction and Quantization for Distributed Machine Learning
Apr 13, 2022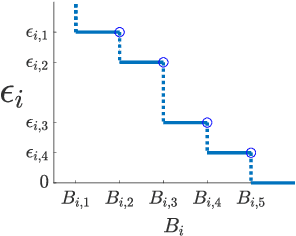
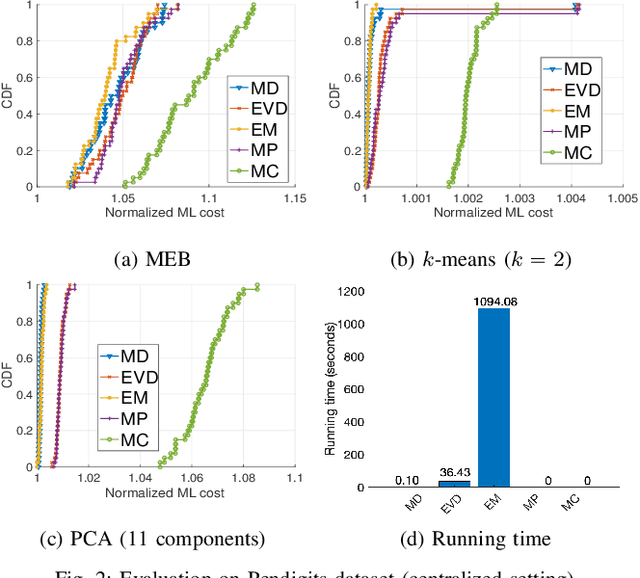
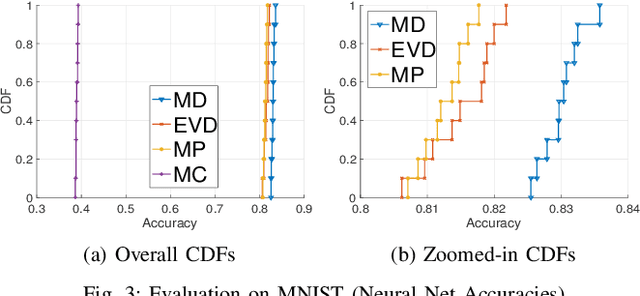
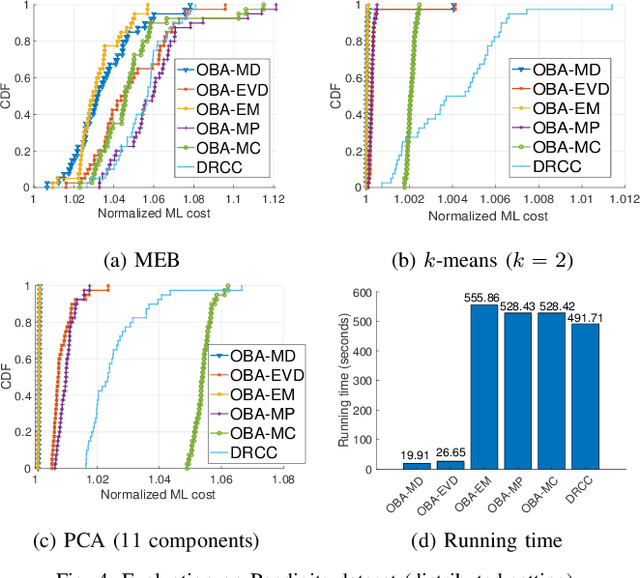
Coresets are small, weighted summaries of larger datasets, aiming at providing provable error bounds for machine learning (ML) tasks while significantly reducing the communication and computation costs. To achieve a better trade-off between ML error bounds and costs, we propose the first framework to incorporate quantization techniques into the process of coreset construction. Specifically, we theoretically analyze the ML error bounds caused by a combination of coreset construction and quantization. Based on that, we formulate an optimization problem to minimize the ML error under a fixed budget of communication cost. To improve the scalability for large datasets, we identify two proxies of the original objective function, for which efficient algorithms are developed. For the case of data on multiple nodes, we further design a novel algorithm to allocate the communication budget to the nodes while minimizing the overall ML error. Through extensive experiments on multiple real-world datasets, we demonstrate the effectiveness and efficiency of our proposed algorithms for a variety of ML tasks. In particular, our algorithms have achieved more than 90% data reduction with less than 10% degradation in ML performance in most cases.
