 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFiGURe: Simple and Efficient Unsupervised Node Representations with Filter Augmentations
Oct 04, 2023



Unsupervised node representations learnt using contrastive learning-based methods have shown good performance on downstream tasks. However, these methods rely on augmentations that mimic low-pass filters, limiting their performance on tasks requiring different eigen-spectrum parts. This paper presents a simple filter-based augmentation method to capture different parts of the eigen-spectrum. We show significant improvements using these augmentations. Further, we show that sharing the same weights across these different filter augmentations is possible, reducing the computational load. In addition, previous works have shown that good performance on downstream tasks requires high dimensional representations. Working with high dimensions increases the computations, especially when multiple augmentations are involved. We mitigate this problem and recover good performance through lower dimensional embeddings using simple random Fourier feature projections. Our method, FiGURe achieves an average gain of up to 4.4%, compared to the state-of-the-art unsupervised models, across all datasets in consideration, both homophilic and heterophilic. Our code can be found at: https://github.com/microsoft/figure.
Simulating Network Paths with Recurrent Buffering Units
Feb 23, 2022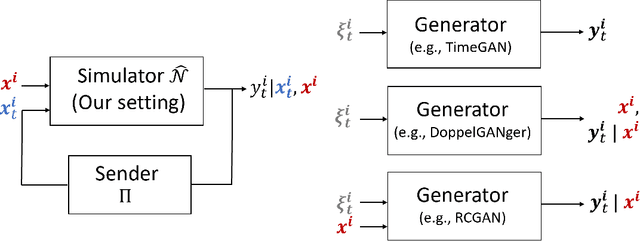
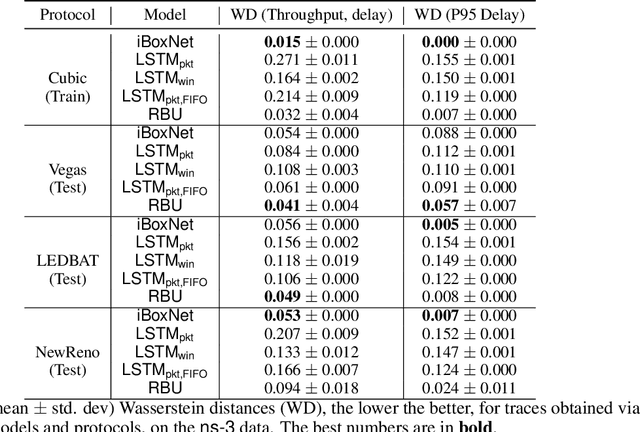
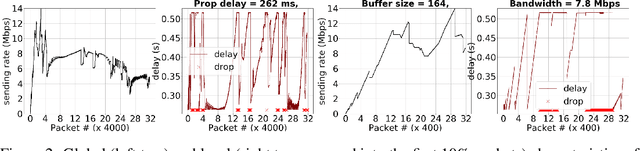
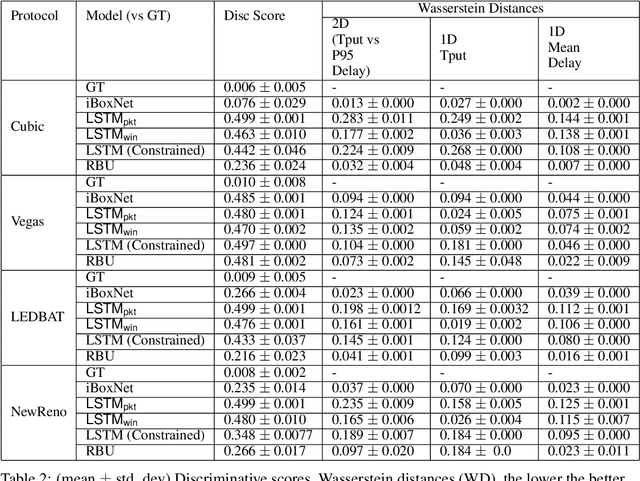
Simulating physical network paths (e.g., Internet) is a cornerstone research problem in the emerging sub-field of AI-for-networking. We seek a model that generates end-to-end packet delay values in response to the time-varying load offered by a sender, which is typically a function of the previously output delays. We formulate an ML problem at the intersection of dynamical systems, sequential decision making, and time-series generative modeling. We propose a novel grey-box approach to network simulation that embeds the semantics of physical network path in a new RNN-style architecture called Recurrent Buffering Unit, providing the interpretability of standard network simulator tools, the power of neural models, the efficiency of SGD-based techniques for learning, and yielding promising results on synthetic and real-world network traces.
