 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExecTune: Effective Steering of Black-Box LLMs with Guide Models
Apr 09, 2026For large language models deployed through black-box APIs, recurring inference costs often exceed one-time training costs. This motivates composed agentic systems that amortize expensive reasoning into reusable intermediate representations. We study a broad class of such systems, termed Guide-Core Policies (GCoP), in which a guide model generates a structured strategy that is executed by a black-box core model. This abstraction subsumes base, supervised, and advisor-style approaches, which differ primarily in how the guide is trained. We formalize GCoP under a cost-sensitive utility objective and show that end-to-end performance is governed by guide-averaged executability: the probability that a strategy generated by the guide can be faithfully executed by the core. Our analysis shows that existing GCoP instantiations often fail to optimize executability under deployment constraints, resulting in brittle strategies and inefficient computation. Motivated by these insights, we propose ExecTune, a principled training recipe that combines teacher-guided acceptance sampling, supervised fine-tuning, and structure-aware reinforcement learning to directly optimize syntactic validity, execution success, and cost efficiency. Across mathematical reasoning and code-generation benchmarks, GCoP with ExecTune improves accuracy by up to 9.2% over prior state-of-the-art baselines while reducing inference cost by up to 22.4%. It enables Claude Haiku 3.5 to outperform Sonnet 3.5 on both math and code tasks, and to come within 1.7% absolute accuracy of Sonnet 4 at 38% lower cost. Beyond efficiency, GCoP also supports modular adaptation by updating the guide without retraining the core.
MURPHY: Multi-Turn GRPO for Self Correcting Code Generation
Nov 11, 2025Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a powerful framework for enhancing the reasoning capabilities of large language models (LLMs). However, existing approaches such as Group Relative Policy Optimization (GRPO) and its variants, while effective on reasoning benchmarks, struggle with agentic tasks that require iterative decision-making. We introduce Murphy, a multi-turn reflective optimization framework that extends GRPO by incorporating iterative self-correction during training. By leveraging both quantitative and qualitative execution feedback, Murphy enables models to progressively refine their reasoning across multiple turns. Evaluations on code generation benchmarks with model families such as Qwen and OLMo show that Murphy consistently improves performance, achieving up to a 8% relative gain in pass@1 over GRPO, on similar compute budgets.
SVFT: Parameter-Efficient Fine-Tuning with Singular Vectors
May 30, 2024



Popular parameter-efficient fine-tuning (PEFT) methods, such as LoRA and its variants, freeze pre-trained model weights \(W\) and inject learnable matrices \(\Delta W\). These \(\Delta W\) matrices are structured for efficient parameterization, often using techniques like low-rank approximations or scaling vectors. However, these methods typically show a performance gap compared to full fine-tuning. Although recent PEFT methods have narrowed this gap, they do so at the cost of additional learnable parameters. We propose SVFT, a simple approach that fundamentally differs from existing methods: the structure imposed on \(\Delta W\) depends on the specific weight matrix \(W\). Specifically, SVFT updates \(W\) as a sparse combination of outer products of its singular vectors, training only the coefficients (scales) of these sparse combinations. This approach allows fine-grained control over expressivity through the number of coefficients. Extensive experiments on language and vision benchmarks show that SVFT recovers up to 96% of full fine-tuning performance while training only 0.006 to 0.25% of parameters, outperforming existing methods that only recover up to 85% performance using 0.03 to 0.8% of the trainable parameter budget.
Probing Graph Representations
Mar 07, 2023



Today we have a good theoretical understanding of the representational power of Graph Neural Networks (GNNs). For example, their limitations have been characterized in relation to a hierarchy of Weisfeiler-Lehman (WL) isomorphism tests. However, we do not know what is encoded in the learned representations. This is our main question. We answer it using a probing framework to quantify the amount of meaningful information captured in graph representations. Our findings on molecular datasets show the potential of probing for understanding the inductive biases of graph-based models. We compare different families of models and show that transformer-based models capture more chemically relevant information compared to models based on message passing. We also study the effect of different design choices such as skip connections and virtual nodes. We advocate for probing as a useful diagnostic tool for evaluating graph-based models.