A flexible and fast PyTorch toolkit for simulating training and inference on analog crossbar arrays
Apr 05, 2021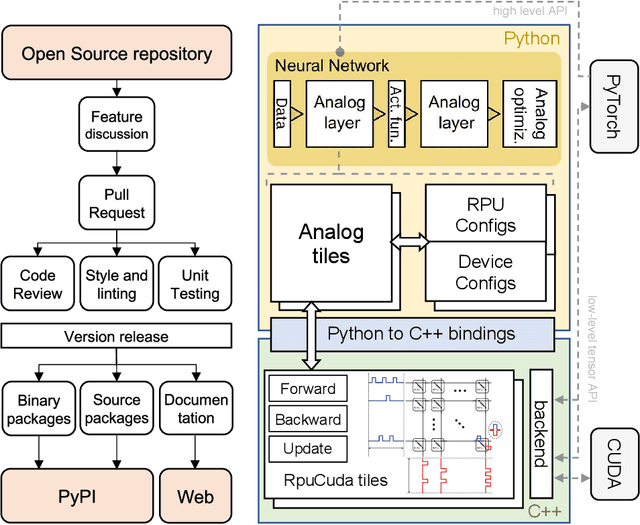

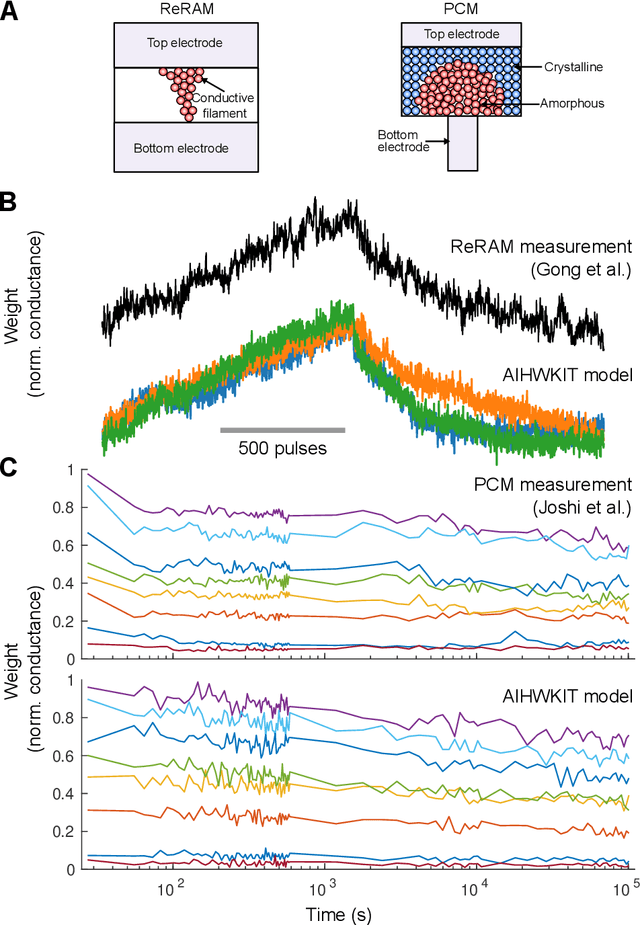

We introduce the IBM Analog Hardware Acceleration Kit, a new and first of a kind open source toolkit to simulate analog crossbar arrays in a convenient fashion from within PyTorch (freely available at https://github.com/IBM/aihwkit). The toolkit is under active development and is centered around the concept of an "analog tile" which captures the computations performed on a crossbar array. Analog tiles are building blocks that can be used to extend existing network modules with analog components and compose arbitrary artificial neural networks (ANNs) using the flexibility of the PyTorch framework. Analog tiles can be conveniently configured to emulate a plethora of different analog hardware characteristics and their non-idealities, such as device-to-device and cycle-to-cycle variations, resistive device response curves, and weight and output noise. Additionally, the toolkit makes it possible to design custom unit cell configurations and to use advanced analog optimization algorithms such as Tiki-Taka. Moreover, the backward and update behavior can be set to "ideal" to enable hardware-aware training features for chips that target inference acceleration only. To evaluate the inference accuracy of such chips over time, we provide statistical programming noise and drift models calibrated on phase-change memory hardware. Our new toolkit is fully GPU accelerated and can be used to conveniently estimate the impact of material properties and non-idealities of future analog technology on the accuracy for arbitrary ANNs.