A Piece-wise Polynomial Filtering Approach for Graph Neural Networks
Dec 07, 2021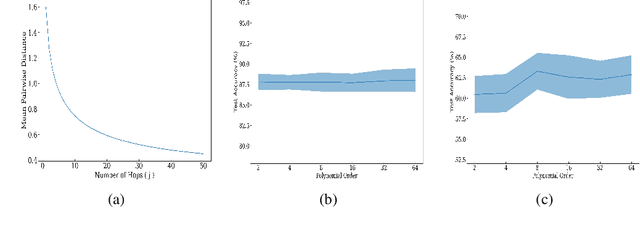
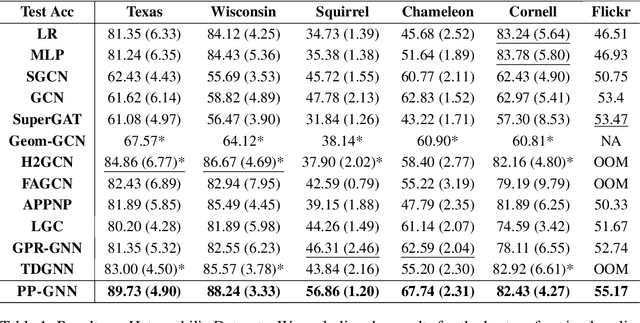
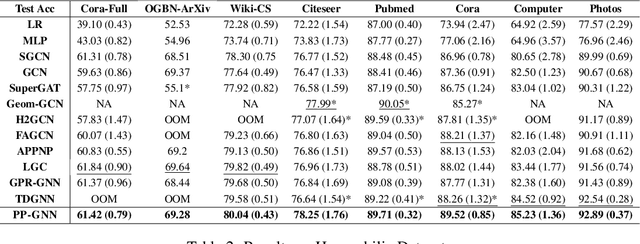
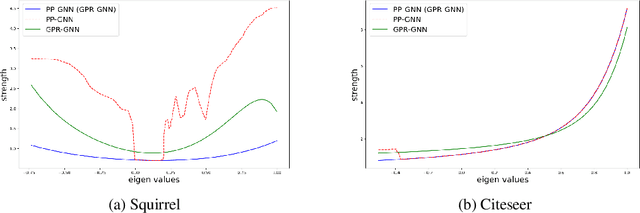
Graph Neural Networks (GNNs) exploit signals from node features and the input graph topology to improve node classification task performance. However, these models tend to perform poorly on heterophilic graphs, where connected nodes have different labels. Recently proposed GNNs work across graphs having varying levels of homophily. Among these, models relying on polynomial graph filters have shown promise. We observe that solutions to these polynomial graph filter models are also solutions to an overdetermined system of equations. It suggests that in some instances, the model needs to learn a reasonably high order polynomial. On investigation, we find the proposed models ineffective at learning such polynomials due to their designs. To mitigate this issue, we perform an eigendecomposition of the graph and propose to learn multiple adaptive polynomial filters acting on different subsets of the spectrum. We theoretically and empirically show that our proposed model learns a better filter, thereby improving classification accuracy. We study various aspects of our proposed model including, dependency on the number of eigencomponents utilized, latent polynomial filters learned, and performance of the individual polynomials on the node classification task. We further show that our model is scalable by evaluating over large graphs. Our model achieves performance gains of up to 5% over the state-of-the-art models and outperforms existing polynomial filter-based approaches in general.
