 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Epistemic Predictive Uncertainty in Conformal Prediction
Feb 02, 2026We study the problem of quantifying epistemic predictive uncertainty (EPU) -- that is, uncertainty faced at prediction time due to the existence of multiple plausible predictive models -- within the framework of conformal prediction (CP). To expose the implicit model multiplicity underlying CP, we build on recent results showing that, under a mild assumption, any full CP procedure induces a set of closed and convex predictive distributions, commonly referred to as a credal set. Importantly, the conformal prediction region (CPR) coincides exactly with the set of labels to which all distributions in the induced credal set assign probability at least $1-α$. As our first contribution, we prove that this characterisation also holds in split CP. Building on this connection, we then propose a computationally efficient and analytically tractable uncertainty measure, based on \emph{Maximum Mean Imprecision}, to quantify the EPU by measuring the degree of conflicting information within the induced credal set. Experiments on active learning and selective classification demonstrate that the quantified EPU provides substantially more informative and fine-grained uncertainty assessments than reliance on CPR size alone. More broadly, this work highlights the potential of CP serving as a principled basis for decision-making under epistemic uncertainty.
Optimal Conformal Prediction under Epistemic Uncertainty
May 25, 2025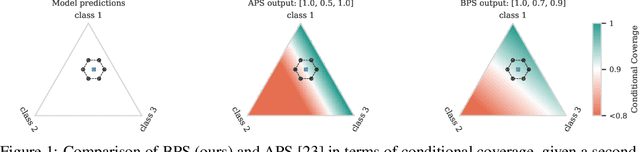

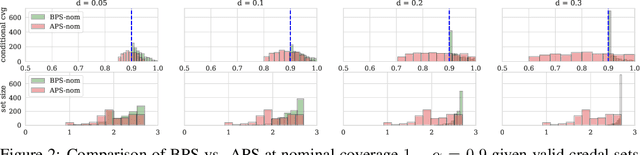
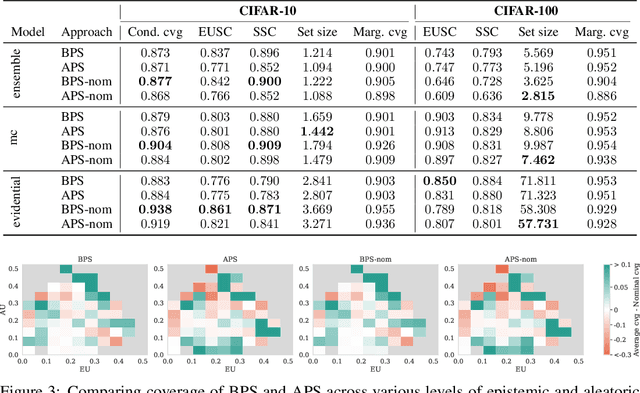
Conformal prediction (CP) is a popular frequentist framework for representing uncertainty by providing prediction sets that guarantee coverage of the true label with a user-adjustable probability. In most applications, CP operates on confidence scores coming from a standard (first-order) probabilistic predictor (e.g., softmax outputs). Second-order predictors, such as credal set predictors or Bayesian models, are also widely used for uncertainty quantification and are known for their ability to represent both aleatoric and epistemic uncertainty. Despite their popularity, there is still an open question on ``how they can be incorporated into CP''. In this paper, we discuss the desiderata for CP when valid second-order predictions are available. We then introduce Bernoulli prediction sets (BPS), which produce the smallest prediction sets that ensure conditional coverage in this setting. When given first-order predictions, BPS reduces to the well-known adaptive prediction sets (APS). Furthermore, when the validity assumption on the second-order predictions is compromised, we apply conformal risk control to obtain a marginal coverage guarantee while still accounting for epistemic uncertainty.
Robust Conformal Prediction with a Single Binary Certificate
Mar 07, 2025Conformal prediction (CP) converts any model's output to prediction sets with a guarantee to cover the true label with (adjustable) high probability. Robust CP extends this guarantee to worst-case (adversarial) inputs. Existing baselines achieve robustness by bounding randomly smoothed conformity scores. In practice, they need expensive Monte-Carlo (MC) sampling (e.g. $\sim10^4$ samples per point) to maintain an acceptable set size. We propose a robust conformal prediction that produces smaller sets even with significantly lower MC samples (e.g. 150 for CIFAR10). Our approach binarizes samples with an adjustable (or automatically adjusted) threshold selected to preserve the coverage guarantee. Remarkably, we prove that robustness can be achieved by computing only one binary certificate, unlike previous methods that certify each calibration (or test) point. Thus, our method is faster and returns smaller robust sets. We also eliminate a previous limitation that requires a bounded score function.
Robust Yet Efficient Conformal Prediction Sets
Jul 12, 2024



Conformal prediction (CP) can convert any model's output into prediction sets guaranteed to include the true label with any user-specified probability. However, same as the model itself, CP is vulnerable to adversarial test examples (evasion) and perturbed calibration data (poisoning). We derive provably robust sets by bounding the worst-case change in conformity scores. Our tighter bounds lead to more efficient sets. We cover both continuous and discrete (sparse) data and our guarantees work both for evasion and poisoning attacks (on both features and labels).
Conformal Inductive Graph Neural Networks
Jul 12, 2024Conformal prediction (CP) transforms any model's output into prediction sets guaranteed to include (cover) the true label. CP requires exchangeability, a relaxation of the i.i.d. assumption, to obtain a valid distribution-free coverage guarantee. This makes it directly applicable to transductive node-classification. However, conventional CP cannot be applied in inductive settings due to the implicit shift in the (calibration) scores caused by message passing with the new nodes. We fix this issue for both cases of node and edge-exchangeable graphs, recovering the standard coverage guarantee without sacrificing statistical efficiency. We further prove that the guarantee holds independently of the prediction time, e.g. upon arrival of a new node/edge or at any subsequent moment.