Robust Coreset Construction for Distributed Machine Learning
Apr 11, 2019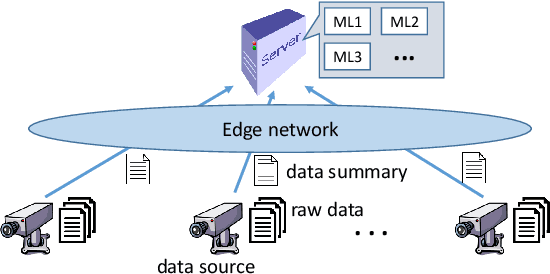
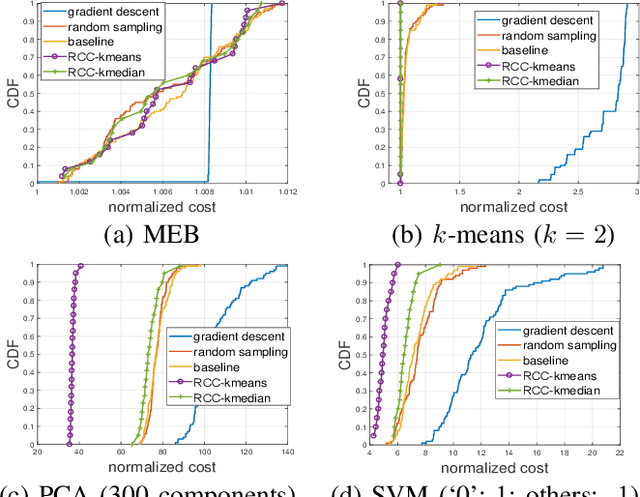
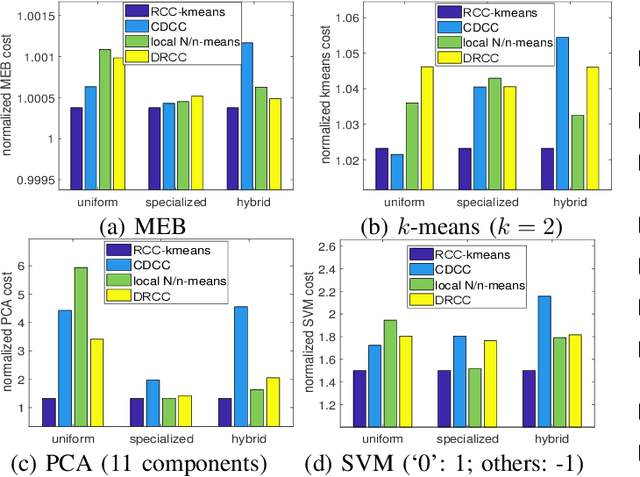
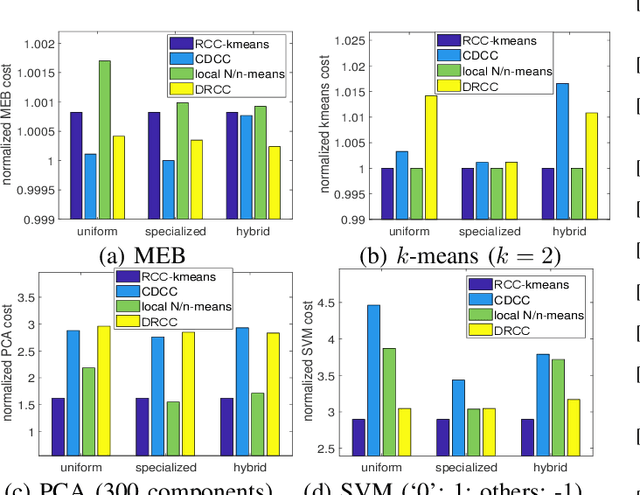
Motivated by the need of solving machine learning problems over distributed datasets, we explore the use of coreset to reduce the communication overhead. Coreset is a summary of the original dataset in the form of a small weighted set in the same sample space. Compared to other data summaries, coreset has the advantage that it can be used as a proxy of the original dataset, potentially for different applications. However, existing coreset construction algorithms are each tailor-made for a specific machine learning problem. Thus, to solve different machine learning problems, one has to collect coresets of different types, defeating the purpose of saving communication overhead. We resolve this dilemma by developing coreset construction algorithms based on k-means/median clustering, that give a provably good approximation for a broad range of machine learning problems with sufficiently continuous cost functions. Through evaluations on diverse datasets and machine learning problems, we verify the robust performance of the proposed algorithms.