A Piece-wise Polynomial Filtering Approach for Graph Neural Networks
Dec 07, 2021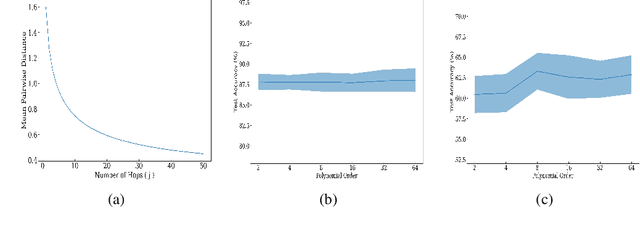
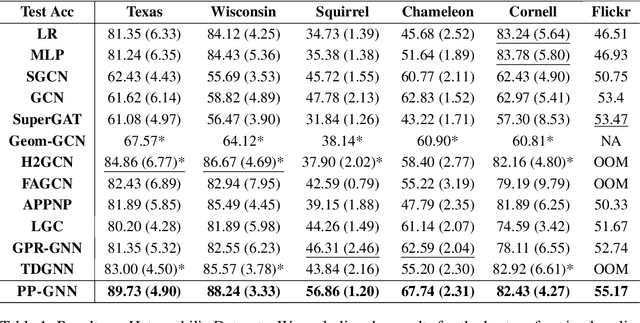
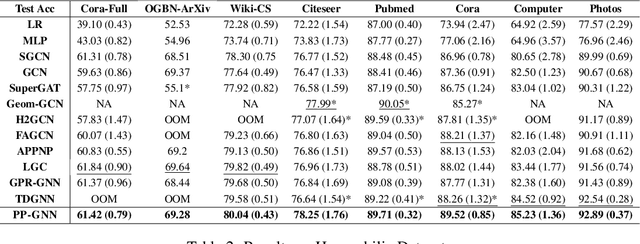
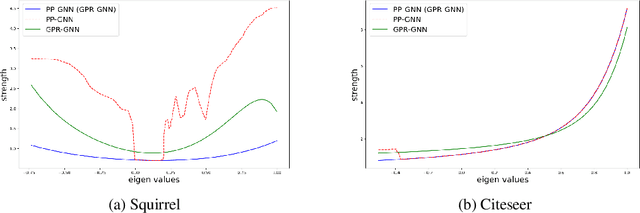
Graph Neural Networks (GNNs) exploit signals from node features and the input graph topology to improve node classification task performance. However, these models tend to perform poorly on heterophilic graphs, where connected nodes have different labels. Recently proposed GNNs work across graphs having varying levels of homophily. Among these, models relying on polynomial graph filters have shown promise. We observe that solutions to these polynomial graph filter models are also solutions to an overdetermined system of equations. It suggests that in some instances, the model needs to learn a reasonably high order polynomial. On investigation, we find the proposed models ineffective at learning such polynomials due to their designs. To mitigate this issue, we perform an eigendecomposition of the graph and propose to learn multiple adaptive polynomial filters acting on different subsets of the spectrum. We theoretically and empirically show that our proposed model learns a better filter, thereby improving classification accuracy. We study various aspects of our proposed model including, dependency on the number of eigencomponents utilized, latent polynomial filters learned, and performance of the individual polynomials on the node classification task. We further show that our model is scalable by evaluating over large graphs. Our model achieves performance gains of up to 5% over the state-of-the-art models and outperforms existing polynomial filter-based approaches in general.
Effective Eigendecomposition based Graph Adaptation for Heterophilic Networks
Jul 28, 2021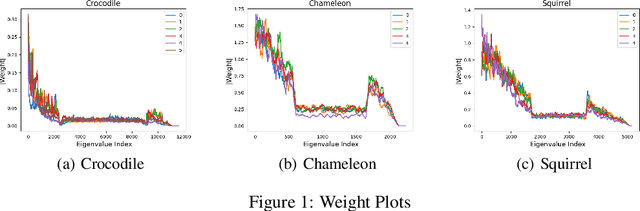
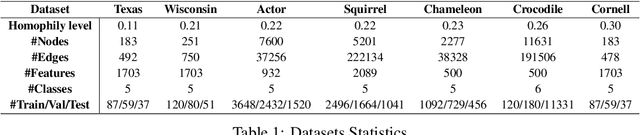
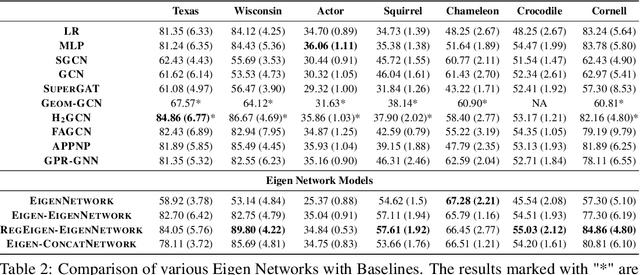
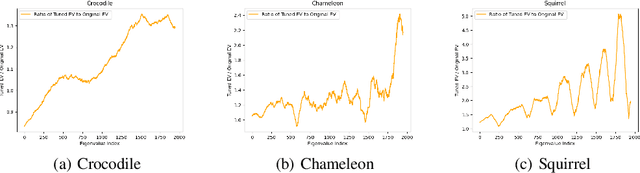
Graph Neural Networks (GNNs) exhibit excellent performance when graphs have strong homophily property, i.e. connected nodes have the same labels. However, they perform poorly on heterophilic graphs. Several approaches address the issue of heterophily by proposing models that adapt the graph by optimizing task-specific loss function using labelled data. These adaptations are made either via attention or by attenuating or enhancing various low-frequency/high-frequency signals, as needed for the task at hand. More recent approaches adapt the eigenvalues of the graph. One important interpretation of this adaptation is that these models select/weigh the eigenvectors of the graph. Based on this interpretation, we present an eigendecomposition based approach and propose EigenNetwork models that improve the performance of GNNs on heterophilic graphs. Performance improvement is achieved by learning flexible graph adaptation functions that modulate the eigenvalues of the graph. Regularization of these functions via parameter sharing helps to improve the performance even more. Our approach achieves up to 11% improvement in performance over the state-of-the-art methods on heterophilic graphs.
