 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKurTail : Kurtosis-based LLM Quantization
Mar 03, 2025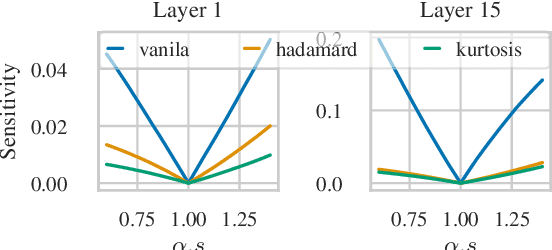
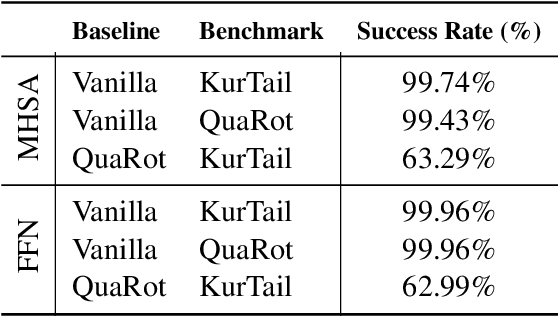
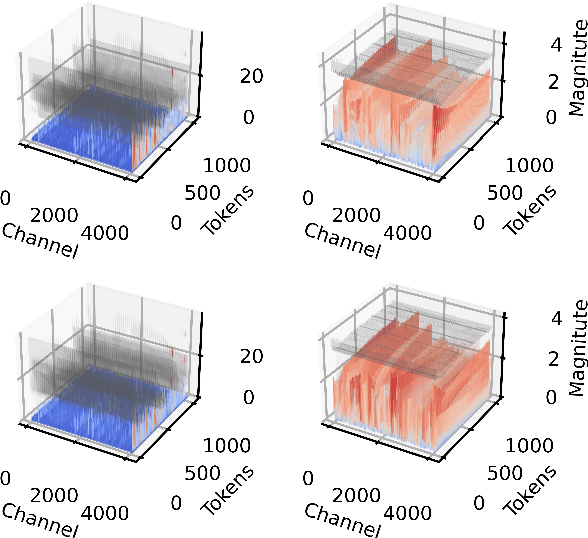
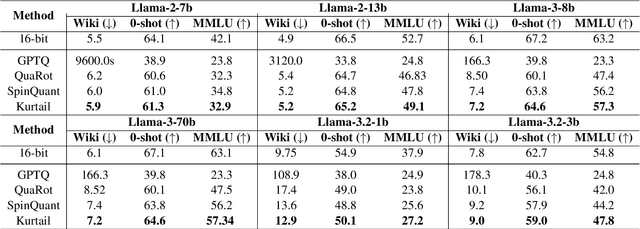
One of the challenges of quantizing a large language model (LLM) is the presence of outliers. Outliers often make uniform quantization schemes less effective, particularly in extreme cases such as 4-bit quantization. We introduce KurTail, a new post-training quantization (PTQ) scheme that leverages Kurtosis-based rotation to mitigate outliers in the activations of LLMs. Our method optimizes Kurtosis as a measure of tailedness. This approach enables the quantization of weights, activations, and the KV cache in 4 bits. We utilize layer-wise optimization, ensuring memory efficiency. KurTail outperforms existing quantization methods, offering a 13.3\% boost in MMLU accuracy and a 15.5\% drop in Wiki perplexity compared to QuaRot. It also outperforms SpinQuant with a 2.6\% MMLU gain and reduces perplexity by 2.9\%, all while reducing the training cost. For comparison, learning the rotation using SpinQuant for Llama3-70B requires at least four NVIDIA H100 80GB GPUs, whereas our method requires only a single GPU, making it a more accessible solution for consumer GPU.
Robust Yet Efficient Conformal Prediction Sets
Jul 12, 2024



Conformal prediction (CP) can convert any model's output into prediction sets guaranteed to include the true label with any user-specified probability. However, same as the model itself, CP is vulnerable to adversarial test examples (evasion) and perturbed calibration data (poisoning). We derive provably robust sets by bounding the worst-case change in conformity scores. Our tighter bounds lead to more efficient sets. We cover both continuous and discrete (sparse) data and our guarantees work both for evasion and poisoning attacks (on both features and labels).
Probing Graph Representations
Mar 07, 2023