A Quantitative Evaluation Framework for Missing Value Imputation Algorithms
Nov 10, 2013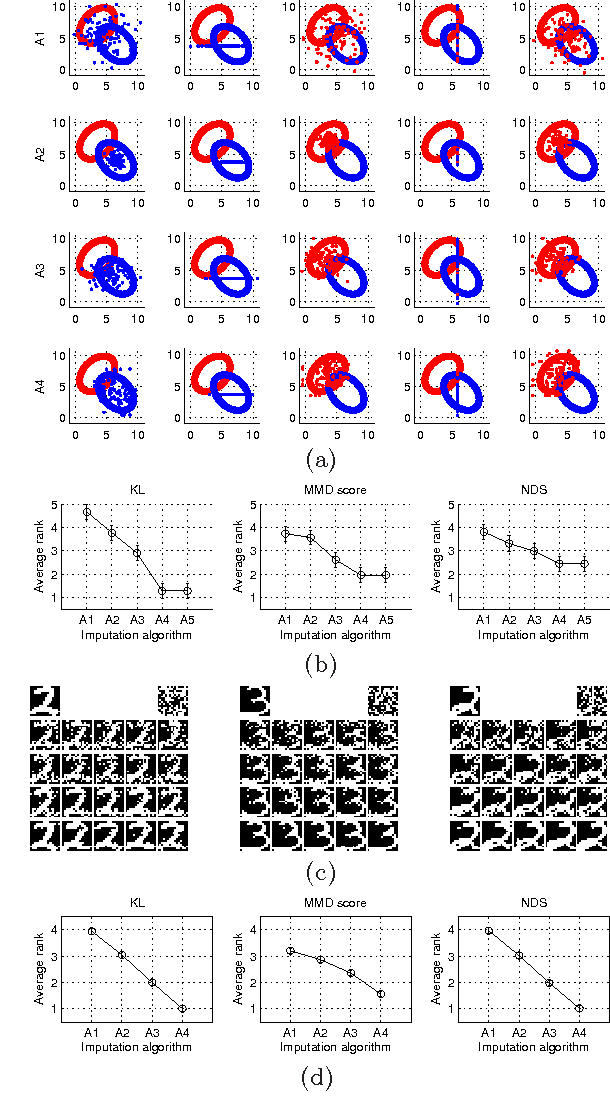
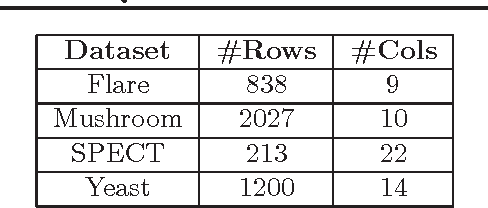
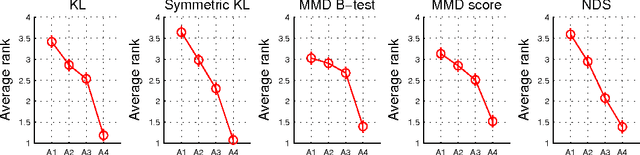
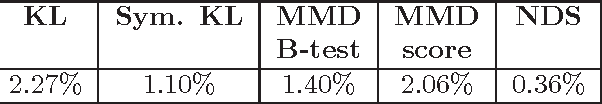
We consider the problem of quantitatively evaluating missing value imputation algorithms. Given a dataset with missing values and a choice of several imputation algorithms to fill them in, there is currently no principled way to rank the algorithms using a quantitative metric. We develop a framework based on treating imputation evaluation as a problem of comparing two distributions and show how it can be used to compute quantitative metrics. We present an efficient procedure for applying this framework to practical datasets, demonstrate several metrics derived from the existing literature on comparing distributions, and propose a new metric called Neighborhood-based Dissimilarity Score which is fast to compute and provides similar results. Results are shown on several datasets, metrics, and imputations algorithms.