Simple Truncated SVD based Model for Node Classification on Heterophilic Graphs
Jun 24, 2021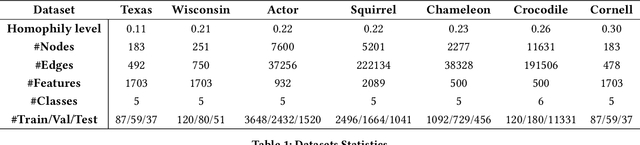
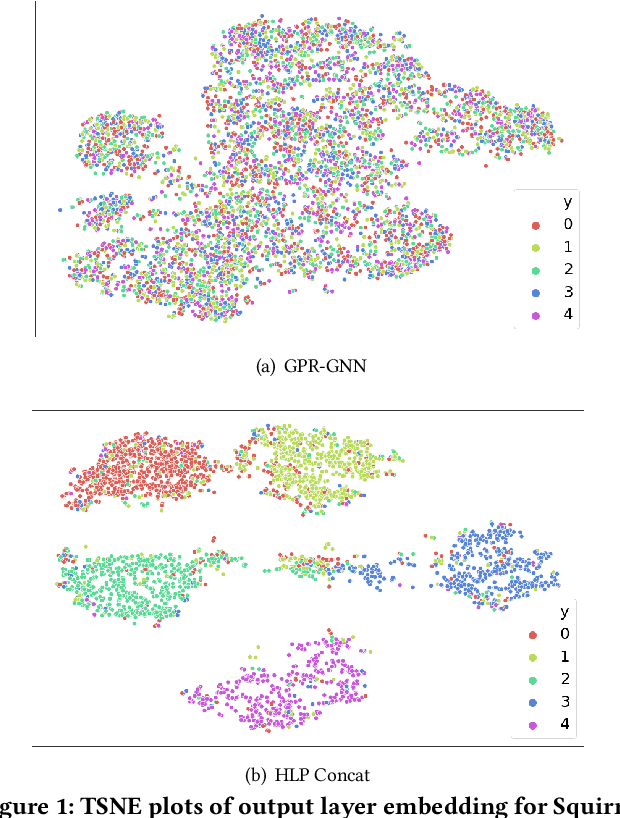
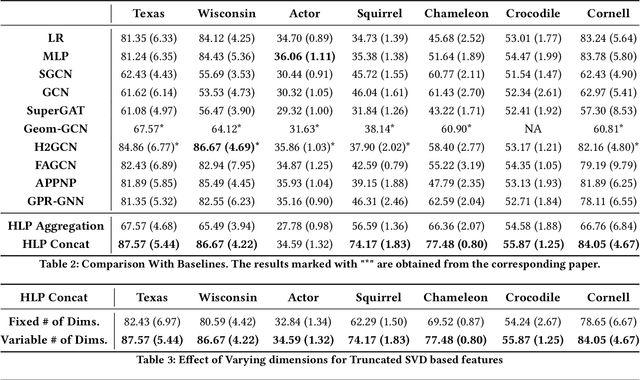
Graph Neural Networks (GNNs) have shown excellent performance on graphs that exhibit strong homophily with respect to the node labels i.e. connected nodes have same labels. However, they perform poorly on heterophilic graphs. Recent approaches have typically modified aggregation schemes, designed adaptive graph filters, etc. to address this limitation. In spite of this, the performance on heterophilic graphs can still be poor. We propose a simple alternative method that exploits Truncated Singular Value Decomposition (TSVD) of topological structure and node features. Our approach achieves up to ~30% improvement in performance over state-of-the-art methods on heterophilic graphs. This work is an early investigation into methods that differ from aggregation based approaches. Our experimental results suggest that it might be important to explore other alternatives to aggregation methods for heterophilic setting.
