 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Sparse Interpretable Word Embeddings for Biomedical Domain
May 11, 2020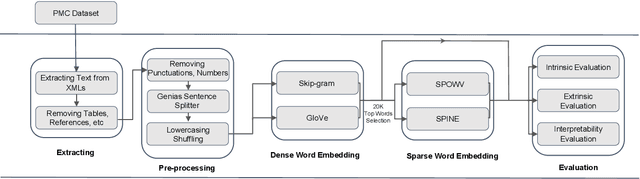
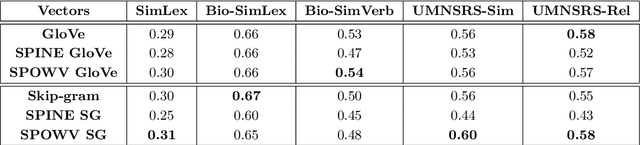
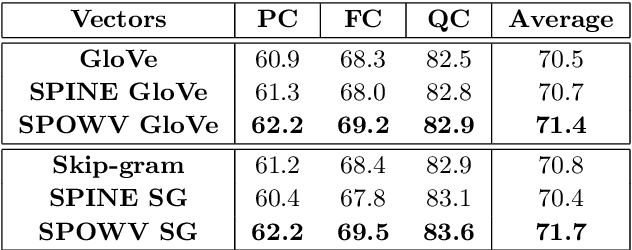
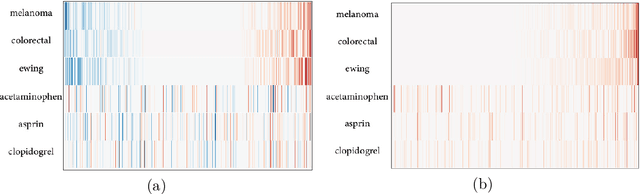
Word embeddings have found their way into a wide range of natural language processing tasks including those in the biomedical domain. While these vector representations successfully capture semantic and syntactic word relations, hidden patterns and trends in the data, they fail to offer interpretability. Interpretability is a key means to justification which is an integral part when it comes to biomedical applications. We present an inclusive study on interpretability of word embeddings in the medical domain, focusing on the role of sparse methods. Qualitative and quantitative measurements and metrics for interpretability of word vector representations are provided. For the quantitative evaluation, we introduce an extensive categorized dataset that can be used to quantify interpretability based on category theory. Intrinsic and extrinsic evaluation of the studied methods are also presented. As for the latter, we propose datasets which can be utilized for effective extrinsic evaluation of word vectors in the biomedical domain. Based on our experiments, it is seen that sparse word vectors show far more interpretability while preserving the performance of their original vectors in downstream tasks.