IGLU: Efficient GCN Training via Lazy Updates
Sep 28, 2021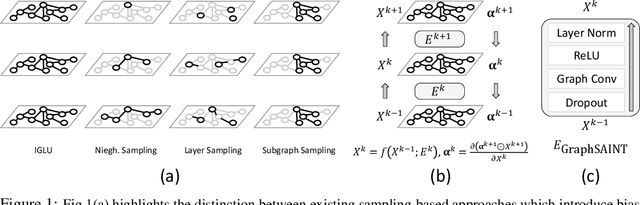
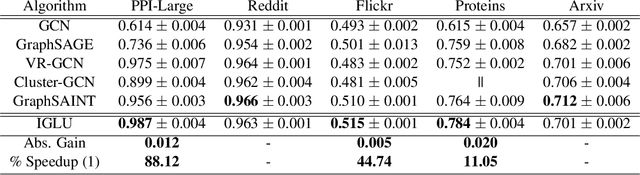
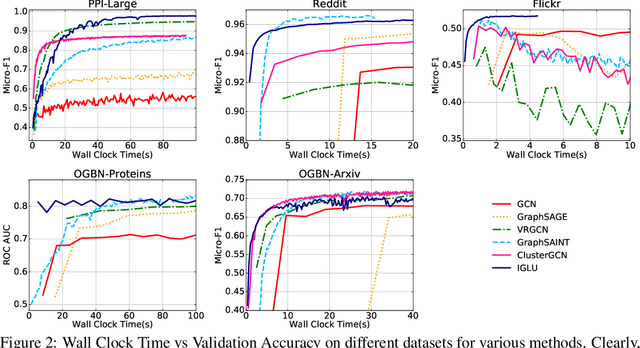

Graph Convolution Networks (GCN) are used in numerous settings involving a large underlying graph as well as several layers. Standard SGD-based training scales poorly here since each descent step ends up updating node embeddings for a large portion of the graph. Recent methods attempt to remedy this by sub-sampling the graph which does reduce the compute load, but at the cost of biased gradients which may offer suboptimal performance. In this work we introduce a new method IGLU that caches forward-pass embeddings for all nodes at various GCN layers. This enables IGLU to perform lazy updates that do not require updating a large number of node embeddings during descent which offers much faster convergence but does not significantly bias the gradients. Under standard assumptions such as objective smoothness, IGLU provably converges to a first-order saddle point. We validate IGLU extensively on a variety of benchmarks, where it offers up to 1.2% better accuracy despite requiring up to 88% less wall-clock time.
Effective Eigendecomposition based Graph Adaptation for Heterophilic Networks
Jul 28, 2021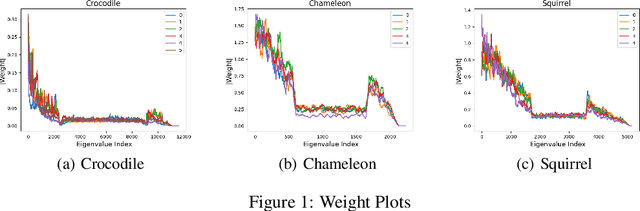
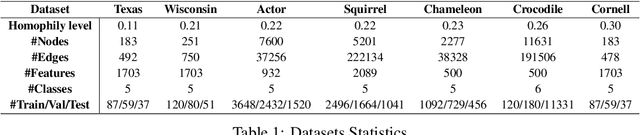
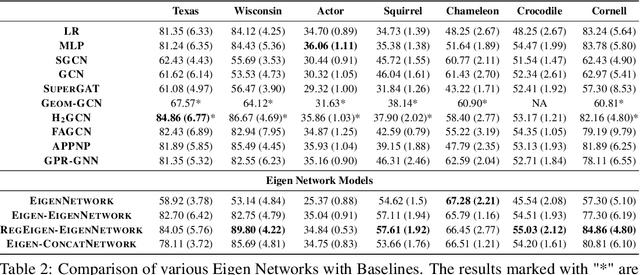
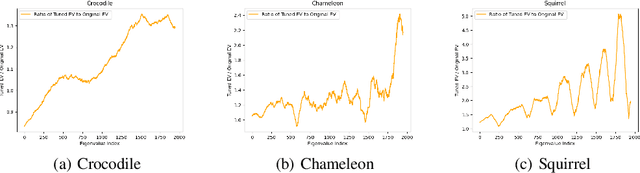
Graph Neural Networks (GNNs) exhibit excellent performance when graphs have strong homophily property, i.e. connected nodes have the same labels. However, they perform poorly on heterophilic graphs. Several approaches address the issue of heterophily by proposing models that adapt the graph by optimizing task-specific loss function using labelled data. These adaptations are made either via attention or by attenuating or enhancing various low-frequency/high-frequency signals, as needed for the task at hand. More recent approaches adapt the eigenvalues of the graph. One important interpretation of this adaptation is that these models select/weigh the eigenvectors of the graph. Based on this interpretation, we present an eigendecomposition based approach and propose EigenNetwork models that improve the performance of GNNs on heterophilic graphs. Performance improvement is achieved by learning flexible graph adaptation functions that modulate the eigenvalues of the graph. Regularization of these functions via parameter sharing helps to improve the performance even more. Our approach achieves up to 11% improvement in performance over the state-of-the-art methods on heterophilic graphs.
