 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsights from the ICLR Peer Review and Rebuttal Process
Nov 19, 2025Peer review is a cornerstone of scientific publishing, including at premier machine learning conferences such as ICLR. As submission volumes increase, understanding the nature and dynamics of the review process is crucial for improving its efficiency, effectiveness, and the quality of published papers. We present a large-scale analysis of the ICLR 2024 and 2025 peer review processes, focusing on before- and after-rebuttal scores and reviewer-author interactions. We examine review scores, author-reviewer engagement, temporal patterns in review submissions, and co-reviewer influence effects. Combining quantitative analyses with LLM-based categorization of review texts and rebuttal discussions, we identify common strengths and weaknesses for each rating group, as well as trends in rebuttal strategies that are most strongly associated with score changes. Our findings show that initial scores and the ratings of co-reviewers are the strongest predictors of score changes during the rebuttal, pointing to a degree of reviewer influence. Rebuttals play a valuable role in improving outcomes for borderline papers, where thoughtful author responses can meaningfully shift reviewer perspectives. More broadly, our study offers evidence-based insights to improve the peer review process, guiding authors on effective rebuttal strategies and helping the community design fairer and more efficient review processes. Our code and score changes data are available at https://github.com/papercopilot/iclr-insights.
FineWeb2: One Pipeline to Scale Them All -- Adapting Pre-Training Data Processing to Every Language
Jun 26, 2025Pre-training state-of-the-art large language models (LLMs) requires vast amounts of clean and diverse text data. While the open development of large high-quality English pre-training datasets has seen substantial recent progress, training performant multilingual LLMs remains a challenge, in large part due to the inherent difficulty of tailoring filtering and deduplication pipelines to a large number of languages. In this work, we introduce a new pre-training dataset curation pipeline based on FineWeb that can be automatically adapted to support any language. We extensively ablate our pipeline design choices on a set of nine diverse languages, guided by a set of meaningful and informative evaluation tasks that were chosen through a novel selection process based on measurable criteria. Ultimately, we show that our pipeline can be used to create non-English corpora that produce more performant models than prior datasets. We additionally introduce a straightforward and principled approach to rebalance datasets that takes into consideration both duplication count and quality, providing an additional performance uplift. Finally, we scale our pipeline to over 1000 languages using almost 100 Common Crawl snapshots to produce FineWeb2, a new 20 terabyte (5 billion document) multilingual dataset which we release along with our pipeline, training, and evaluation codebases.
Tracing Multilingual Factual Knowledge Acquisition in Pretraining
May 20, 2025Large Language Models (LLMs) are capable of recalling multilingual factual knowledge present in their pretraining data. However, most studies evaluate only the final model, leaving the development of factual recall and crosslingual consistency throughout pretraining largely unexplored. In this work, we trace how factual recall and crosslingual consistency evolve during pretraining, focusing on OLMo-7B as a case study. We find that both accuracy and consistency improve over time for most languages. We show that this improvement is primarily driven by the fact frequency in the pretraining corpus: more frequent facts are more likely to be recalled correctly, regardless of language. Yet, some low-frequency facts in non-English languages can still be correctly recalled. Our analysis reveals that these instances largely benefit from crosslingual transfer of their English counterparts -- an effect that emerges predominantly in the early stages of pretraining. We pinpoint two distinct pathways through which multilingual factual knowledge acquisition occurs: (1) frequency-driven learning, which is dominant and language-agnostic, and (2) crosslingual transfer, which is limited in scale and typically constrained to relation types involving named entities. We release our code and data to facilitate further research at https://github.com/cisnlp/multilingual-fact-tracing.