GLAM: Graph Learning by Modeling Affinity to Labeled Nodes for Graph Neural Networks
Feb 20, 2021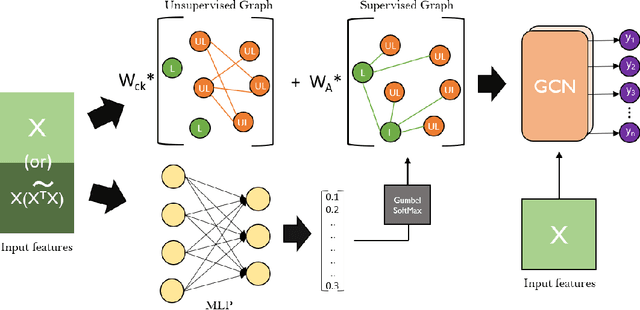
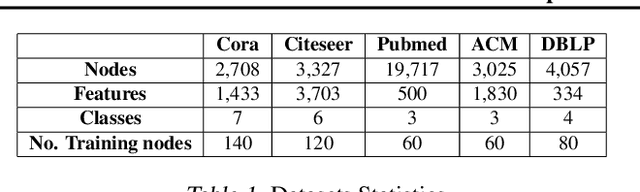
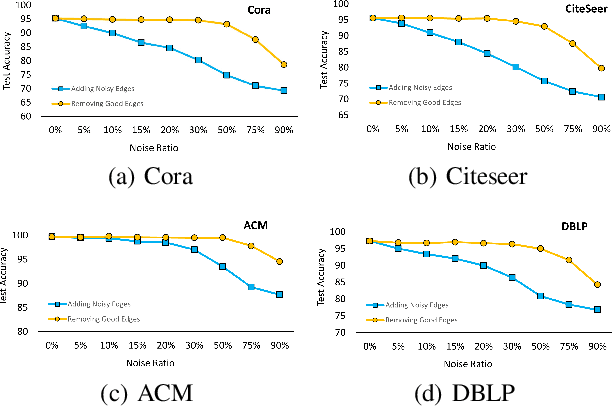
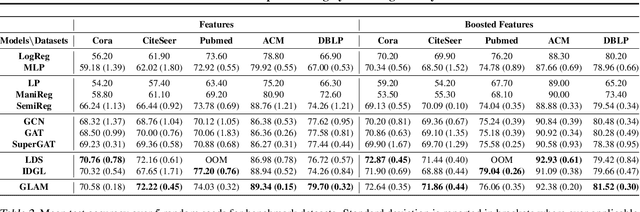
Graph Neural Networks have shown excellent performance on semi-supervised classification tasks. However, they assume access to a graph that may not be often available in practice. In the absence of any graph, constructing k-Nearest Neighbor (kNN) graphs from the given data have shown to give improvements when used with GNNs over other semi-supervised methods. This paper proposes a semi-supervised graph learning method for cases when there are no graphs available. This method learns a graph as a convex combination of the unsupervised kNN graph and a supervised label-affinity graph. The label-affinity graph directly captures all the nodes' label-affinity with the labeled nodes, i.e., how likely a node has the same label as the labeled nodes. This affinity measure contrasts with the kNN graph where the metric measures closeness in the feature space. Our experiments suggest that this approach gives close to or better performance (up to 1.5%), while being simpler and faster (up to 70x) to train, than state-of-the-art graph learning methods. We also conduct several experiments to highlight the importance of individual components and contrast them with state-of-the-art methods.