Simple Truncated SVD based Model for Node Classification on Heterophilic Graphs
Jun 24, 2021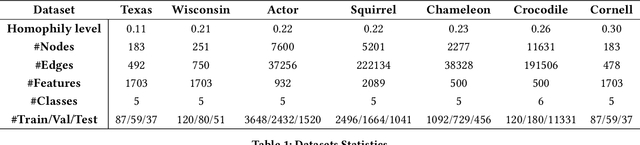
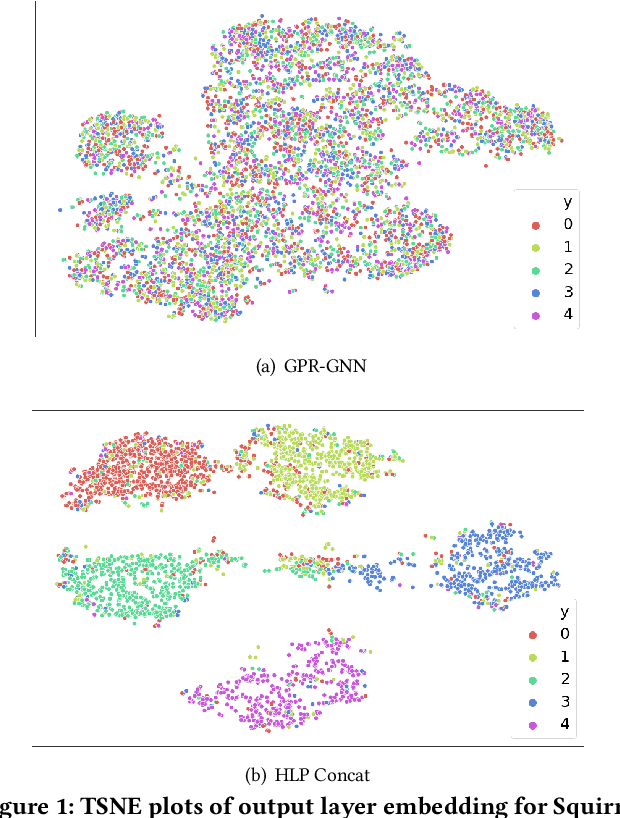
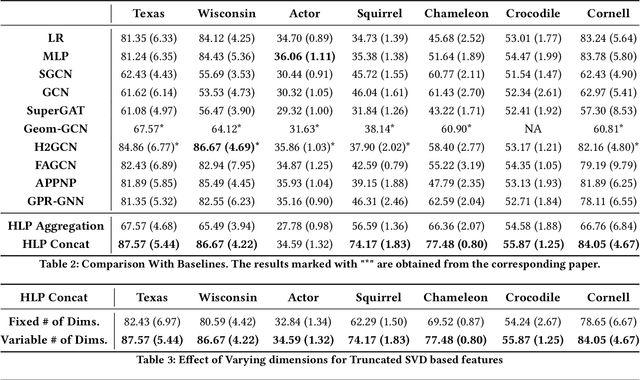
Graph Neural Networks (GNNs) have shown excellent performance on graphs that exhibit strong homophily with respect to the node labels i.e. connected nodes have same labels. However, they perform poorly on heterophilic graphs. Recent approaches have typically modified aggregation schemes, designed adaptive graph filters, etc. to address this limitation. In spite of this, the performance on heterophilic graphs can still be poor. We propose a simple alternative method that exploits Truncated Singular Value Decomposition (TSVD) of topological structure and node features. Our approach achieves up to ~30% improvement in performance over state-of-the-art methods on heterophilic graphs. This work is an early investigation into methods that differ from aggregation based approaches. Our experimental results suggest that it might be important to explore other alternatives to aggregation methods for heterophilic setting.
