 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving training time and GPU utilization in geo-distributed language model training
Nov 16, 2024The widespread adoption of language models (LMs) across multiple industries has caused huge surge in demand for GPUs. Training LMs requires tens of thousands of GPUs and housing them in the same datacenter (DCs) is becoming challenging. We focus on training such models across multiple DCs connected via Wide-Area-Network (WAN). We build ATLAS that speeds up such training time using novel temporal bandwidth sharing and many other design choices. While ATLAS improves the training time, it does not eliminate the bubbles (idle GPU cycles). We built BUBBLETEA that runs prefill-as-a-service (part of LM inference) during the bubbles that improves the GPU utilization substantially without any impact of training. Together, ATLAS and BUBBLETEA improve training time by up to 17X and achieve GPU utilization of up to 94%.
Simulating Network Paths with Recurrent Buffering Units
Feb 23, 2022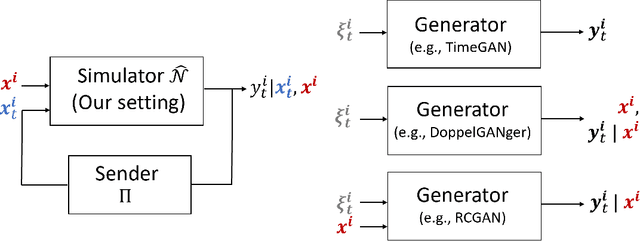
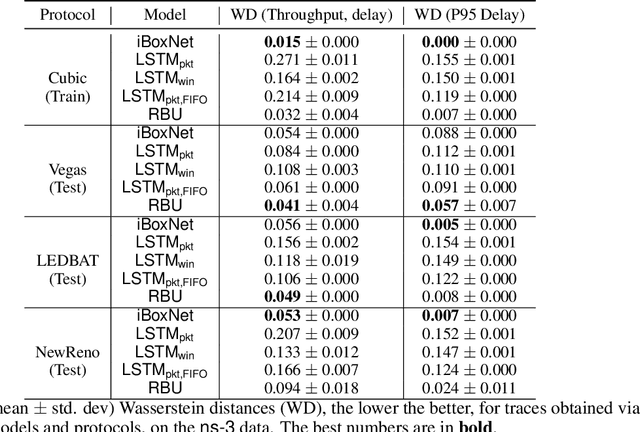
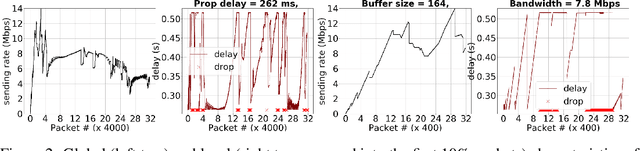
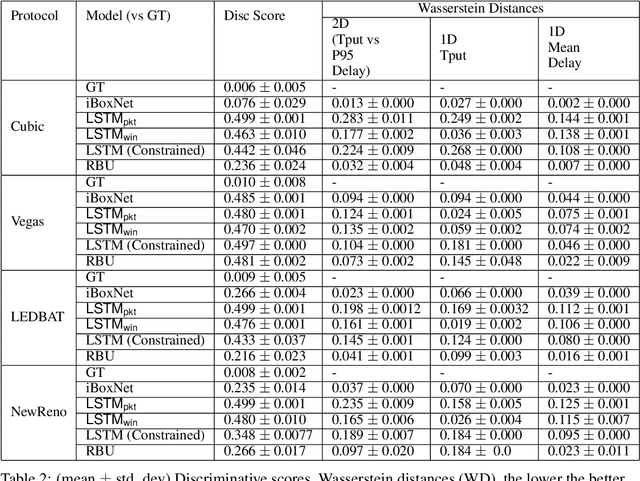
Simulating physical network paths (e.g., Internet) is a cornerstone research problem in the emerging sub-field of AI-for-networking. We seek a model that generates end-to-end packet delay values in response to the time-varying load offered by a sender, which is typically a function of the previously output delays. We formulate an ML problem at the intersection of dynamical systems, sequential decision making, and time-series generative modeling. We propose a novel grey-box approach to network simulation that embeds the semantics of physical network path in a new RNN-style architecture called Recurrent Buffering Unit, providing the interpretability of standard network simulator tools, the power of neural models, the efficiency of SGD-based techniques for learning, and yielding promising results on synthetic and real-world network traces.