On Relation-Specific Neurons in Large Language Models
Feb 24, 2025In large language models (LLMs), certain neurons can store distinct pieces of knowledge learned during pretraining. While knowledge typically appears as a combination of relations and entities, it remains unclear whether some neurons focus on a relation itself -- independent of any entity. We hypothesize such neurons detect a relation in the input text and guide generation involving such a relation. To investigate this, we study the Llama-2 family on a chosen set of relations with a statistics-based method. Our experiments demonstrate the existence of relation-specific neurons. We measure the effect of selectively deactivating candidate neurons specific to relation $r$ on the LLM's ability to handle (1) facts whose relation is $r$ and (2) facts whose relation is a different relation $r' \neq r$. With respect to their capacity for encoding relation information, we give evidence for the following three properties of relation-specific neurons. $\textbf{(i) Neuron cumulativity.}$ The neurons for $r$ present a cumulative effect so that deactivating a larger portion of them results in the degradation of more facts in $r$. $\textbf{(ii) Neuron versatility.}$ Neurons can be shared across multiple closely related as well as less related relations. Some relation neurons transfer across languages. $\textbf{(iii) Neuron interference.}$ Deactivating neurons specific to one relation can improve LLM generation performance for facts of other relations. We will make our code publicly available at https://github.com/cisnlp/relation-specific-neurons.
GlotCC: An Open Broad-Coverage CommonCrawl Corpus and Pipeline for Minority Languages
Oct 31, 2024



The need for large text corpora has increased with the advent of pretrained language models and, in particular, the discovery of scaling laws for these models. Most available corpora have sufficient data only for languages with large dominant communities. However, there is no corpus available that (i) covers a wide range of minority languages; (ii) is generated by an open-source reproducible pipeline; and (iii) is rigorously cleaned from noise, making it trustworthy to use. We present GlotCC, a clean, document-level, 2TB general domain corpus derived from CommonCrawl, covering more than 1000 languages. We make GlotCC and the system used to generate it - including the pipeline, language identification model, and filters - available to the research community. Corpus v. 1.0 https://huggingface.co/datasets/cis-lmu/GlotCC-v1, Pipeline v. 3.0 https://github.com/cisnlp/GlotCC.
MEXA: Multilingual Evaluation of English-Centric LLMs via Cross-Lingual Alignment
Oct 08, 2024English-centric large language models (LLMs) often show strong multilingual capabilities. However, the multilingual performance of these models remains unclear and is not thoroughly evaluated for many languages. Most benchmarks for multilinguality focus on classic NLP tasks, or cover a minimal number of languages. We introduce MEXA, a method for assessing the multilingual capabilities of pre-trained English-centric LLMs using parallel sentences, which are available for more languages than existing downstream tasks. MEXA leverages the fact that English-centric LLMs use English as a kind of pivot language in their intermediate layers. It computes the alignment between English and non-English languages using parallel sentences to evaluate the transfer of language understanding from English to other languages. This alignment can be used to estimate model performance in other languages. We conduct studies using various parallel datasets (FLORES-200 and Bible), models (Llama family, Gemma family, Mistral, and OLMo), and established downstream tasks (Belebele, m-MMLU, and m-ARC). We explore different methods to compute embeddings in decoder-only models. Our results show that MEXA, in its default settings, achieves a statistically significant average Pearson correlation of 0.90 with three established downstream tasks across nine models and two parallel datasets. This suggests that MEXA is a reliable method for estimating the multilingual capabilities of English-centric LLMs, providing a clearer understanding of their multilingual potential and the inner workings of LLMs. Leaderboard: https://huggingface.co/spaces/cis-lmu/Mexa, Code: https://github.com/cisnlp/Mexa.