User Embedding based Neighborhood Aggregation Method for Inductive Recommendation
Feb 16, 2021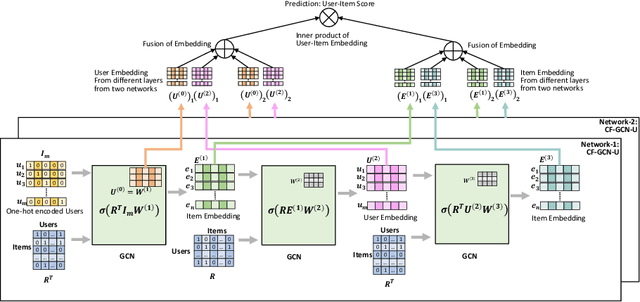
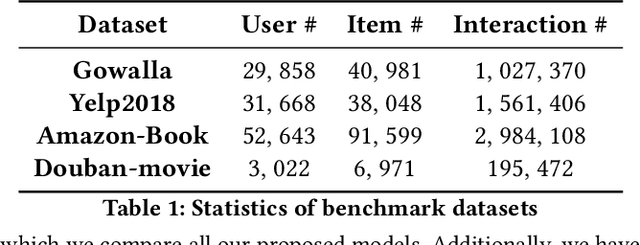
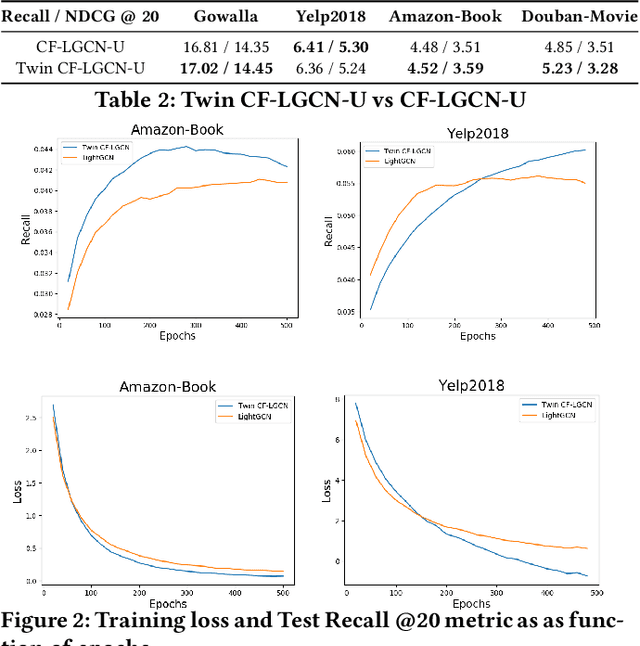
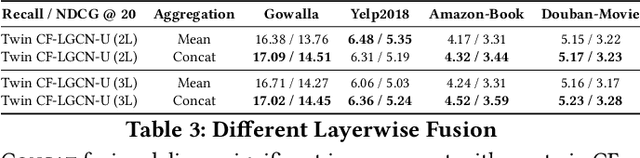
We consider the problem of learning latent features (aka embedding) for users and items in a recommendation setting. Given only a user-item interaction graph, the goal is to recommend items for each user. Traditional approaches employ matrix factorization-based collaborative filtering methods. Recent methods using graph convolutional networks (e.g., LightGCN) achieve state-of-the-art performance. They learn both user and item embedding. One major drawback of most existing methods is that they are not inductive; they do not generalize for users and items unseen during training. Besides, existing network models are quite complex, difficult to train and scale. Motivated by LightGCN, we propose a graph convolutional network modeling approach for collaborative filtering CF-GCN. We solely learn user embedding and derive item embedding using light variant CF-LGCN-U performing neighborhood aggregation, making it scalable due to reduced model complexity. CF-LGCN-U models naturally possess the inductive capability for new items, and we propose a simple solution to generalize for new users. We show how the proposed models are related to LightGCN. As a by-product, we suggest a simple solution to make LightGCN inductive. We perform comprehensive experiments on several benchmark datasets and demonstrate the capabilities of the proposed approach. Experimental results show that similar or better generalization performance is achievable than the state of the art methods in both transductive and inductive settings.
