 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntRGi: Entropy Aware Reward Guidance for Diffusion Language Models
Feb 04, 2026Reward guidance has been applied to great success in the test-time adaptation of continuous diffusion models; it updates each denoising step using the gradients from a downstream reward model. We study reward guidance for discrete diffusion language models, where one cannot differentiate through the natural outputs of the model because they are discrete tokens. Existing approaches either replace these discrete tokens with continuous relaxations, or employ techniques like the straight-through estimator. In this work, we show the downsides of both these methods. The former degrades gradient feedback because the reward model has never been trained with continuous inputs. The latter involves incorrect optimization because the gradient evaluated at discrete tokens is used to update continuous logits. Our key innovation is to go beyond this tradeoff by introducing a novel mechanism called EntRGi: Entropy aware Reward Guidance that dynamically regulates the gradients from the reward model. By modulating the continuous relaxation using the model's confidence, our approach substantially improves reward guidance while providing reliable inputs to the reward model. We empirically validate our approach on a 7B-parameter diffusion language model across 3 diverse reward models and 3 multi-skill benchmarks, showing consistent improvements over state-of-the-art methods.
RARe: Retrieval Augmented Retrieval with In-Context Examples
Oct 26, 2024
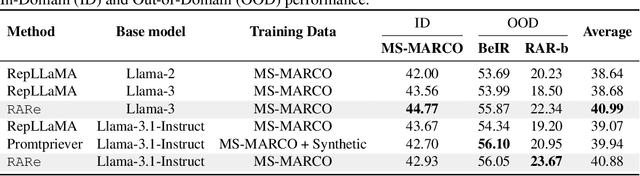
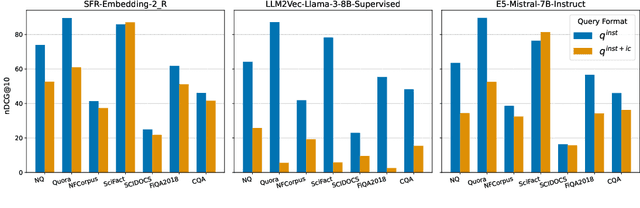
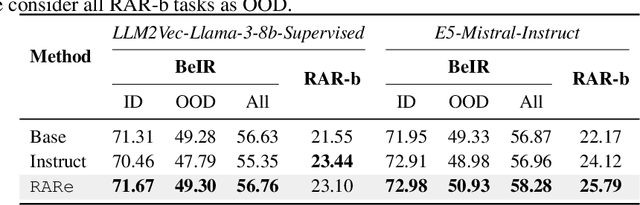
We investigate whether in-context examples, widely used in decoder-only language models (LLMs), can improve embedding model performance in retrieval tasks. Unlike in LLMs, naively prepending in-context examples (query-document pairs) to the target query at inference time does not work out of the box. We introduce a simple approach to enable retrievers to use in-context examples. Our approach, RARe, finetunes a pre-trained model with in-context examples whose query is semantically similar to the target query. This can be applied to adapt various base architectures (i.e., decoder-only language models, retriever models) and consistently achieves performance gains of up to +2.72% nDCG across various open-domain retrieval datasets (BeIR, RAR-b). In particular, we find RARe exhibits stronger out-of-domain generalization compared to models using queries without in-context examples, similar to what is seen for in-context learning in LLMs. We further provide analysis on the design choices of in-context example augmentation and lay the foundation for future work in this space.
Exploring Design Choices for Building Language-Specific LLMs
Jun 20, 2024Despite rapid progress in large language models (LLMs), their performance on a vast majority of languages remain unsatisfactory. In this paper, we study building language-specific LLMs by adapting monolingual and multilingual LLMs. We conduct systematic experiments on how design choices (base model selection, vocabulary extension, and continued fine-tuning) impact the adapted LLM, both in terms of efficiency (how many tokens are needed to encode the same amount of information) and end task performance. We find that (1) the initial performance before the adaptation is not always indicative of the final performance. (2) Efficiency can easily improved with simple vocabulary extension and continued fine-tuning in most LLMs we study, and (3) The optimal adaptation method is highly language-dependent, and the simplest approach works well across various experimental settings. Adapting English-centric models can yield better results than adapting multilingual models despite their worse initial performance on low-resource languages. Together, our work lays foundations on efficiently building language-specific LLMs by adapting existing LLMs.
SVFT: Parameter-Efficient Fine-Tuning with Singular Vectors
May 30, 2024



Popular parameter-efficient fine-tuning (PEFT) methods, such as LoRA and its variants, freeze pre-trained model weights \(W\) and inject learnable matrices \(\Delta W\). These \(\Delta W\) matrices are structured for efficient parameterization, often using techniques like low-rank approximations or scaling vectors. However, these methods typically show a performance gap compared to full fine-tuning. Although recent PEFT methods have narrowed this gap, they do so at the cost of additional learnable parameters. We propose SVFT, a simple approach that fundamentally differs from existing methods: the structure imposed on \(\Delta W\) depends on the specific weight matrix \(W\). Specifically, SVFT updates \(W\) as a sparse combination of outer products of its singular vectors, training only the coefficients (scales) of these sparse combinations. This approach allows fine-grained control over expressivity through the number of coefficients. Extensive experiments on language and vision benchmarks show that SVFT recovers up to 96% of full fine-tuning performance while training only 0.006 to 0.25% of parameters, outperforming existing methods that only recover up to 85% performance using 0.03 to 0.8% of the trainable parameter budget.