 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedVQA-TREE: A Multimodal Reasoning and Retrieval Framework for Sarcopenia Prediction
Aug 26, 2025



Accurate sarcopenia diagnosis via ultrasound remains challenging due to subtle imaging cues, limited labeled data, and the absence of clinical context in most models. We propose MedVQA-TREE, a multimodal framework that integrates a hierarchical image interpretation module, a gated feature-level fusion mechanism, and a novel multi-hop, multi-query retrieval strategy. The vision module includes anatomical classification, region segmentation, and graph-based spatial reasoning to capture coarse, mid-level, and fine-grained structures. A gated fusion mechanism selectively integrates visual features with textual queries, while clinical knowledge is retrieved through a UMLS-guided pipeline accessing PubMed and a sarcopenia-specific external knowledge base. MedVQA-TREE was trained and evaluated on two public MedVQA datasets (VQA-RAD and PathVQA) and a custom sarcopenia ultrasound dataset. The model achieved up to 99% diagnostic accuracy and outperformed previous state-of-the-art methods by over 10%. These results underscore the benefit of combining structured visual understanding with guided knowledge retrieval for effective AI-assisted diagnosis in sarcopenia.
Modeling the Hallucinating Brain: A Generative Adversarial Framework
Feb 09, 2021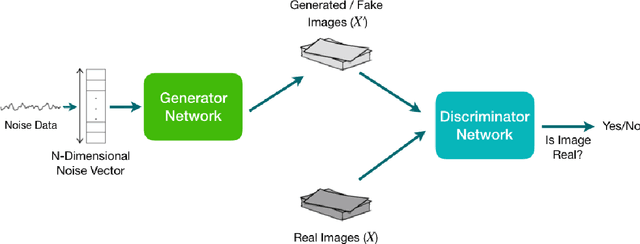
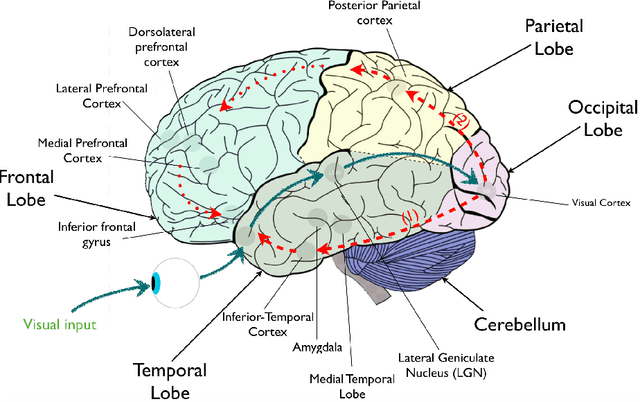
This paper looks into the modeling of hallucination in the human's brain. Hallucinations are known to be causally associated with some malfunctions within the interaction of different areas of the brain involved in perception. Focusing on visual hallucination and its underlying causes, we identify an adversarial mechanism between different parts of the brain which are responsible in the process of visual perception. We then show how the characterized adversarial interactions in the brain can be modeled by a generative adversarial network.
Evaluating Sparse Interpretable Word Embeddings for Biomedical Domain
May 11, 2020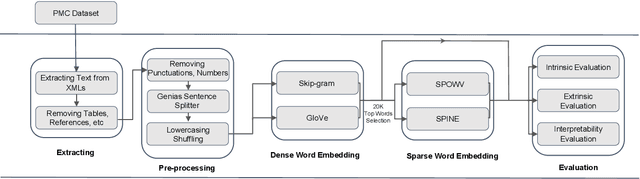
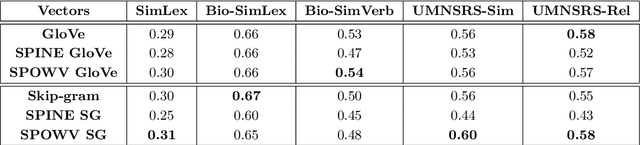
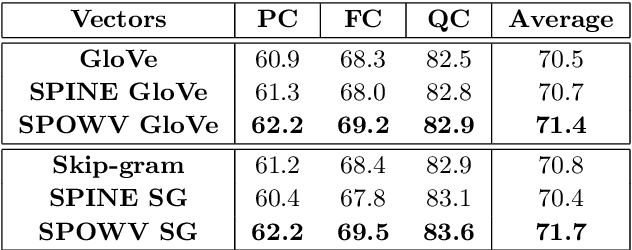
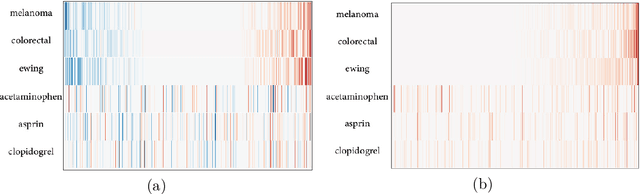
Word embeddings have found their way into a wide range of natural language processing tasks including those in the biomedical domain. While these vector representations successfully capture semantic and syntactic word relations, hidden patterns and trends in the data, they fail to offer interpretability. Interpretability is a key means to justification which is an integral part when it comes to biomedical applications. We present an inclusive study on interpretability of word embeddings in the medical domain, focusing on the role of sparse methods. Qualitative and quantitative measurements and metrics for interpretability of word vector representations are provided. For the quantitative evaluation, we introduce an extensive categorized dataset that can be used to quantify interpretability based on category theory. Intrinsic and extrinsic evaluation of the studied methods are also presented. As for the latter, we propose datasets which can be utilized for effective extrinsic evaluation of word vectors in the biomedical domain. Based on our experiments, it is seen that sparse word vectors show far more interpretability while preserving the performance of their original vectors in downstream tasks.