HeteGCN: Heterogeneous Graph Convolutional Networks for Text Classification
Aug 19, 2020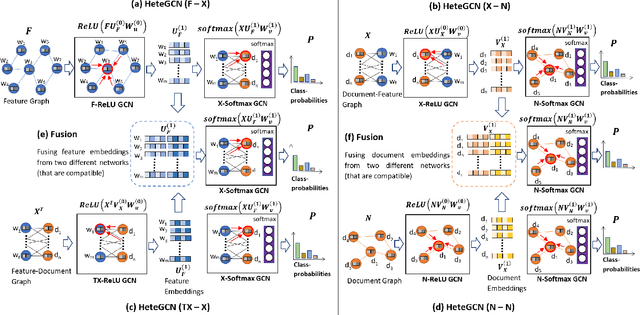
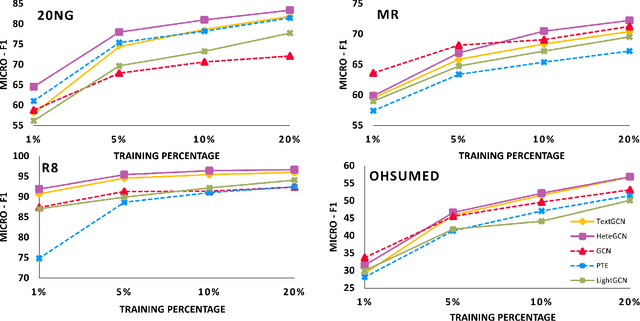
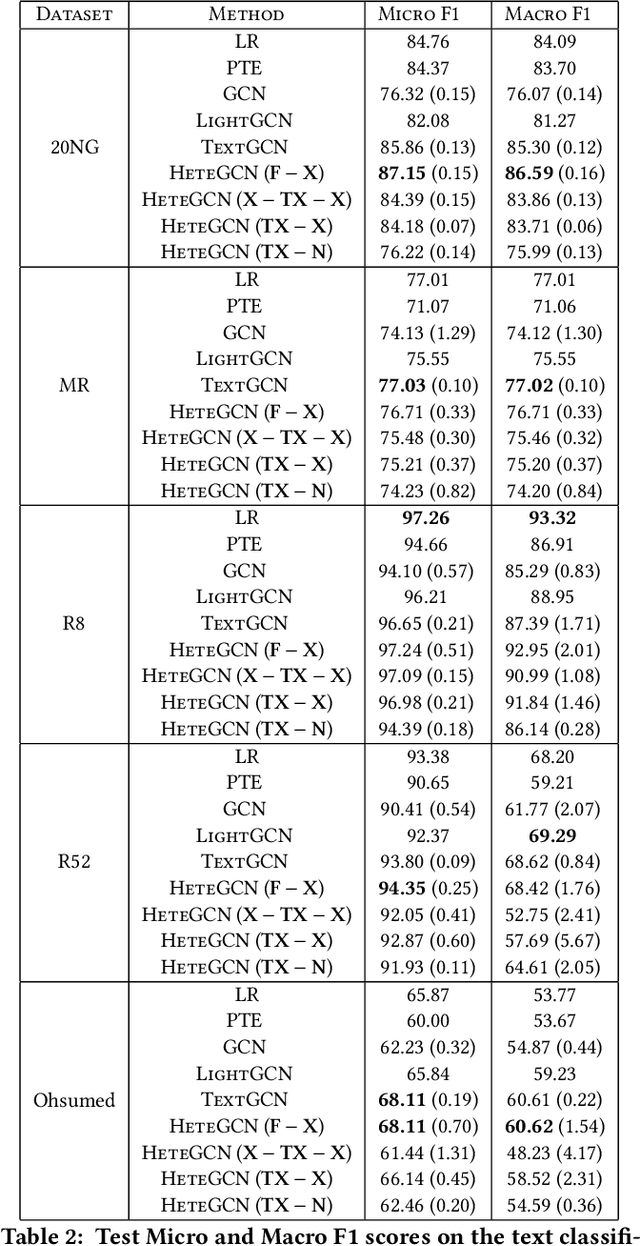
We consider the problem of learning efficient and inductive graph convolutional networks for text classification with a large number of examples and features. Existing state-of-the-art graph embedding based methods such as predictive text embedding (PTE) and TextGCN have shortcomings in terms of predictive performance, scalability and inductive capability. To address these limitations, we propose a heterogeneous graph convolutional network (HeteGCN) modeling approach that unites the best aspects of PTE and TextGCN together. The main idea is to learn feature embeddings and derive document embeddings using a HeteGCN architecture with different graphs used across layers. We simplify TextGCN by dissecting into several HeteGCN models which (a) helps to study the usefulness of individual models and (b) offers flexibility in fusing learned embeddings from different models. In effect, the number of model parameters is reduced significantly, enabling faster training and improving performance in small labeled training set scenario. Our detailed experimental studies demonstrate the efficacy of the proposed approach.