Today we have a good theoretical understanding of the representational power of Graph Neural Networks (GNNs). For example, their limitations have been characterized in relation to a hierarchy of Weisfeiler-Lehman (WL) isomorphism tests. However, we do not know what is encoded in the learned representations. This is our main question. We answer it using a probing framework to quantify the amount of meaningful information captured in graph representations. Our findings on molecular datasets show the potential of probing for understanding the inductive biases of graph-based models. We compare different families of models and show that transformer-based models capture more chemically relevant information compared to models based on message passing. We also study the effect of different design choices such as skip connections and virtual nodes. We advocate for probing as a useful diagnostic tool for evaluating graph-based models.
Evaluating Sparse Interpretable Word Embeddings for Biomedical Domain
May 11, 2020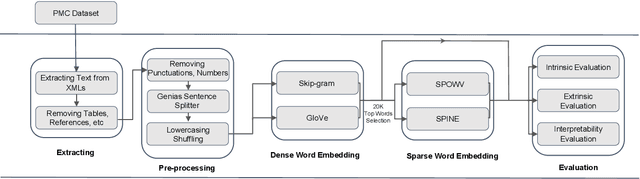
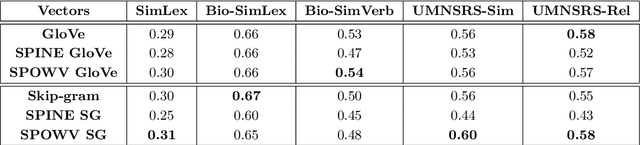
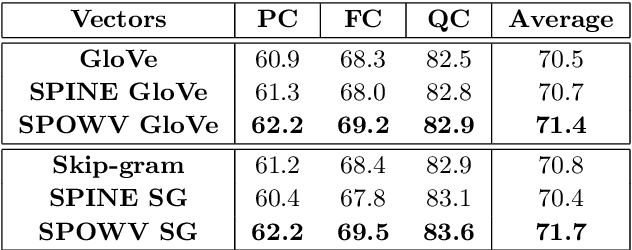
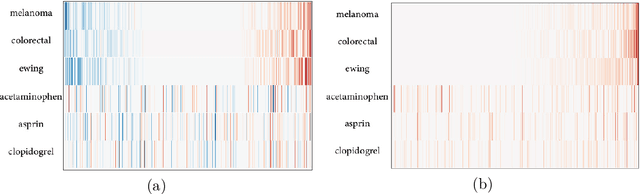
Word embeddings have found their way into a wide range of natural language processing tasks including those in the biomedical domain. While these vector representations successfully capture semantic and syntactic word relations, hidden patterns and trends in the data, they fail to offer interpretability. Interpretability is a key means to justification which is an integral part when it comes to biomedical applications. We present an inclusive study on interpretability of word embeddings in the medical domain, focusing on the role of sparse methods. Qualitative and quantitative measurements and metrics for interpretability of word vector representations are provided. For the quantitative evaluation, we introduce an extensive categorized dataset that can be used to quantify interpretability based on category theory. Intrinsic and extrinsic evaluation of the studied methods are also presented. As for the latter, we propose datasets which can be utilized for effective extrinsic evaluation of word vectors in the biomedical domain. Based on our experiments, it is seen that sparse word vectors show far more interpretability while preserving the performance of their original vectors in downstream tasks.
On Detecting Hidden Third-Party Web Trackers with a Wide Dependency Chain Graph: A Representation Learning Approach
Apr 29, 2020
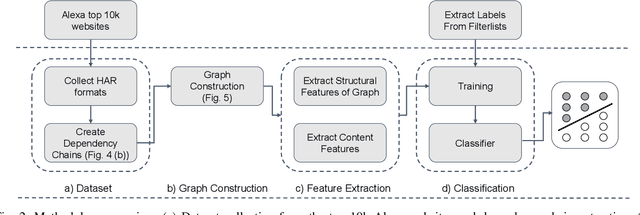

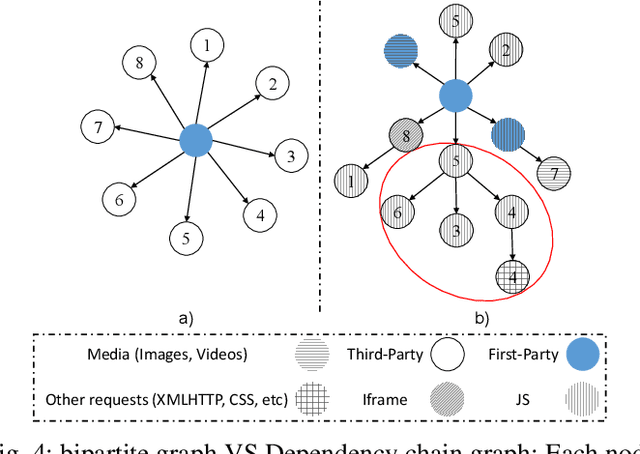
Websites use third-party ads and tracking services to deliver targeted ads and collect information about users that visit them. These services put users privacy at risk and that's why users demand to block these services is growing. Most of the blocking solutions rely on crowd-sourced filter lists that are built and maintained manually by a large community of users. In this work, we seek to simplify the update of these filter lists by automatic detection of hidden advertisements. Existing tracker detection approaches generally focus on each individual website's URL patterns, code structure and/or DOM structure of website. Our work differs from existing approaches by combining different websites through a large scale graph connecting all resource requests made over a large set of sites. This graph is thereafter used to train a machine learning model, through graph representation learning to detect ads and tracking resources. As our approach combines different sources of information, it is more robust toward evasion techniques that use obfuscation or change usage patterns. We evaluate our work over the Alexa top-10K websites, and find its accuracy to be 90.9% also it can block new ads and tracking services which would necessitate to be blocked further crowd-sourced existing filter lists. Moreover, the approach followed in this paper sheds light on the ecosystem of third party tracking and advertising