User Embedding based Neighborhood Aggregation Method for Inductive Recommendation
Feb 16, 2021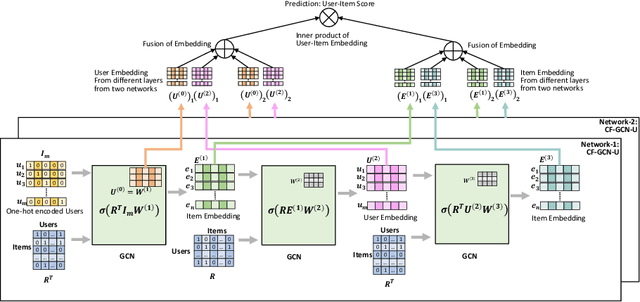
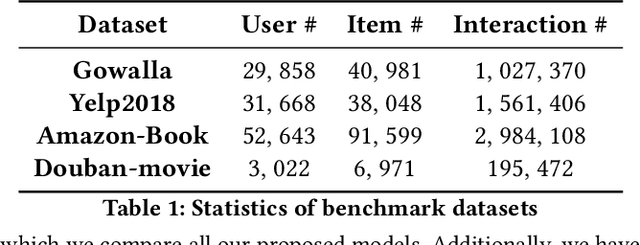
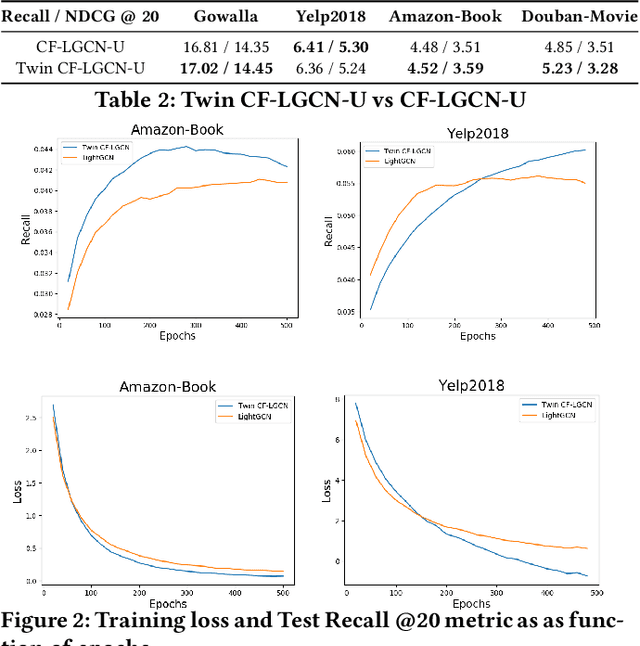
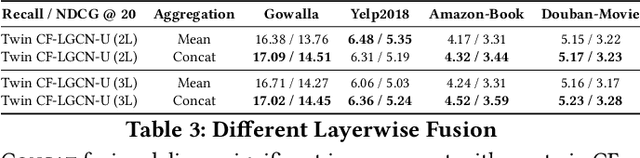
We consider the problem of learning latent features (aka embedding) for users and items in a recommendation setting. Given only a user-item interaction graph, the goal is to recommend items for each user. Traditional approaches employ matrix factorization-based collaborative filtering methods. Recent methods using graph convolutional networks (e.g., LightGCN) achieve state-of-the-art performance. They learn both user and item embedding. One major drawback of most existing methods is that they are not inductive; they do not generalize for users and items unseen during training. Besides, existing network models are quite complex, difficult to train and scale. Motivated by LightGCN, we propose a graph convolutional network modeling approach for collaborative filtering CF-GCN. We solely learn user embedding and derive item embedding using light variant CF-LGCN-U performing neighborhood aggregation, making it scalable due to reduced model complexity. CF-LGCN-U models naturally possess the inductive capability for new items, and we propose a simple solution to generalize for new users. We show how the proposed models are related to LightGCN. As a by-product, we suggest a simple solution to make LightGCN inductive. We perform comprehensive experiments on several benchmark datasets and demonstrate the capabilities of the proposed approach. Experimental results show that similar or better generalization performance is achievable than the state of the art methods in both transductive and inductive settings.