A Graph Convolutional Network Composition Framework for Semi-supervised Classification
Apr 08, 2020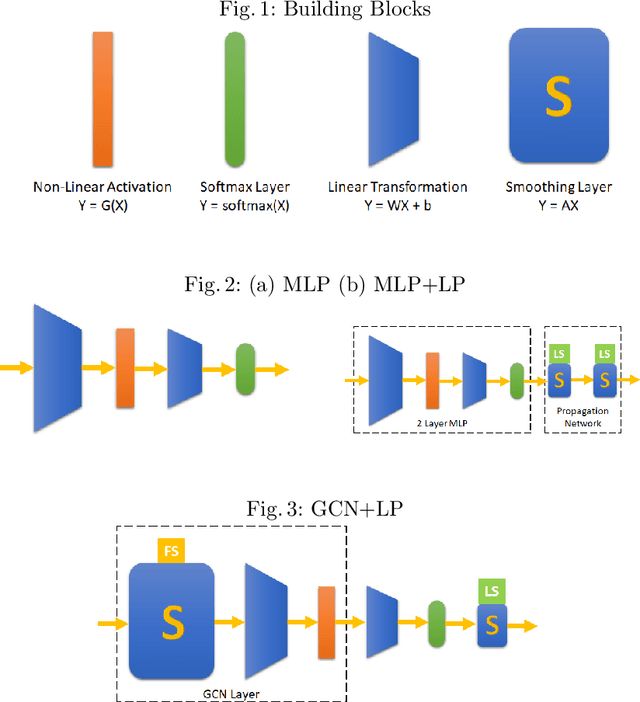

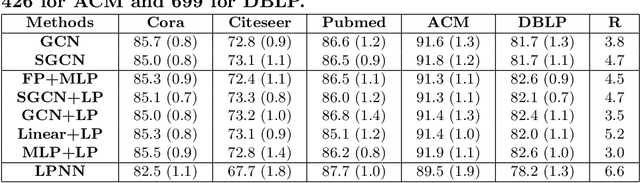
Graph convolutional networks (GCNs) have gained popularity due to high performance achievable on several downstream tasks including node classification. Several architectural variants of these networks have been proposed and investigated with experimental studies in the literature. Motivated by a recent work on simplifying GCNs, we study the problem of designing other variants and propose a framework to compose networks using building blocks of GCN. The framework offers flexibility to compose and evaluate different networks using feature and/or label propagation networks, linear or non-linear networks, with each composition having different computational complexity. We conduct a detailed experimental study on several benchmark datasets with many variants and present observations from our evaluation. Our empirical experimental results suggest that several newly composed variants are useful alternatives to consider because they are as competitive as, or better than the original GCN.
Learning Semantically Coherent and Reusable Kernels in Convolution Neural Nets for Sentence Classification
Oct 10, 2016
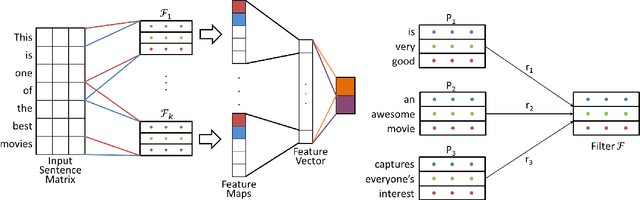
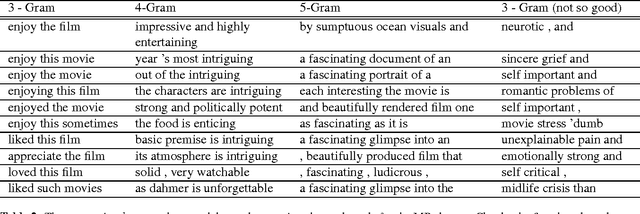

The state-of-the-art CNN models give good performance on sentence classification tasks. The purpose of this work is to empirically study desirable properties such as semantic coherence, attention mechanism and reusability of CNNs in these tasks. Semantically coherent kernels are preferable as they are a lot more interpretable for explaining the decision of the learned CNN model. We observe that the learned kernels do not have semantic coherence. Motivated by this observation, we propose to learn kernels with semantic coherence using clustering scheme combined with Word2Vec representation and domain knowledge such as SentiWordNet. We suggest a technique to visualize attention mechanism of CNNs for decision explanation purpose. Reusable property enables kernels learned on one problem to be used in another problem. This helps in efficient learning as only a few additional domain specific filters may have to be learned. We demonstrate the efficacy of our core ideas of learning semantically coherent kernels and leveraging reusable kernels for efficient learning on several benchmark datasets. Experimental results show the usefulness of our approach by achieving performance close to the state-of-the-art methods but with semantic and reusable properties.