How Transliterations Improve Crosslingual Alignment
Sep 25, 2024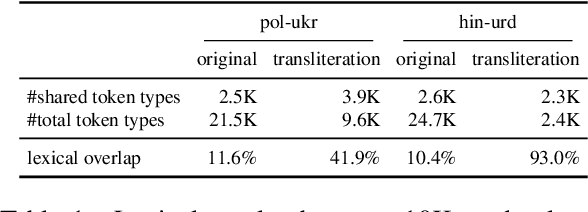

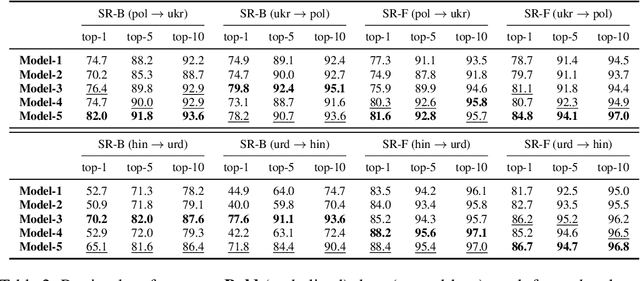

Recent studies have shown that post-aligning multilingual pretrained language models (mPLMs) using alignment objectives on both original and transliterated data can improve crosslingual alignment. This improvement further leads to better crosslingual transfer performance. However, it remains unclear how and why a better crosslingual alignment is achieved, as this technique only involves transliterations, and does not use any parallel data. This paper attempts to explicitly evaluate the crosslingual alignment and identify the key elements in transliteration-based approaches that contribute to better performance. For this, we train multiple models under varying setups for two pairs of related languages: (1) Polish and Ukrainian and (2) Hindi and Urdu. To assess alignment, we define four types of similarities based on sentence representations. Our experiments show that adding transliterations alone improves the overall similarities, even for random sentence pairs. With the help of auxiliary alignment objectives, especially the contrastive objective, the model learns to distinguish matched from random pairs, leading to better alignments. However, we also show that better alignment does not always yield better downstream performance, suggesting that further research is needed to clarify the connection between alignment and performance.
MaskLID: Code-Switching Language Identification through Iterative Masking
Jun 10, 2024We present MaskLID, a simple, yet effective, code-switching (CS) language identification (LID) method. MaskLID does not require any training and is designed to complement current high-performance sentence-level LIDs. Sentence-level LIDs are classifiers trained on monolingual texts to provide single labels, typically using a softmax layer to turn scores into probabilities. However, in cases where a sentence is composed in both L1 and L2 languages, the LID classifier often only returns the dominant label L1. To address this limitation, MaskLID employs a strategy to mask text features associated with L1, allowing the LID to classify the text as L2 in the next round. This method uses the LID itself to identify the features that require masking and does not rely on any external resource. In this work, we explore the use of MaskLID for two open-source LIDs (GlotLID and OpenLID), that are both based on the FastText architecture. Code and demo are available at https://github.com/cisnlp/MaskLID.
GIRT-Model: Automated Generation of Issue Report Templates
Feb 08, 2024
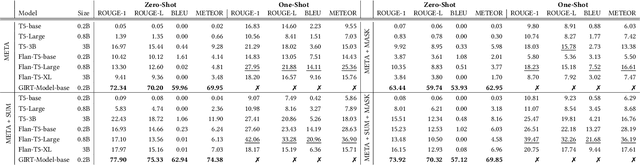