HeteGCN: Heterogeneous Graph Convolutional Networks for Text Classification
Aug 19, 2020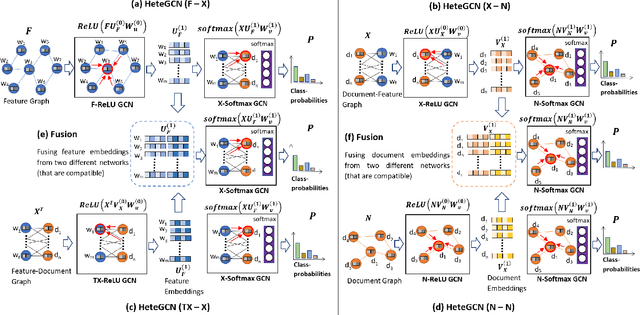
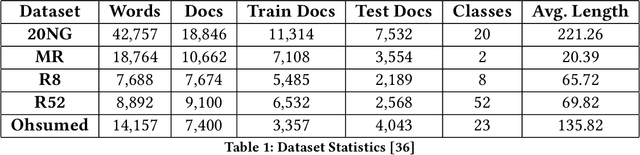
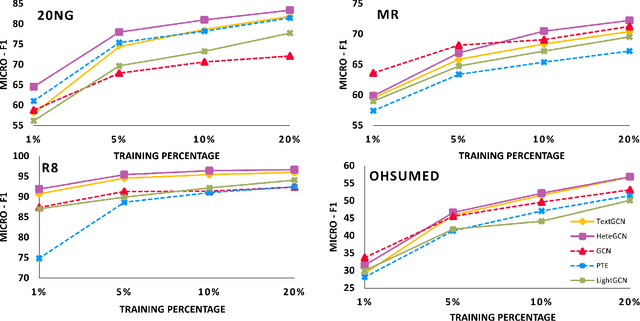
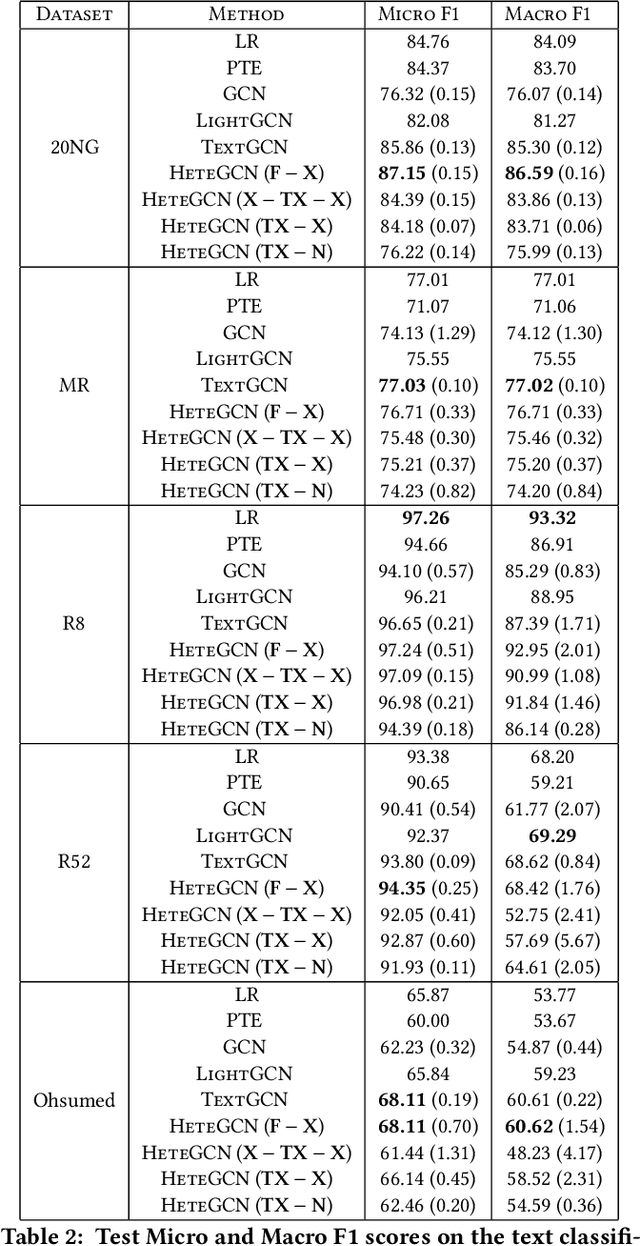
We consider the problem of learning efficient and inductive graph convolutional networks for text classification with a large number of examples and features. Existing state-of-the-art graph embedding based methods such as predictive text embedding (PTE) and TextGCN have shortcomings in terms of predictive performance, scalability and inductive capability. To address these limitations, we propose a heterogeneous graph convolutional network (HeteGCN) modeling approach that unites the best aspects of PTE and TextGCN together. The main idea is to learn feature embeddings and derive document embeddings using a HeteGCN architecture with different graphs used across layers. We simplify TextGCN by dissecting into several HeteGCN models which (a) helps to study the usefulness of individual models and (b) offers flexibility in fusing learned embeddings from different models. In effect, the number of model parameters is reduced significantly, enabling faster training and improving performance in small labeled training set scenario. Our detailed experimental studies demonstrate the efficacy of the proposed approach.