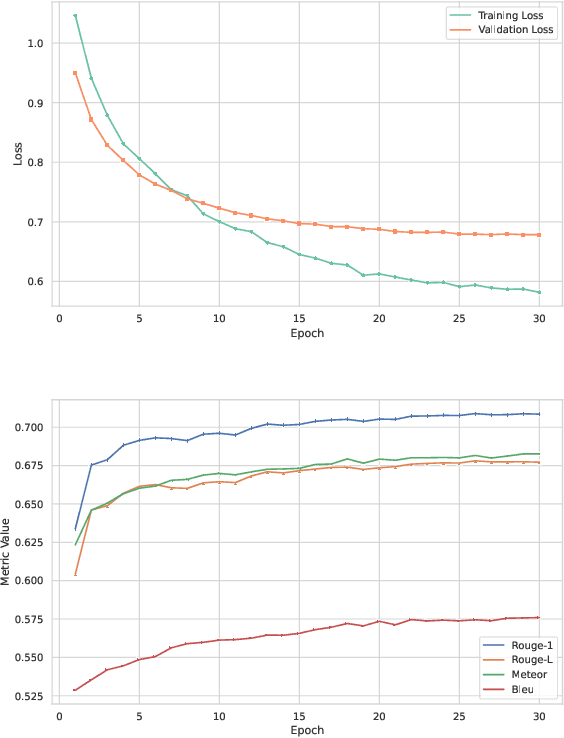
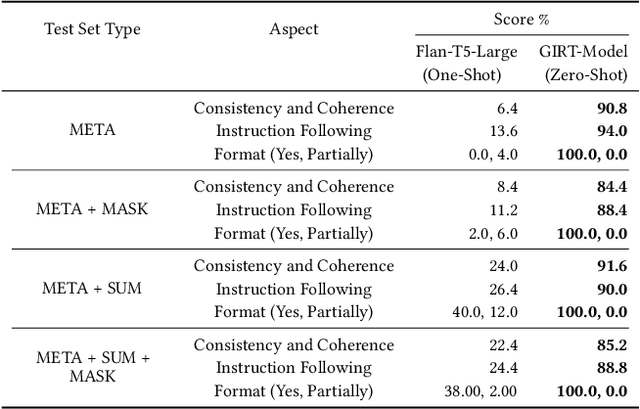
Platforms such as GitHub and GitLab introduce Issue Report Templates (IRTs) to enable more effective issue management and better alignment with developer expectations. However, these templates are not widely adopted in most repositories, and there is currently no tool available to aid developers in generating them. In this work, we introduce GIRT-Model, an assistant language model that automatically generates IRTs based on the developer's instructions regarding the structure and necessary fields. We create GIRT-Instruct, a dataset comprising pairs of instructions and IRTs, with the IRTs sourced from GitHub repositories. We use GIRT-Instruct to instruction-tune a T5-base model to create the GIRT-Model. In our experiments, GIRT-Model outperforms general language models (T5 and Flan-T5 with different parameter sizes) in IRT generation by achieving significantly higher scores in ROUGE, BLEU, METEOR, and human evaluation. Additionally, we analyze the effectiveness of GIRT-Model in a user study in which participants wrote short IRTs with GIRT-Model. Our results show that the participants find GIRT-Model useful in the automated generation of templates. We hope that through the use of GIRT-Model, we can encourage more developers to adopt IRTs in their repositories. We publicly release our code, dataset, and model at https://github.com/ISE-Research/girt-model.
GlotLID: Language Identification for Low-Resource Languages
Nov 04, 2023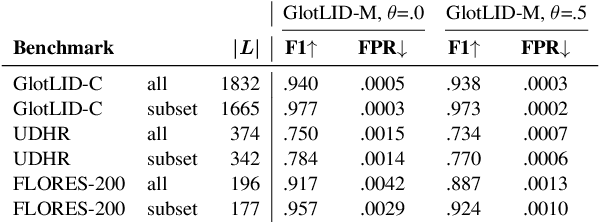



Several recent papers have published good solutions for language identification (LID) for about 300 high-resource and medium-resource languages. However, there is no LID available that (i) covers a wide range of low-resource languages, (ii) is rigorously evaluated and reliable and (iii) efficient and easy to use. Here, we publish GlotLID-M, an LID model that satisfies the desiderata of wide coverage, reliability and efficiency. It identifies 1665 languages, a large increase in coverage compared to prior work. In our experiments, GlotLID-M outperforms four baselines (CLD3, FT176, OpenLID and NLLB) when balancing F1 and false positive rate (FPR). We analyze the unique challenges that low-resource LID poses: incorrect corpus metadata, leakage from high-resource languages, difficulty separating closely related languages, handling of macrolanguage vs varieties and in general noisy data. We hope that integrating GlotLID-M into dataset creation pipelines will improve quality and enhance accessibility of NLP technology for low-resource languages and cultures. GlotLID-M model, code, and list of data sources are available: https://github.com/cisnlp/GlotLID.